
验证码的爬取和识别详解
今天要给大家介绍的是验证码的爬取和识别,不过只涉及到最简单的图形验证码,也是现在比较常见的一种类型。
运行平台:Windows
Python版本:Python3.6
IDE: Sublime Text
其他:Chrome浏览器

步骤1:简单介绍验证码
步骤2:爬取少量验证码图片
步骤3:介绍百度文字识别OCR
步骤4:识别爬取的验证码
步骤5:简单图像处理
目前,很多网站会采取各种各样的措施来反爬虫,验证码就是其中一种,比如当检测到访问频率过高时会弹出验证码让你输入,确认访问网站的不是机器人。但随着爬虫技术的发展,验证码的花样也越来越多,从最开始简单的几个数字或字母构成的图形验证码(也就是我们今天要涉及的)发展到需要点击倒立文字字母的、与文字相符合的图片的点触型验证码,需要滑动到合适位置的极验滑动验证码,以及计算题验证码等等,总之花样百出,让人头秃。验证码其他的相关知识大家可以看下这个网站:captcha.org
再来简单说下图形验证码吧,就像这张:

由字母和数字组成,再加上一些噪点,但为了防止被识别,简单的图形验证码现在也变得复杂,有的加了干扰线,有的加噪点,有的加上背景,字体扭曲、粘连、镂空、混用等等,甚至有时候人眼都难以识别,只能默默点击“看不清,再来一张”。
验证码难度的提高随之带来的就是识别的成本也需要提高,在接下来的识别过程中,我会先直接使用百度文字识别OCR,来测试识别准确度,再确认是否选择转灰度、二值化以及去干扰等图像操作优化识别率。
接下来我们就来爬取少量验证码图片存入文件。
首先打开Chrome浏览器,访问刚刚介绍的网站,里面有一个captcha图像样本链接:https://captcha.com/captcha-examples.html?cst=corg,网页里有60张不同类型的图形验证码,足够我们用来识别试验了。
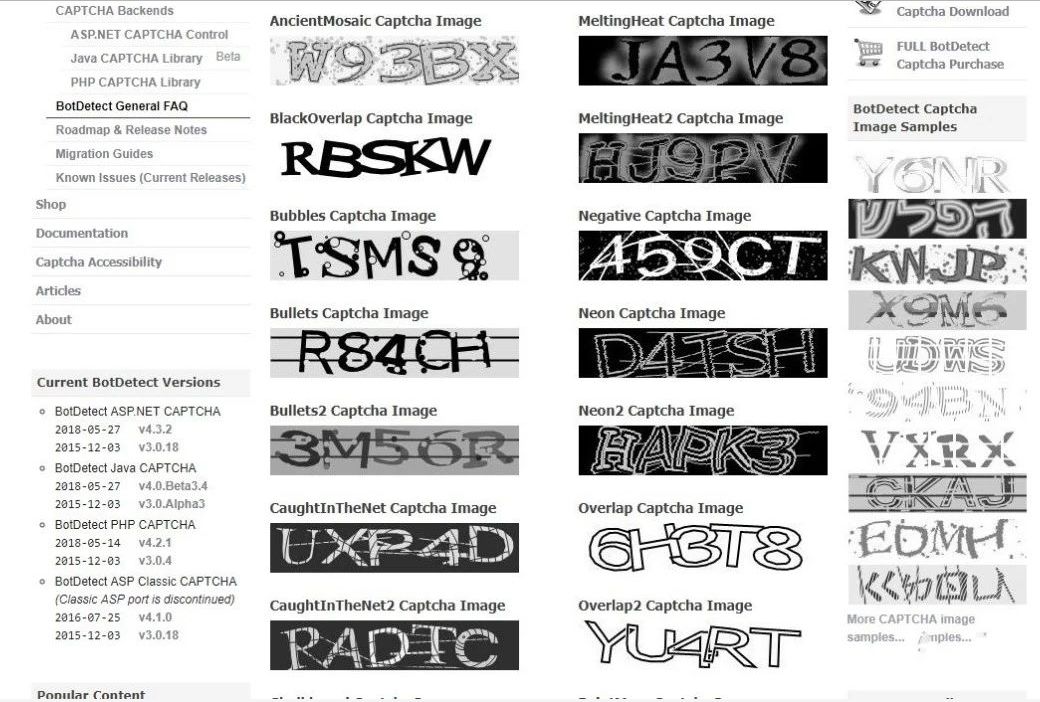
直接来看代码吧:
import requests
import os
import time
from lxml import etree
def get_Page(url,headers):
response = requests.get(url,headers=headers)
if response.status_code == 200:
# print(response.text)
return response.text
return None
def parse_Page(html,headers):
html_lxml = etree.HTML(html)
datas = html_lxml.xpath('.//div[@class="captcha_images_left"]|.//div[@class="captcha_images_right"]')
item= {}
# 创建保存验证码文件夹
file = 'D:/******'
if os.path.exists(file):
os.chdir(file)
else:
os.mkdir(file)
os.chdir(file)
for data in datas:
# 验证码名称
name = data.xpath('.//h3')
# print(len(name))
# 验证码链接
src = data.xpath('.//div/img/@src')
# print(len(src))
count = 0
for i in range(len(name)):
# 验证码图片文件名
filename = name[i].text + '.jpg'
img_url = 'https://captcha.com/' + src[i]
response = requests.get(img_url,headers=headers)
if response.status_code == 200:
image = response.content
with open(filename,'wb') as f:
f.write(image)
count += 1
print('保存第{}张验证码成功'.format(count))
time.sleep(1)
def main():
url = 'https://captcha.com/captcha-examples.html?cst=corg'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'}
html = get_Page(url,headers)
parse_Page(html,headers)
if __name__ == '__main__':
main()
仍然使用Xpath爬取,在右键检查图片时可以发现,网页分为两栏,如下图红框所示,根据class分为左右两栏,验证码分别位于两栏中。
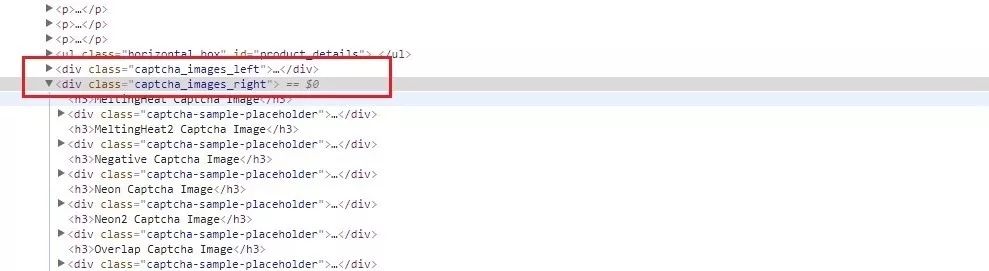
datas = html_lxml.xpath('.//div[@class="captcha_images_left"]|.//div[@class="captcha_images_right"]')
这里我使用了Xpath中的路径选择,在路径表达式中使用“|”表示选取若干路径,例如这里表示的就是选取class为"captcha_images_left"或者"captcha_images_right"的区块。再来看下运行结果:
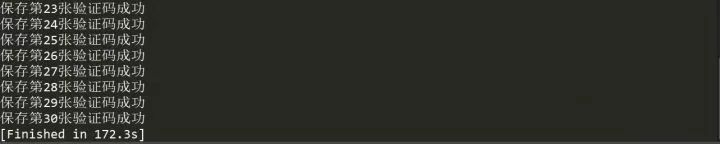
由于每爬取一张验证码图片都强制等待了1秒,最后这个运行时间确实让人绝望,看样子还是需要多线程来加快速度的,关于多进程多线程我们下次再说,这里我们先来看下爬取到的验证码图片。

图片到手了,接下来就是调用百度文字识别的OCR来识别这些图片了,在识别之前,先简单介绍一下百度OCR的使用方法,因为很多识别验证码的教程用的都是tesserocr库,所以一开始我也尝试过,安装过程中就遇到了很多坑,后来还是没有继续使用,而是选择了百度OCR来识别。百度OCR接口提供了自然场景下图片文字检测、定位、识别等功能。文字识别的结果可以用于翻译、搜索、验证码等代替用户输入的场景。另外还有其他视觉、语音技术方面的识别功能,大家可以直接阅读文档了解:百度OCR-API文档
https://ai.baidu.com/docs#/OCR-API/top
使用百度OCR的话,首先注册用户,然后下载安装接口模块,直接终端输入pip install baidu-aip即可。然后创建文字识别应用,获取相关Appid,API Key以及Secret Key,需要了解一下的是百度AI每日提供50000次免费调用通用文字识别接口的使用次数,足够我们挥霍了。
然后就可以直接调用代码了。
from aip import AipOcr
# 你的 APPID AK SK
APP_ID = '你的 APP_ID '
API_KEY = '你的API_KEY'
SECRET_KEY = '你的SECRET_KEY'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 读取图片
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('test.jpg')
# 调用通用文字识别, 图片参数为本地图片
result = client.basicGeneral(image)
# 定义参数变量
options = {
# 定义图像方向
'detect_direction' : 'true',
# 识别语言类型,默认为'CHN_ENG'中英文混合
'language_type' : 'CHN_ENG',
}
# 调用通用文字识别接口
result = client.basicGeneral(image,options)
print(result)
for word in result['words_result']:
print(word['words'])
这里我们识别的是这张图

可以看一下识别结果

上面是识别后直接输出的结果,下面是单独提取出来的文字部分。可以看到,除了破折号没有输出外,文字部分都全部正确输出了。这里我们使用的图片是jpg格式,文字识别传入的图像支持jpg/png/bmp格式,但在技术文档中有提到,使用jpg格式的图片上传会提高一定准确率,这也是我们爬取验证码时使用jpg格式保存的原因。
输出结果中,各字段分别代表:
log_id : 唯一的log id,用于定位问题
direction : 图像方向,传入参数时定义为true表示检测,0表示正向,1表示逆时针90度,2表示逆时针180度,3表示逆时针270度,-1表示未定义。
words_result_num : 识别的结果数,即word_result的元素个数
word_result : 定义和识别元素数组
words : 识别出的字符串
还有一些非必选字段大家可以去文档里熟悉一下。
接下来,我们要做的,就是将我们之前爬取到的验证码用刚介绍的OCR来识别,看看究竟能不能得到正确结果。
from aip import AipOcr
import os
i = 0
j = 0
APP_ID = '你的 APP_ID '
API_KEY = '你的API_KEY'
SECRET_KEY = '你的SECRET_KEY'
client = AipOcr(APP_ID, API_KEY, SECRET_KEY)
# 读取图片
file_path = 'D:\******\验证码图片'
filenames = os.listdir(file_path)
# print(filenames)
for filename in filenames:
# 将路径与文件名结合起来就是每个文件的完整路径
info = os.path.join(file_path,filename)
with open(info, 'rb') as fp:
# 获取文件夹的路径
image = fp.read()
# 调用通用文字识别, 图片参数为本地图片
result = client.basicGeneral(image)
# 定义参数变量
options = {
'detect_direction' : 'true',
'language_type' : 'CHN_ENG',
}
# 调用通用文字识别接口
result = client.basicGeneral(image,options)
# print(result)
if result['words_result_num'] == 0:
print(filename + ':' + '----')
i += 1
else:
for word in result['words_result']:
print(filename + ' : ' +word['words'])
j += 1
print('共识别验证码{}张'.format(i+j))
print('未识别出文本{}张'.format(i))
print('已识别出文本{}张'.format(j))
和识别图片一样,这里我们将文件夹验证码图片里的图片全部读取出来,依次让OCR识别,并依据“word_result_num”字段判断是否成功识别出文本,识别出文本则打印结果,未识别出来的用“----”代替,并结合文件名对应识别结果 。最后统计识别结果数量,再来看下识别结果。
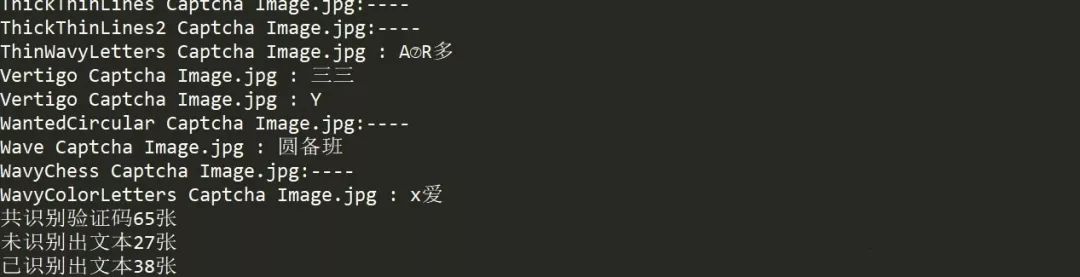
看到结果,只能说Amazing!60张图片居然识别出了65张,并且还有27张为未识别出文本的,这不是我想要的结果~先来简单看下问题出在哪里,看到“Vertigo Captcha Image.jpg"这张图名出现了两次,怀疑是在识别过程中由于被干扰,所以识别成两行文字输出了,这样就很好解释为什么多出来5张验证码图片了。可是!为什么会有这么多未识别出文本呢,而且英文数字组成的验证码识别成中文了,看样子,不对验证码图片进行去干扰处理,仅靠OCR来识别的想法果然还是行不通啊。那么接下来我们便使用图像处理的方法来重新识别验证码吧。
还是介绍验证码时用的这张图


这张图也没能被识别出来,让人头秃。接下来就对这张图片进行一定处理,看能不能让OCR正确识别
from PIL import Image
filepath = 'D:\******\验证码图片\AncientMosaic Captcha Image.jpg'
image = Image.open(filepath)
# 传入'L'将图片转化为灰度图像
image = image.convert('L')
# 传入'1'将图片进行二值化处理
image = image.convert('1')
image.show()
这样子转化后再来看下图片变成什么样了?

确实有些不同了,赶紧拿去试试能不能识别,还是失败了~~继续修改
from PIL import Image
filepath = 'D:\******\验证码图片\AncientMosaic Captcha Image.bmp'
image = Image.open(filepath)
# 传入'L'将图片转化为灰度图像
image = image.convert('L')
# 传入'l'将图片进行二值化处理,默认二值化阈值为127
# 指定阈值进行转化
count= 170
table = []
for i in range(256):
if i < count:
table.append(0)
else:
table.append(1 )
image = image.point(table,'1')
image.show()
这里我将图片保存成了bmp模式,然后指定二值化的阈值,不指定的话默认为127,我们需要先转化原图为灰度图像,不能直接在原图上转化。然后将构成验证码的所需像素添加到一个table中,然后再使用point方法构建新的验证码图片。


现在已经识别到文字了,虽然我不知道为啥识别成了“珍”,分析之后发现是因为z我在设置参数设置了“language_type”为“CHN_ENG”,中英文混合模式,于是我修改成“ENG”英文类型,发现可以识别成字符了,但依然没有识别成功,尝试其他我所知道的方法后,我表示很无语,我决定继续尝试PIL库的其他方法试试。
# 找到边缘
image = image.filter(ImageFilter.FIND_EDGES)
# image.show()
# 边缘增强
image = image.filter(ImageFilter.EDGE_ENHANCE)
image.show()

还是不能正确识别,我决定换个验证码试试。。。。。。

我找了这张带有阴影的
from PIL import Image,ImageFilter
filepath = 'D:\******\验证码图片\CrossShadow2 Captcha Image.jpg'
image = Image.open(filepath)
# 传入'L'将图片转化为灰度图像
image = image.convert('L')
# 传入'l'将图片进行二值化处理,默认二值化阈值为127
# 指定阈值进行转化
count= 230
table = []
for i in range(256):
if i < count:
table.append(1)
else:
table.append(0)
image = image.point(table,'1')
image.show()
简单处理后,得到这样的图片:

识别结果为:

识别成功了,老泪纵横!!!看样子百度OCR还是可以识别出验证码的,不过识别率还是有点低,需要对图像进行一定处理,才能增加识别的准确率。不过百度OCR对规范文本的识别还是很准确的。
那么与其他验证码相比,究竟是什么让这个验证码更容易被OCR读懂呢?
字母没有相互叠加在一起,在水平方向上也没有彼此交叉。也就是说,可以在每一个字 母外面画一个方框,而不会重叠在一起。
图片没有背景色、线条或其他对 OCR 程序产生干扰的噪点。
白色背景色与深色字母之间的对比度很高。
这样的验证码相对识别起来较容易,另外,像识别图片时的白底黑字就属于很标准的规范文本了,所以识别的准确度较高。至于更复杂的图形验证码,就需要更深的图像处理技术或者训练好的OCR来完成了,如果只是简单识别一个验证码的话,不如人工查看图片输入,更多一点的话,也可以交给打码平台来识别。
作者丨HDMI
https://www.zhihu.com/people/hdmi-blog/activities