
DIoU和CIoU:更快更好的边界框回归损失
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
边界框回归(Bounding Box Regression)是物体检测中重要的一项任务,之前大部分的物体检测模型是直接对边界框的位置(中心点)和大小(宽和高)进行回归,采用的损失函数往往是L1 norm和L2 norm,比如YOLOv1采用平方差损失,Faster RCNN采用smooth L1损失。不过近来的工作发现,直接采用IoU损失往往能得到更好的效果,因为IoU也是物体检测模型mAP的评测标准。GIoU损失更近一步地对IoU损失进行了优化,解决了预测框和目标框无任何重叠时的场景(此时IoU loss无梯度)。DIoU损失是GIoU损失的近一步优化,它不仅比GIoU损失的收敛速度更快,也能够实现更好的性能,目前也被广泛应用在物体检测模型中,如YOLOv5。
IoU和GIoU损失
IoU是物体检测模型边界框定位准确度的评价指标,它也可以用于边界框的回归损失,即IoU损失:
这里为检测模型预测的边界框,而是目标框。IoU损失是直接优化预测框和目标框的IoU,要比L1和L2损失更直接一些,另外L1和L2损失对边界框的大小敏感,而IoU损失则不会。由于预测框和目标框不重叠时IoU永远为0,所以IoU损失在此时就无法提供梯度。GIoU损失通过引入一个惩罚项来解决这个问题,其计算如下:
这里为包含和的最小矩形框,当预测框和目标框不重叠时,虽然IoU是0,但是增加的惩罚项将起作用,此时依然能够产生梯度,所以GIoU损失将比IoU损失有更快的收敛速度。
DIoU损失
虽然GIoU损失解决了IoU损失在预测框和目标框不重叠时梯度为0的问题,但DIoU这篇工作发现GIoU损失依然存在收敛速度慢和回归不准确的问题。首先,当预测框和目标框不重叠时,GIoU损失先倾向于增加预测框的大小以使得预测框和目标框重叠,之后IoU损失将起主要作用来最大化两者的IoU,如下图所示,这个优化过程并不是最优的,所以收敛速度较慢。
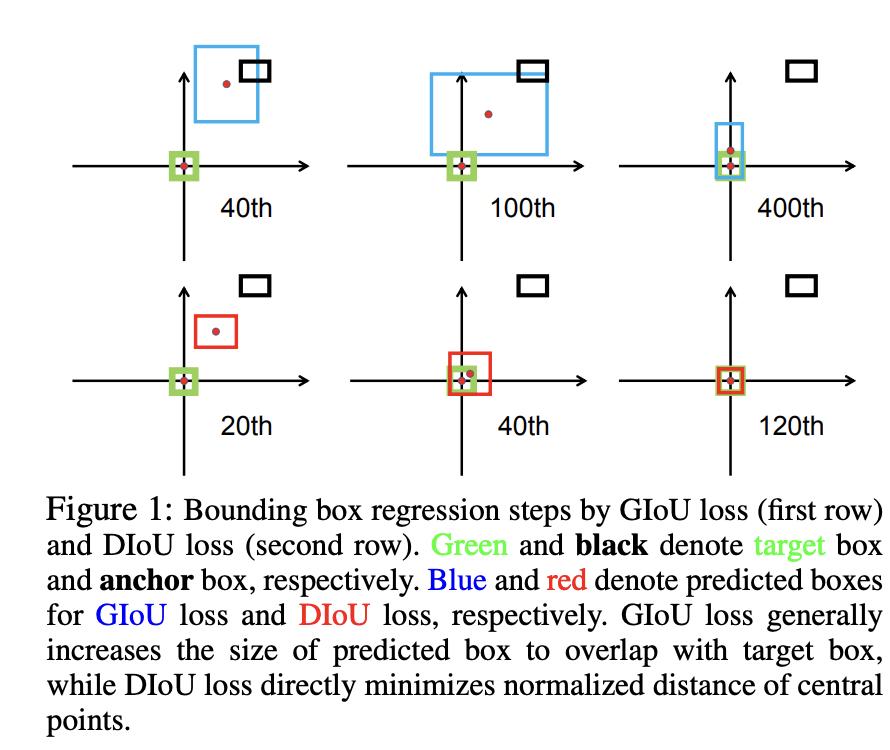 另外一个问题是,当预测框和目标框存在包含关系时,此时GIoU损失完全退化为IoU损失,如下图所示,此时预测框完全被包含在目标框中,GIoU损失的惩罚项为0,GIoU损失和IoU损失相等。此外,三种情况预测框的位置不同,但是IoU损失是相同的,所以IoU损失无法进一步区分它们的差异。
另外一个问题是,当预测框和目标框存在包含关系时,此时GIoU损失完全退化为IoU损失,如下图所示,此时预测框完全被包含在目标框中,GIoU损失的惩罚项为0,GIoU损失和IoU损失相等。此外,三种情况预测框的位置不同,但是IoU损失是相同的,所以IoU损失无法进一步区分它们的差异。
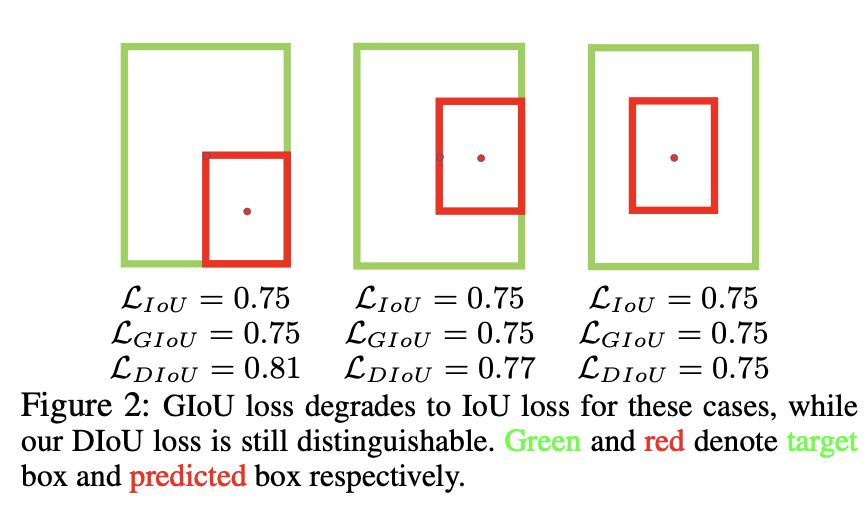 综上,GIoU由于优化路径并不是最优的以及比较依赖IoU损失项,所以它可能需要较长的迭代才能收敛。与GIoU不同,DIoU损失(Distance-IoU Loss)引入的惩罚项是直接最小化预测框和目标框中心点的归一化距离,计算如下所示:
综上,GIoU由于优化路径并不是最优的以及比较依赖IoU损失项,所以它可能需要较长的迭代才能收敛。与GIoU不同,DIoU损失(Distance-IoU Loss)引入的惩罚项是直接最小化预测框和目标框中心点的归一化距离,计算如下所示:
这里和是预测框和目标框的中心点,是计算两个中心点之间的欧式距离,是包含预测框和目标框的最小矩形框的对角线长度,下图为一个直观展示: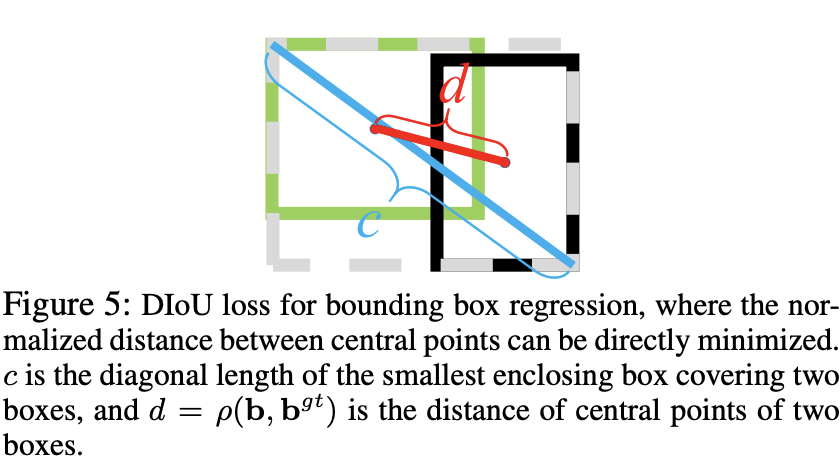 当预测框和目标框不重叠时,此时DIoU损失的惩罚项起主要作用,使得预测框移到和目标框重叠的位置,这比GIoU损失更直接,所以收敛速度也越快。当预测框和目标框存在包含关系时,DIoU损失的惩罚项依然也存在作用,对于之前的三种情况,虽然IoU损失和GIoU损失都是一样的,但是DIoU损失是不一样的,其中预测框和目标框的中心点重合时DIoU损失较小,这也是比较合理的。论文中设计了一个仿真实验来定量分析,如下图所示,在(10, 10)位置设定7个不同大小和高宽比的目标框,然后考虑在以(10, 10)为圆心且半径为10的圆内均匀选择5000个位置,每个位置放置7种不同大小和7种不同高宽比的锚框,所以总共有7x5000x7x7个回归实验,考虑了不同情况下的边界框回归。右图为不同的损失函数的收敛曲线,这里纵坐标是所有实验的回归误差(这里统一计算L1 norm)之和,可以看到GIoU损失的收敛速度比IoU损失要快,而DIoU损失进一步加快了收敛速度,200个迭代下DIoU损失也可以得到更低的误差。
当预测框和目标框不重叠时,此时DIoU损失的惩罚项起主要作用,使得预测框移到和目标框重叠的位置,这比GIoU损失更直接,所以收敛速度也越快。当预测框和目标框存在包含关系时,DIoU损失的惩罚项依然也存在作用,对于之前的三种情况,虽然IoU损失和GIoU损失都是一样的,但是DIoU损失是不一样的,其中预测框和目标框的中心点重合时DIoU损失较小,这也是比较合理的。论文中设计了一个仿真实验来定量分析,如下图所示,在(10, 10)位置设定7个不同大小和高宽比的目标框,然后考虑在以(10, 10)为圆心且半径为10的圆内均匀选择5000个位置,每个位置放置7种不同大小和7种不同高宽比的锚框,所以总共有7x5000x7x7个回归实验,考虑了不同情况下的边界框回归。右图为不同的损失函数的收敛曲线,这里纵坐标是所有实验的回归误差(这里统一计算L1 norm)之和,可以看到GIoU损失的收敛速度比IoU损失要快,而DIoU损失进一步加快了收敛速度,200个迭代下DIoU损失也可以得到更低的误差。
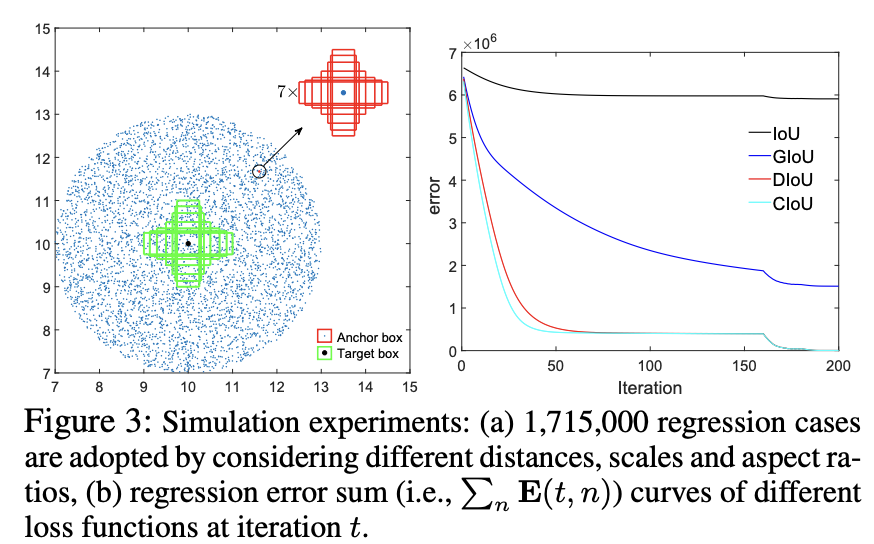
下图进一步给出了不同位置的迭代到最后的误差,如果采用IoU损失,只有anchor和目标框有重叠时才有效,所以只有中间的一部分位置上误差比较低;而GIoU损失可以解决不重叠的情况,所以大部分的位置都可以得到较低的误差,但是在水平和垂直的一部分边缘位置上误差较大,这主要是因为这些位置容易出现目标框被包含在预测框中,此时GIoU损失的惩罚项失去作用,从而收敛较慢;对于DIoU损失,其在所有的位置均能够得到较小的误差,这说明DIoU损失不仅能解决非重叠问题,而且收敛速度更快。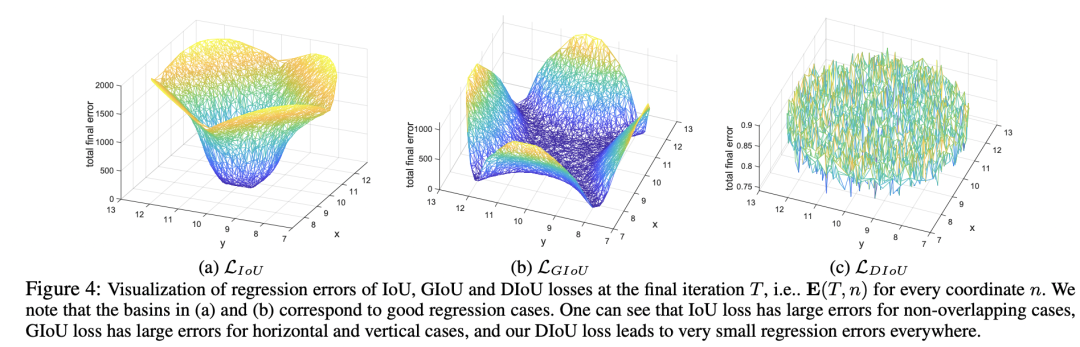 目前torchvision库已经实现了DIoU损失,其实现代码如下所示:
目前torchvision库已经实现了DIoU损失,其实现代码如下所示:
def _diou_iou_loss(
boxes1: torch.Tensor,
boxes2: torch.Tensor,
eps: float = 1e-7,
) -> Tuple[torch.Tensor, torch.Tensor]:
# 计算IoU
intsct, union = _loss_inter_union(boxes1, boxes2)
iou = intsct / (union + eps)
# 计算最小包络矩形
x1, y1, x2, y2 = boxes1.unbind(dim=-1)
x1g, y1g, x2g, y2g = boxes2.unbind(dim=-1)
xc1 = torch.min(x1, x1g)
yc1 = torch.min(y1, y1g)
xc2 = torch.max(x2, x2g)
yc2 = torch.max(y2, y2g)
# 计算对角线平方
diagonal_distance_squared = ((xc2 - xc1) ** 2) + ((yc2 - yc1) ** 2) + eps
# 中心点
x_p = (x2 + x1) / 2
y_p = (y2 + y1) / 2
x_g = (x1g + x2g) / 2
y_g = (y1g + y2g) / 2
# 中心点的欧式距离
centers_distance_squared = ((x_p - x_g) ** 2) + ((y_p - y_g) ** 2)
loss = 1 - iou + (centers_distance_squared / diagonal_distance_squared)
return loss, iou
CIoU损失
除了DIoU损失,论文还提出了一个更全面的回归损失:CIoU损失(Complete IoU Loss),它相比DIoU损失还增加了对高宽比的约束,其计算公式如下:
这里的用于计算预测框和目标框的高宽比的一致性,这里是用tan角来衡量:
而是一个平衡参数(这个系数不参与梯度计算),这里根据IoU值来赋予优先级,当预测框和目标框IoU越大时,系数越大:
CIoU损失相比DIoU损失增加了新的惩罚项,所以其有更快的收敛速度,从上面的仿真实验对比上也可以看出。目前torchvision也已经实现了CIoU损失,实现代码如下所示:
def complete_box_iou_loss(
boxes1: torch.Tensor,
boxes2: torch.Tensor,
eps: float = 1e-7,
):
# 计算DIoU和IoU
diou_loss, iou = _diou_iou_loss(boxes1, boxes2)
x1, y1, x2, y2 = boxes1.unbind(dim=-1)
x1g, y1g, x2g, y2g = boxes2.unbind(dim=-1)
# 计算预测框和目标框的width和height
w_pred = x2 - x1
h_pred = y2 - y1
w_gt = x2g - x1g
h_gt = y2g - y1g
v = (4 / (torch.pi**2)) * torch.pow((torch.atan(w_gt / h_gt) - torch.atan(w_pred / h_pred)), 2)
# 参数不参与梯度
with torch.no_grad():
alpha = v / (1 - iou + v + eps)
loss = diou_loss + alpha * v
return loss
实验对比
论文共选取了三个模型来对比不同回归损失的效果,它们分别是YOLOv3,SSD和Faster R-CNN,其中前面两个是单阶段检测模型,实验数据集为VOC数据集,而Faster R-CNN时两阶段检测模型,在COCO数据集实验。对比实验结果如下所示,可以看到DIoU损失相比GIoU损失在AP上有提升,而CIoU损失有进一步的提升。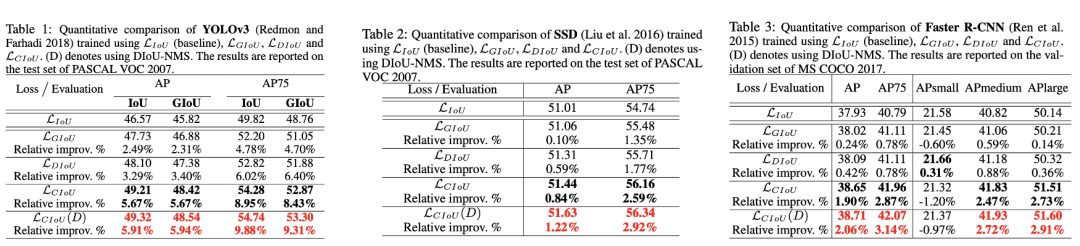 最后,论文也指出DIoU还可以替换IoU来优化NMS过程,原来的NMS是基于IoU来去除重复框,这里提出的DIoU- NMS是基于DIoU来评价两个预测框的重复度,这意味着不仅考虑重合面积还考虑中心点距离,其判定准则如下所示:
最后,论文也指出DIoU还可以替换IoU来优化NMS过程,原来的NMS是基于IoU来去除重复框,这里提出的DIoU- NMS是基于DIoU来评价两个预测框的重复度,这意味着不仅考虑重合面积还考虑中心点距离,其判定准则如下所示: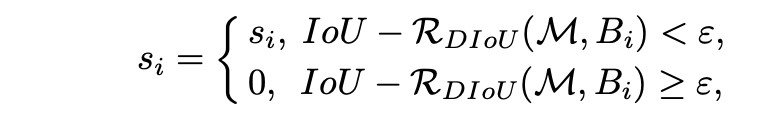 采用DIoU- NMS后,模型的AP值有进一步的提升。下图为NMS和DIoU- NMS的一个对比例子,在这种密集场景中,NMS去除了一个正确的预测框导致漏检,而DIoU- NMS则保留了从而降低漏检。
采用DIoU- NMS后,模型的AP值有进一步的提升。下图为NMS和DIoU- NMS的一个对比例子,在这种密集场景中,NMS去除了一个正确的预测框导致漏检,而DIoU- NMS则保留了从而降低漏检。
参考
Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression https://giou.stanford.edu/
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号
