
目标检测中边界框的回归策略

极市导读
本文主要讲述:1.无Anchor的目标检测算法:YOLOv1,CenterNet,CornerNet的边框回归策略;2.有Anchor的目标检测算法:SSD,YOLOv2,Faster R-CNN的边框回归策略。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前面
无Anchor的目标检测算法边框回归策略
1. YOLOv1

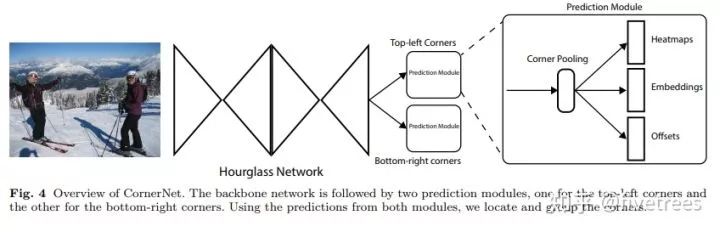
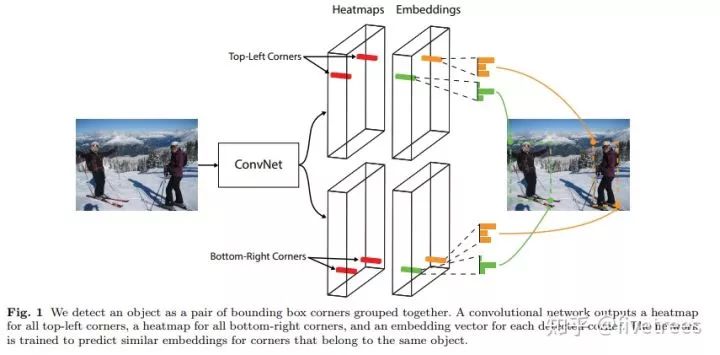
2. CornerNet
算法结构
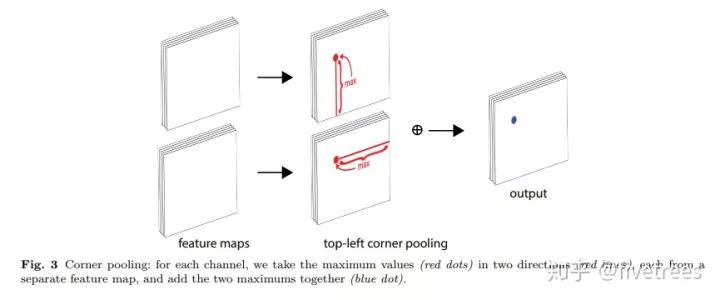
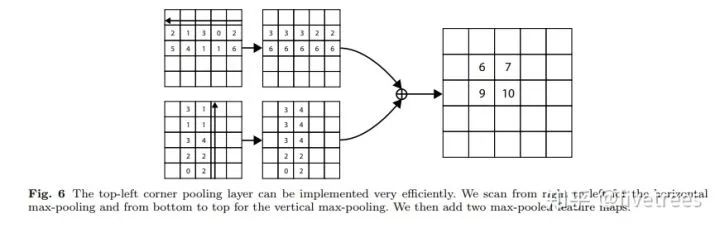
Corner poolin


Heatmaps

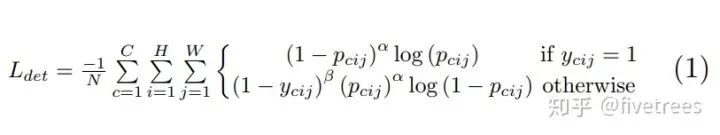
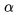
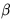 为控制每个点的权重的超参数,具体来说,参数用来控制难易分类样本的损失权重(在文章中 为2,为4),pcij表示预测的heatmaps在第c个通道(类别c)的(i,j)位置的值,ycij表示对应位置的ground truth,ycij=1时候的损失函数就是focal loss;ycij等于其他值时表示(i,j)点不是类别c的目标角点,照理说此时ycij应该是0(大部分算法都是这样处理的),但是这里ycij不是0,而是用基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的ycij值接近1,这部分通过β参数控制权重,这是和Focal loss的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近ground truth的误检角点组成的预测框仍会和ground truth有较大的重叠面积。
为控制每个点的权重的超参数,具体来说,参数用来控制难易分类样本的损失权重(在文章中 为2,为4),pcij表示预测的heatmaps在第c个通道(类别c)的(i,j)位置的值,ycij表示对应位置的ground truth,ycij=1时候的损失函数就是focal loss;ycij等于其他值时表示(i,j)点不是类别c的目标角点,照理说此时ycij应该是0(大部分算法都是这样处理的),但是这里ycij不是0,而是用基于ground truth角点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的ycij值接近1,这部分通过β参数控制权重,这是和Focal loss的差别。为什么对不同的负样本点用不同权重的损失函数呢?这是因为靠近ground truth的误检角点组成的预测框仍会和ground truth有较大的重叠面积。Offset
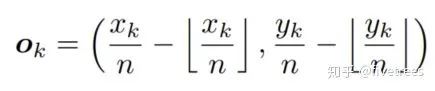

Embeddings

总损失函数
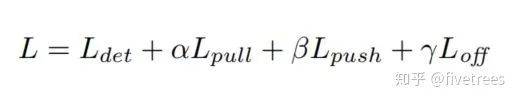
回归策略
补充
3. CenterNet
与CornerNet对比
2、CerterNet中也采用了和CornerNet一样的偏置(offset)预测,这个偏置表示的是标注信息从输入图像映射到输出特征图时由于取整操作带来的坐标误差,只不过CornerNet中计算的是2个角点的offset,而CenterNet计算的是中心点的offset。这部分还有一个不同点:损失函数,在CornerNet中采用SmoothL1损失函数来监督回归值的计算,但是在CenterNet中发现用L1损失函数的效果要更好,差异这么大是有点意外的,这是其二。
3、CenterNet直接回归目标框尺寸,最后基于目标框尺寸和目标框的中心点位置就能得到预测框,这部分和CornerNet是不一样的,因为CornerNet是预测2个角点,所以需要判断哪些角点是属于同一个目标的过程,在CornerNet中通过增加一个corner group任务预测embedding vector,最后基于embedding vector判断哪些角点是属于同一个框。而CenterNet是预测目标的中心点,所以将CornerNet中的corner group操作替换成预测目标框的size(宽和高),这样一来结合中心点位置就能确定目标框的位置和大小了,这部分的损失函数依然采用L1损失,这是其三。
回归策略
有Anchor的目标检测算法边框回归策略
1. Faster R-CNN

2. YOLOv2
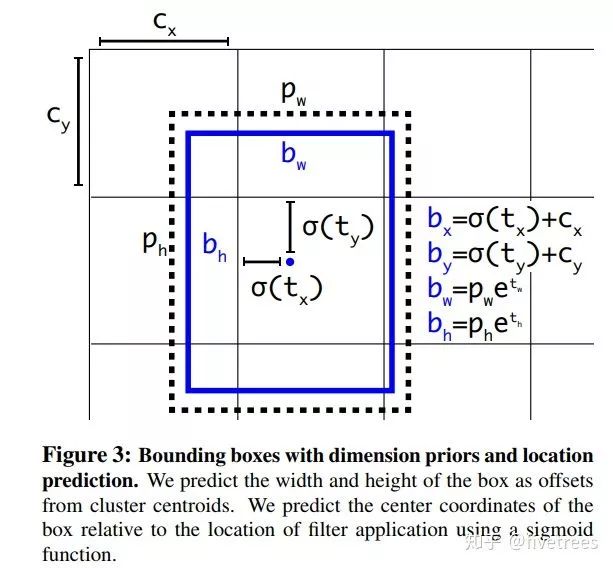
3. SSD
论文:https://arxiv.org/pdf/1512.02325.pdf

参考文献
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~

评论