
一起爬山吗?Python爬取并分析 201865 条《隐秘的角落》弹幕
本文不涉及剧透!请放心食用
最近又火了一部国产剧:《隐秘的角落》
如果你没看过,那可能会对朋友圈里大家说的“一起去爬山”、“小白船”、“还有机会吗”感到莫名其妙。

除了爱奇艺,可以考虑使用豆瓣、微博、知乎(电视剧数据分析 · 万能三件套)的数据。
爬虫
剧很精彩,但追剧界有句俗话说得好:“弹幕往往比剧更精彩”,为了让精彩延续下去,我终究没能忍住对弹幕下手。[1]
爱奇艺的弹幕数据是以 .z 形式的压缩文件存在的,先获取 tvid 列表,再根据 tvid 获取弹幕的压缩文件,最后对其进行解压及存储,大概就是这样一个过程。
这里参考了“数据兔小白[2]的代码,我又修改后实现分集爬取所有弹幕。
def get_data(tv_name,tv_id):
url = 'https://cmts.iqiyi.com/bullet/{}/{}/{}_300_{}.z'
datas = pd.DataFrame(columns=['uid','contentsId','contents','likeCount'])
for i in range(1,20):
myUrl = url.format(tv_id[-4:-2],tv_id[-2:],tv_id,i)
print(myUrl)
res = requests.get(myUrl)
if res.status_code == 200:
btArr = bytearray(res.content)
xml=zlib.decompress(btArr).decode('utf-8')
bs = BeautifulSoup(xml,"xml")
data = pd.DataFrame(columns=['uid','contentsId','contents','likeCount'])
data['uid'] = [i.text for i in bs.findAll('uid')]
data['contentsId'] = [i.text for i in bs.findAll('contentId')]
data['contents'] = [i.text for i in bs.findAll('content')]
data['likeCount'] = [i.text for i in bs.findAll('likeCount')]
else:
break
datas = pd.concat([datas,data],ignore_index = True)
datas['tv_name']= str(tv_name)
return datas
注:避免引起不必要的麻烦,本爬虫仅指出关键步骤,不再公开提供。
共爬取得到201865 条《隐秘的角落》弹幕数据。
弹幕发射器
按照用户id分组并对弹幕id计数,可以得到每位用户的累计发送弹幕数。
#累计发送弹幕数的用户
danmu_counts = df.groupby('uid')['contentsId'].count().sort_values(ascending = False).reset_index()
danmu_counts.columns = ['用户id','累计发送弹幕数']
danmu_counts.head()
第一名竟然发送了2561条弹幕,这只是一部12集的网剧啊。

难道他/她是水军?每条都发的差不多?
df_top1 = df[df['uid'] == 1810351987].sort_values(by="likeCount",ascending = False).reset_index()
df_top1.head(10)
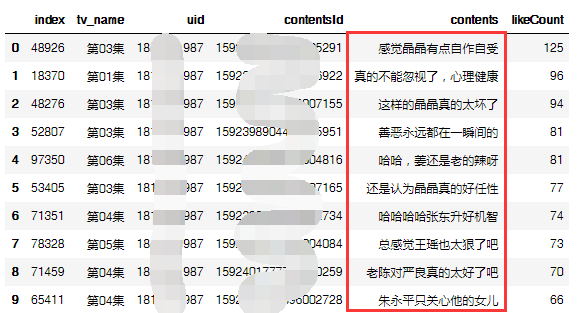 然而并不是,每一条弹幕都是这位观众的有感而发,可能他/她只是在发弹幕的同时顺便看看剧吧。
然而并不是,每一条弹幕都是这位观众的有感而发,可能他/她只是在发弹幕的同时顺便看看剧吧。这位“弹幕发射器”朋友,在每一集的弹幕量又是如何呢?
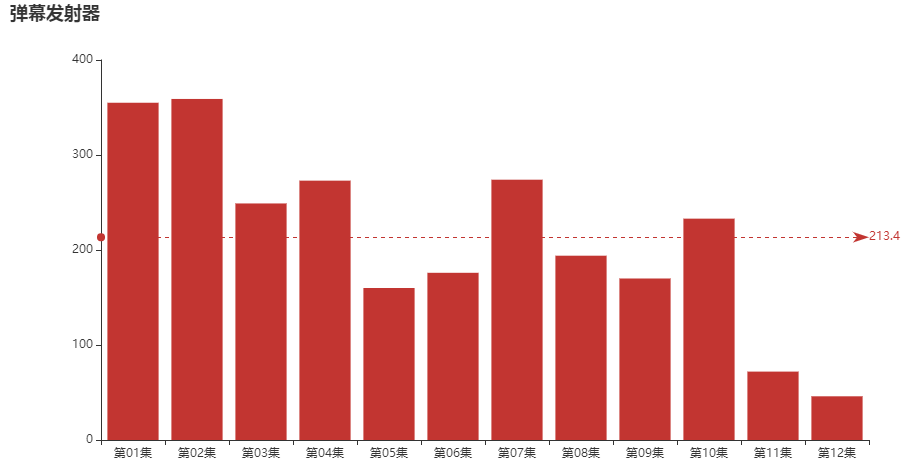
是不是通过上图可以侧面说明个别剧集的戏剧冲突更大,更能引发观众吐槽呢?
“弹幕发射器”同志,11、12集请加大输出!
这些弹幕大家都认同
抛开“弹幕发射器”同志,我们继续探究一下分集的弹幕。
看看每一集当中,哪些弹幕大家都很认同(赞)?
df_like = df[df.groupby(['tv_name'])['likeCount'].rank(method="first", ascending=False)==1].reset_index()[['tv_name','contents','likeCount']]
df_like.columns = ['剧集','弹幕','赞']
df_like

每一集的最佳弹幕都是当集剧情的浓缩,这些就是观众们票选出来的梗(吐槽)啊!
应该不算剧透吧,不算吧,不算吧
实在不行我请你去爬山也可

朝阳东升
除了剧本、音乐等,“老戏骨”和“小演员”们的演技也获得了网友的一致好评。
这部剧虽然短短12集,但故事线不仅仅在一两个人身上。每个人都有自己背后的故事,又因为种种巧合串联在一起,引发观众的持续性讨论。
我们统计一下演员们在弹幕中的出现次数,看看剧中的哪些角色大家提及最多。
a = {'张东升':'东升|秦昊|张老师', '朱朝阳':'朝阳', '严良':'严良', '普普':'普普', '朱永平':'朱永平', '周春红':'春红|大娘子', '王瑶':'王瑶', '徐静':'徐静|黄米依', '陈冠声':'王景春|老陈|陈冠声', '叶军':'叶军|皮卡皮卡', '马主任':'主任|老马', '朱晶晶':'晶晶','叶驰敏':'叶驰敏'}
for key, value in a.items():
df[key] = df['contents'].str.contains(value)
staff_count = pd.Series({key: df.loc[df[key], 'contentsId'].count() for key in a.keys()}).sort_values()
先计算出现次数,再利用pyecharts制作极坐标图。
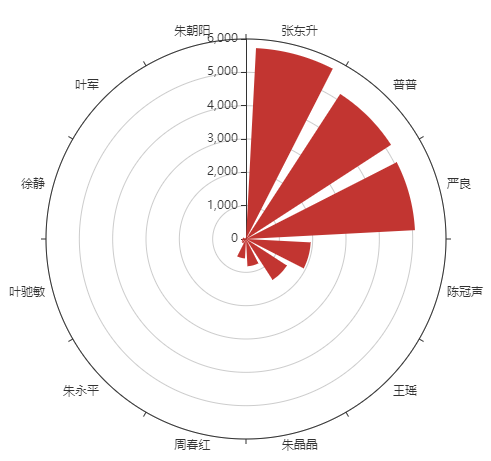
比较让我疑惑的三个小孩当中的朱朝阳提及量这么低,按理说应该与其其他两位大体相当啊。
又去源数据看了一遍,提及朱朝阳(朝阳)的弹幕确实很少,因为大部分在弹幕中观众一般就叫他“学霸”、“儿子”之类的了。
词云
总所周知,一篇数分文章不能少了词云。
每篇的词云都尽量用不同的方式。这次我采用的是stylecloud,它算是wordcloud词云包的升级版,看起来美观多了。
import stylecloud
from IPython.display import Image
stylecloud.gen_stylecloud(text=' '.join(text1), collocations=False,
font_path=r'C:\Windows\Fonts\msyh.ttc',
icon_name='fas fa-play-circle',size=400,
output_name='隐秘的角落-词云.png')
Image(filename='隐秘的角落-词云.png')

除了主角的名字以外,在这部以“孩子”为主题的剧中,对孩子的思想、行为的探讨占据重要部分,另外,剧中从年长的戏骨到年幼的孩子,每一个人都贡献了高光的演技,对他们演技的称赞也成为高频词汇。
而最出圈的“爬山”梗,更是被频频提及。

从《无证之罪》到《隐秘的角落》,都在证明悬疑犯罪题材在当下并非没有市场,要收获高人气高口碑,如何传播与营销终归只是手段,越来越多的团队沉下心来打磨精品剧集,观众才会愿意为剧买单,让“爬山”这样的梗一步步“出圈”。
参考文章
[2] 数据兔小白: 爬取爱奇艺弹幕后,我找到了共鸣
作者:朱小五
来源:凹凸数据
_往期文章推荐_