
ARK Invest最新报告 :AI训练成本下降了100倍,但训练最先进AI模型的...

新智元报道
来源:venturebeat
编辑:雅新
【新智元导读】方舟投资的最新一项报告指出,AI训练成本从2017年至2019年下降了100倍,但人工智能发展尚处于初期阶段。该报告同时发现AI算法效率每16个月翻一番,与OpenAI的报告结果一致。
机器学习训练系统越来越便宜了。
方舟投资(ARK Invest)近日发布了一篇分析报告显示,AI训练成本的提高速度是摩尔定律(Moore’s law)的50倍。摩尔定律是指计算机硬件性能每两年提升一倍。两年间,AI训练成本下降了100倍
人工智能计算的复杂度自2010年以来每年飙升10倍(每秒千万亿次运算)。与此同时,过去三年的训练成本每年下降10倍。 2017年,在公共云上训练像 ResNet-50这样的图像分类器的成本约为1000美元,到了2019年只需大约10美元。 方舟评估委员会预测,按照目前的速度,到今年年底,其训练成本应降至1美元。
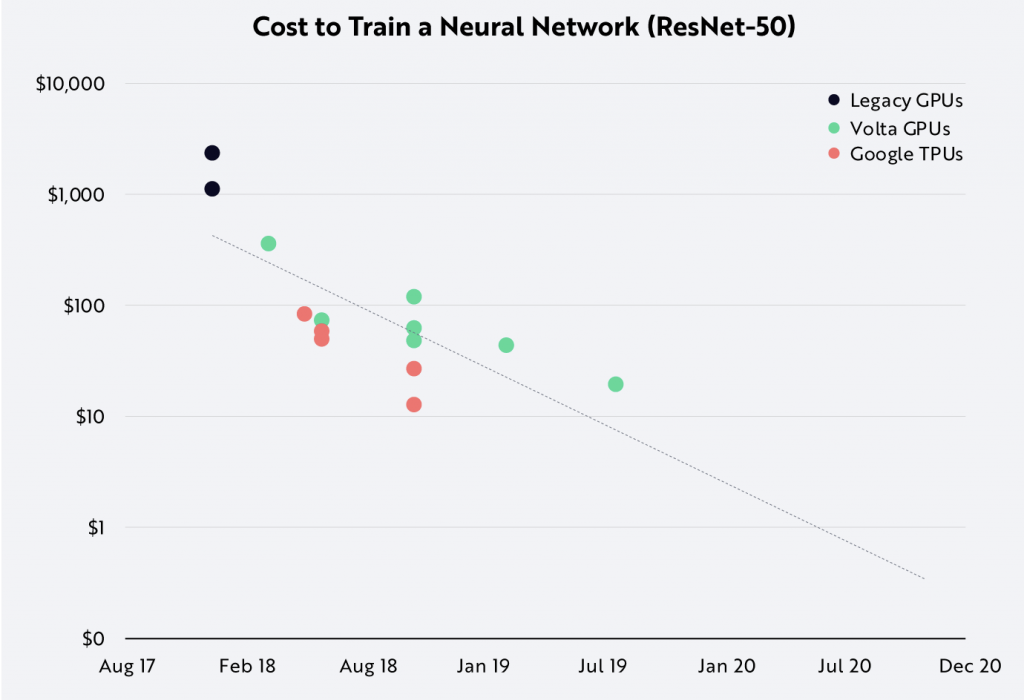
该公司预计,随着这一成本的下降,推理的成本(在生产过程中运行一个训练有素的模型)将会下降。 比如,在过去两年中,对十亿张图像进行分类的成本从10,000美元降至仅0.03美元。
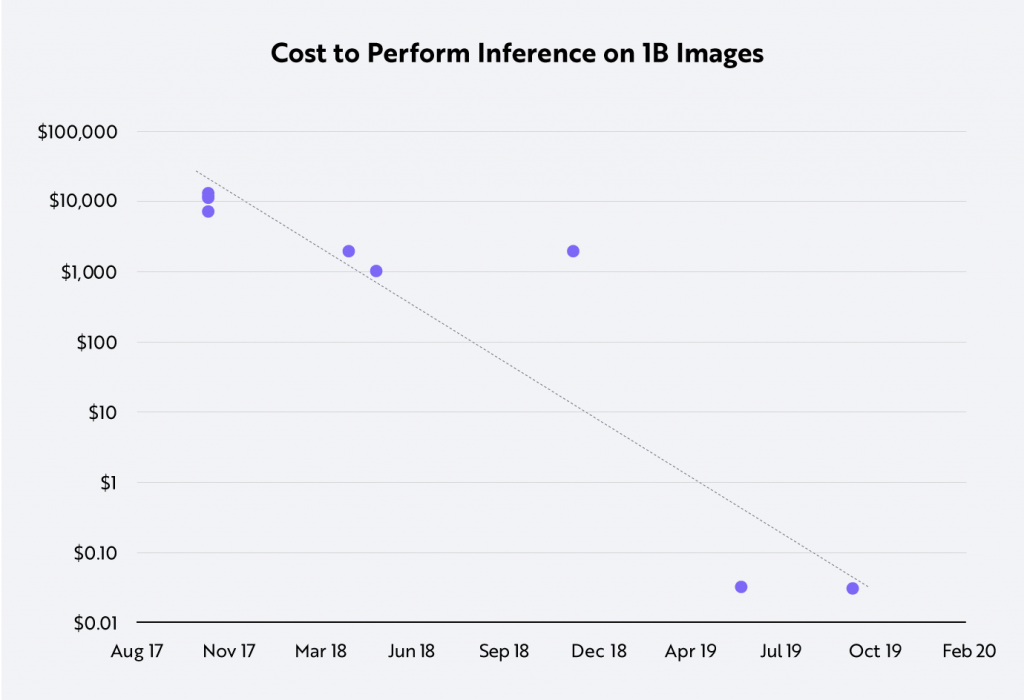
对于那些与像谷歌、 DeepMind 这样资金雄厚的公司进行竞争的初创公司来说,这无疑是天籁之音。
DeepMind 去年亏损5.72亿美元,且背负着超过10亿美元的债务。 尽管一些专家认为,科技巨头无可匹敌的实验室有能力从事新的研究,但训练成本也是AI工作中不可避免的开支,不论是在企业、学术界还是其他领域。
AI算法效率每16个月翻一番,与OpenAI报告结果一致
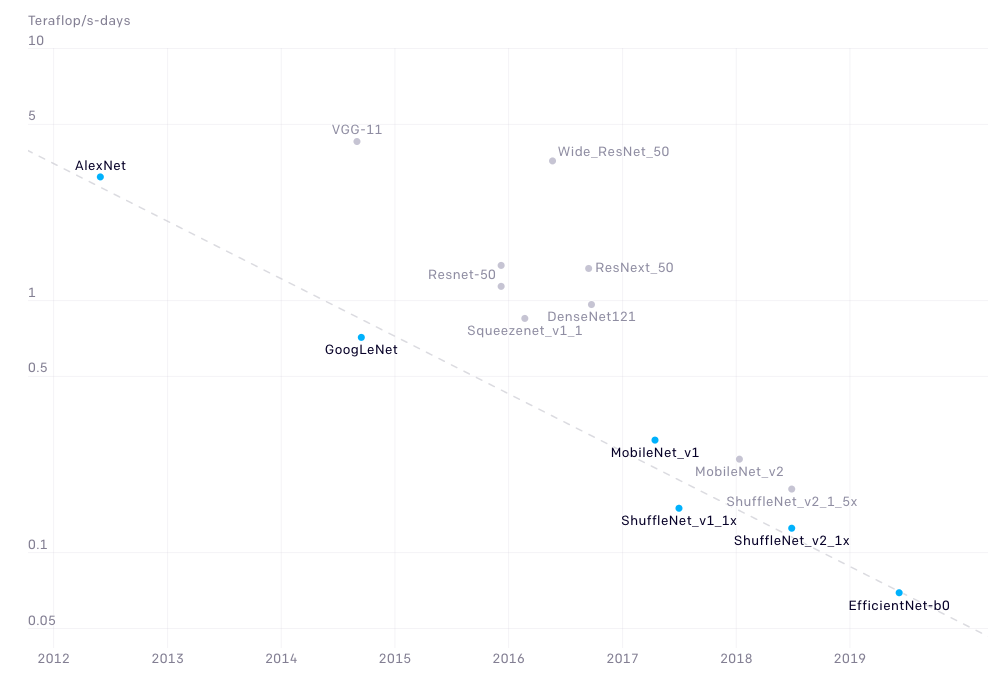
OpenAI观察到16个月AI模型的效率倍增时间(任意给定时间的最低计算点用蓝色表示,测量点用灰色表示)
据 OpenAI 介绍,它发现谷歌的 Transformer 架构超越了以前由谷歌开发的最先进模型——seq2seq,在seq2seq推出三年后,其计算量减少至原来的1/61。 谷歌的 Transformer 架构超越了之前的最先进模型—— seq2seq,后者也是谷歌开发的,在 seq2seq 推出三年后,计算能力下降了61倍。 Deepmind 的 AlphaZero 是一个从零开始自学如何掌握国际象棋、将棋和围棋游戏的系统。

仅仅一年后,DeepMind 的 AlphaZero 在围棋比赛中,其计算量比 AlphaGoZero 少 8 倍,就能与 AlphaGoZero 匹敌。
AI发展尚处于初期阶段,训练最先进AI模型的成本依然惊人
方舟投资报告指出, 硬件和软件的突破使得AI训练成本下降。
在2018年至2019年间,由于麻省理工学院、谷歌、 Facebook、微软、 IBM、 Uber 等公司的软件创新,V100的训练性能提高了大约800% 。
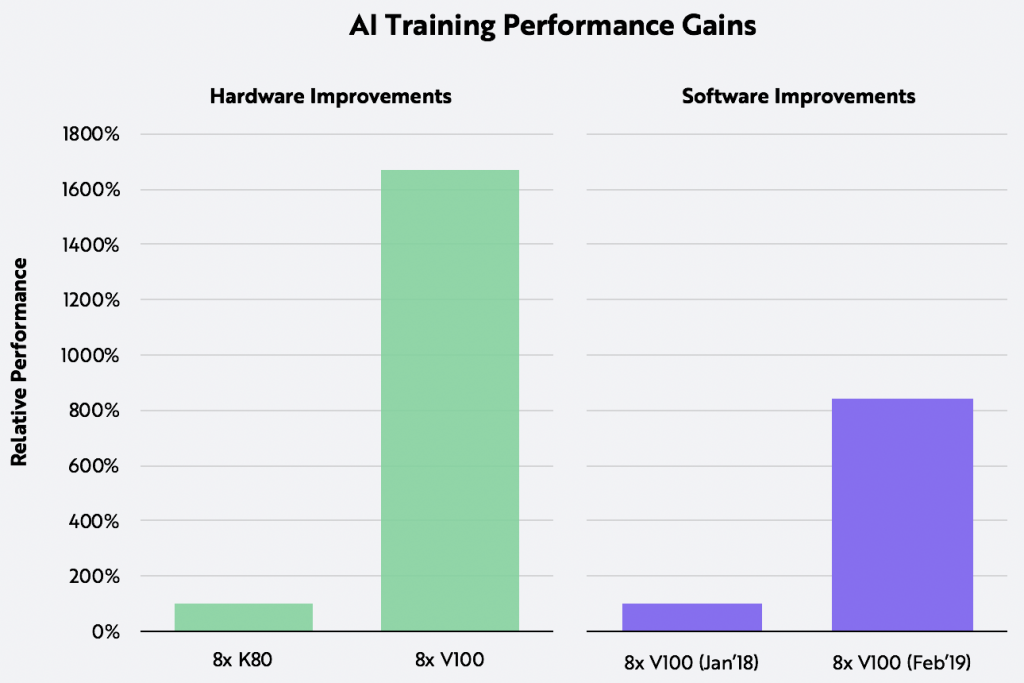
ARK 分析师 James Wang 写道,「从AI训练成本下降的速度来看,人工智能发展还处于初期。」 摩尔定律的第一个十年里,晶体管数量每年翻一番。
我们在人工智能训练和推断中看到从10倍到100倍的成本下降表明,人工智能的发展尚处于初级阶段,未来几十年可能会出现较慢但持续的增长。
值得注意的是,虽然AI模型训练的费用似乎在下降,但是在云中开发复杂ML模型仍然昂贵得让人望而却步。

根据 Synced 最近的一份报告,华盛顿大学的 Grover 专门用于生成和检测虚假新闻,训练最大的Grover Mega模型的总费用为2.5万美元。 OpenAI 花费了1200万美元来训练它的 GPT-3语言模型。 而谷歌花费了大约6912美元来训练 BERT,这是一种双向变换模型,它重新定义了11种自然语言处理任务的最新技术。 参考链接:
https://venturebeat.com/2020/06/04/ark-invest-ai-training-costs-dropped-100-fold-between-2017-and-2019/https://ark-invest.com/analyst-research/ai-training/
评论