
爬一爬国王排名的弹幕
自从上期的推送用了波吉的封面,浏览量大增。想起很久之前一个叫Nick的老哥跟我说,内容写的再好没用,封面得吸引人,你放点好看的美女图片,会增加很多点进去的人。这会儿觉得很有道理。(标题党,UC震惊体的威力)这期趁热打铁,一期一会,周更写起来。
看着国王排名的动画,弹幕齐刷刷的都是泪目,这期就写一篇技术文档,怎么抓取B站的弹幕。怎么制作词云图,怎么情感分析,放到后面再写。如果你python已经入门或者对爬虫有兴趣,就可以看下去。我们进入正题。
二话不说,先贴两个import。相信很多朋友都有这样的体验,学python,找对要用的库就成功了一半。你去一搜,就会发现,requests库在爬虫请求库中是最常用的。(完整的爬虫过程包括请求+解析+存储)这个库封装了urllib的一些方法,使用很方便。第二个库re是用来解析爬取出来的结果,做一些数据清洗的。import requestsimport re
第二步就是找网址了,明确要爬什么。这里以B站为例,打开B站,找到国王排名动画,第二集是王子与卡克,这次就爬这集。(一打开B站,然后就快乐的刷起剧和小姐姐的话,卒,爬虫教程到此结束)
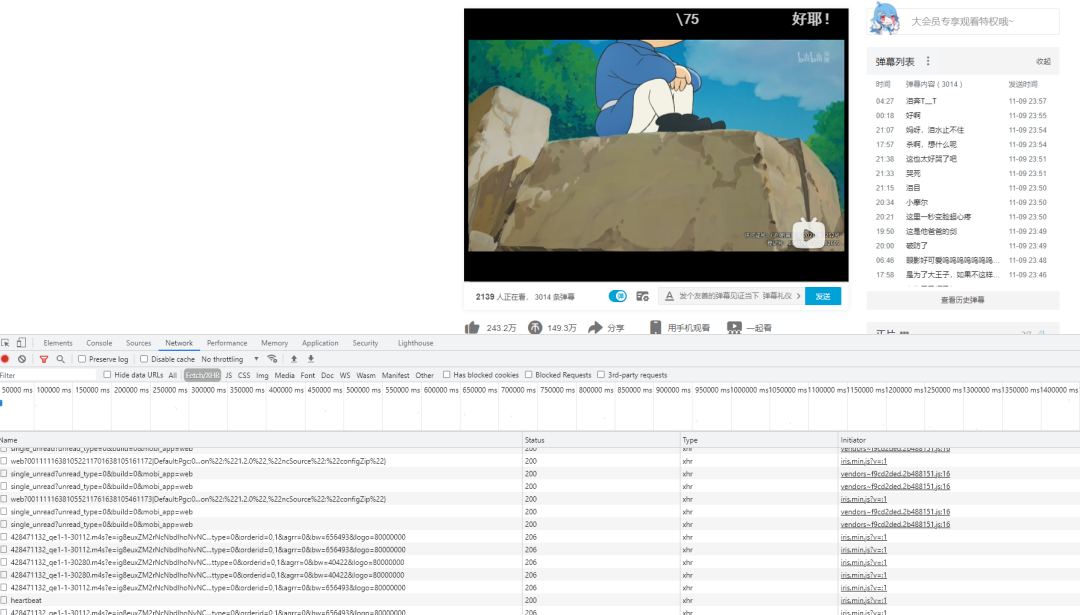
建议打开开发者模式,谷歌浏览器中按F12即可,选项卡中选到network网络这一项。补充一下,爬虫本质上就是模拟人访问网站的操作,然后获取感兴趣的内容,不需要人工一张一张保存,在找到规律后,程序代替你完成这个工作。谷歌的开发者模式对于爬虫非常有用。
虽然我们已经打开了动画页面,但是还需要找到弹幕在哪里。弹幕分两种,一种是实时弹幕,一种是历史弹幕。我们打开弹幕列表,翻到最下面,有一个历史弹幕。点击这个按钮的时候注意观察下方的调试窗口。(可以先清除掉历史的信息)
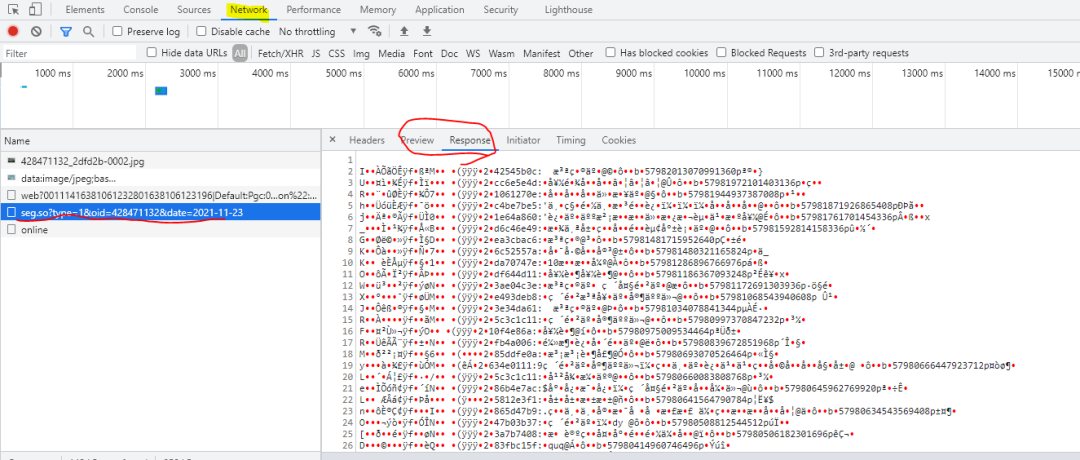
这一句就是爬虫请求的最低配版本(建议不要使用),方法是requests中的get,输入是网址。新手爬虫特别容易被封IP,因为浏览器一眼就识别了你这个是脚本,不是人在操作,那怎样和浏览器的操作更逼近呢?抄浏览器的请求。url = 'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=428471132&date=2021-11-23'response = requests.get(url=url)print(response.text)
{"code":-101,"message":"账号未登录","ttl":1}接下来我们加上请求头再试一次。
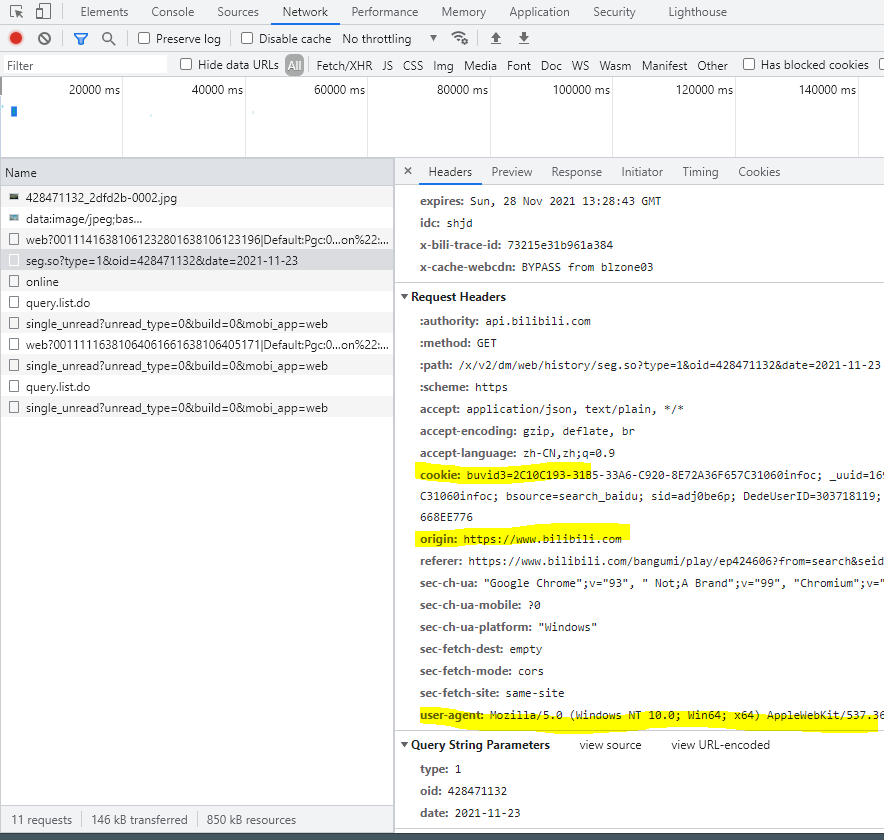
url = 'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=428471132&date=2021-11-23'headers = {'cookie':'','user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36','accept-encoding': 'gzip, deflate, br','accept-language': 'zh-CN,zh;q=0.9'}response = requests.get(url=url,headers= headers)print(response.text)
Cookie请带上自己的cookie,怎么自动请求这个cookie后续再详细介绍。# response.encoding = 'utf-8'这一句是想通过编码解决一些字符乱码问题,但是没有用,就注释掉了。print(response.text),打印出文本内容,还有一种方法是print(response.content),结果以16进制展示。如果你的cookie填写没问题的,这会儿已经可以看到有东西打印出来。
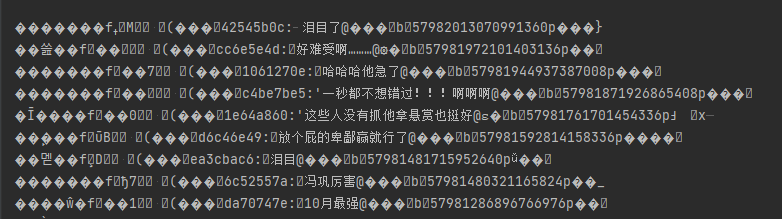
content_list = re.findall(':(.*?)@',response.text)for item in content_list:if ':' in item:item = item.split(':')[1]content = item[1:]with open('国王排名弹幕.txt',mode='a',encoding='utf-8') as f:print(content)f.write(content)f.write('\n')
第1行代码:观察弹幕可以看到,有效的内容都在:和@之间,所以将这一部分保留,其他的去掉,注意re.findall的用法。第3,4行代码:这一步筛选过后,大部分数据已经处理好了,有几行特殊的弹幕有2个":",多了一部分无用信息,针对这部分数据,再使用split处理。(也可以使用re.sub)第5行代码:因为在:后面还有一个多余的字符,所以我们去掉最开头的一个内容。第6-9行,就是把结果保存在一个text中,爬虫的数据存储阶段。
打开“国王排名弹幕.txt”文件,就可以看到国王排名11月23日的历史弹幕了。想要看其他日期的弹幕也一样,替换掉网址里的日期就可以。

附上全部代码,print为调试使用,可自行打开。
import requestsimport re#查找历史弹幕网站url = 'https://api.bilibili.com/x/v2/dm/web/history/seg.so?type=1&oid=428471132&date=2021-11-23'headers = {'cookie':'','user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36','accept-encoding': 'gzip, deflate, br','accept-language': 'zh-CN,zh;q=0.9'}response = requests.get(url=url,headers= headers)# response.encoding = 'utf-8'# print(response.text)#正则表达式提取出来的内容是个列表content_list = re.findall(':(.*?)@',response.text)# print(content_list)for item in content_list:if ':' in item:item = item.split(':')[1]content = item[1:]with open('国王排名弹幕.txt',mode='a',encoding='utf-8') as f:# print(content)f.write(content)f.write('\n')
不到30行代码实现了一个简单的功能。有了弹幕数据之后,可以做词云图,也可以做情感分析。且听下回分解。