
一文让你掌握22个神经网络训练技巧
↑ 点击蓝字 关注极市平台

作者丨匡吉
来源丨深蓝学院
编辑丨极市平台
极市导读
在神经网络训练过程中,本文给出众多tips可以更加简单方便的加速训练网络。这些tips作为一些启发式建议,让大家更好理解工作任务,并选择合适的技术。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
神经网络训练是一个非常复杂的过程,在这过程中,许多变量之间相互影响,因此我们研究者在这过程中,很难搞清楚这些变量是如何影响神经网络的。而本文给出的众多tips就是让大家,在神经网络训练过程中,更加简单方便的加速训练网络。当然,这些tips并不是训练网络的必要过程,而是作为一些启发式建议,让大家更好的理解自己手上的工作任务,并且有针对性的选择合适的技术。
首先,选择一个很好的初始训练状态,是一个很广泛的话题,包括:从图像增强到选择超参数等等,下面我们具体列出了具体的操作:·
Overfit a single batch(单批次过拟合)·
Run with a high number of epochs(运行大量epoch)·
Set seeds(设置种子参数)
Rebalance the dataset(重平衡数据集)
Use a neutral class(使用中性类)
Set the bias of the output layer(设置输出层偏差)
Tune the learning rate(调整学习率)
Use fast data pipelines(使用快速数据流程)
Use data augmentation(使用数据增强)
Train an AutoEncoder on unlabeled data, use latent space representation as embedding(在未标记的数据上训练AutoEncoder,使用潜在空间表示作为嵌入信息)
Utilize embeddings from other models(利用来自其他模型的嵌入信息)
Use embeddings to shrink data(使用嵌入来缩小数据)
Use checkpointing(使用检查点)
Write custom training loops(编写自定义训练循环)
Set hyperparameters appropriately(设置合适的超参数)
Use EarlyStopping(使用EarlyStopping)
Use transfer-learning(使用迁移学习)
Employ data-parallel training(采用数据并行训练)
Use sigmoid activation for multi-label tasks(将sigmoid激活用于多标签任务)
One-hot encode categorical data(One-hot编码分类数据
Rescale numerical inputs(重调整数值输入)
Use knowledge distillation(使用知识蒸馏)
1 Overfit a single batch
(单批次过拟合)
单批次过拟合——主要是用来测试我们网络的性能。首先,输入单个数据批次,并且保证这个batch数据对应的标签是正确的(如果需要标签的话)。然后,重复在这个batch数据上进行训练,直到损失函数数值达到稳定。如果你的网络不能到达一个完美的准确率(利用不同指标),那么首先检查一下数据,在我们提出的这个方法,就是在确保数据没有问题的情况下,检测我们模型的性能。这样,就避免了我们使用过于庞大或复杂的模型来解决简单的问题,毕竟找到最合适的方法才是最有效的(杀鸡用不着牛刀)。
2 Run with a high number of epochs
(运行大数值epochs)
很多情况下,我们通过大量epochs训练模型之后,可以获得一个很好的结果。如果,我们可以承受长时间的模型训练,那么我们可以采用一种策略来选择epochs数值(例如:从100逐渐增长到500)。这样,当我们有过大量训练模型的经验之后,大家就可以总结出自己的一组数据(称为epoch factors),使用这些参数,我们训练新的模型时,可以快速设置初始训练epochs,并且按照一定的比例来增加epochs。
3 Set seeds
(设置种子参数)
为了保证模型的可重现性(reproducibility),我们可以采用一种方法,就是设置任何随机数生成操作的种子。例如,如果我们使用TensorFlow框架,我们可以采用下面的代码片段:
import os, random
import numpy as np
import tensorflow as tf
def set_seeds(seed: int):
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
tf.random.set_seed(seed)
np.random.seed(seed)
使用操作种子的原因是,计算机并不能真实输出随机数,也就是计算机输出的是伪随机数,它是按照一定的规则来输出随机数。这样的话,我们可以采用一系列规则来模拟随机数的生成,也就是我们采用set_seed这个函数来模拟随机数生成,具体的细节,大家可以查阅TensorFlow的文档。
4 Rebalance the dataset
(重平衡数据集)
不平衡数据集----也就是有一个类别或多个类别,占据了整个数据集的大部分;反之亦同,一个类别或多个类别占据数据集的很小一部分。如果我们使用的数据的不同类别都有基本相同的特性,那么我们考虑采用一些策略来解决这样的问题,例如:上采样最小类别数据,下采样最大类别数据,采集额外的数据样本(如果可能的话)和使用数据增强来产生伪数据样本等等。
5 Use a neutral class
(使用中性类)
考虑下面一种情况,你的数据集有两个类别:class1和class2(即不是class1),假设这些数据样本都是由专家标注的(确保数据标签的准确性)。那么,如果这些数据中有一个样例无法确定其类别,那么这个样本的类别可能被标记为none,或者标记为一个类别(但是其置信度非常低)。这样的情况下,我们引入第三个类别是一个很好的方法,来解决这样的问题。当前情况下,这个额外的类别表示为“不确定”类别。在网络模型训练过程中,我们可以将这第三类数据排除在外,不参与训练。之后,我们就可以使用训练好的模型,对这些模糊标签数据样例进行重新标注。
6 Set the bias of the output layer
(设置输出层偏差)
对于未标注的数据集,那么网络在初始阶段对于数据样例的猜测无法避免。即使网络模型可以通过训练来学习数据样例的正确标签,但是这样会大大增加训练的时间。我们可以通过在模型设计阶段,设计一个更好的模型偏差公式,来减少模型训练时间。对于一个sigmoid层来说,偏差可以通过下面公式来计算(假设只有两个类别):
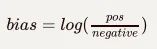
图片
当我们在创建模型之后,可以使用上面计算的数值来初始化偏差。
7 Tune the learning rate
(调整学习率)
如果你想要调整一些超参数,那么首要关注的重点就是----学习率。下面,我们给出一个学习率设置过高情况下,模型学习结果的输出图:
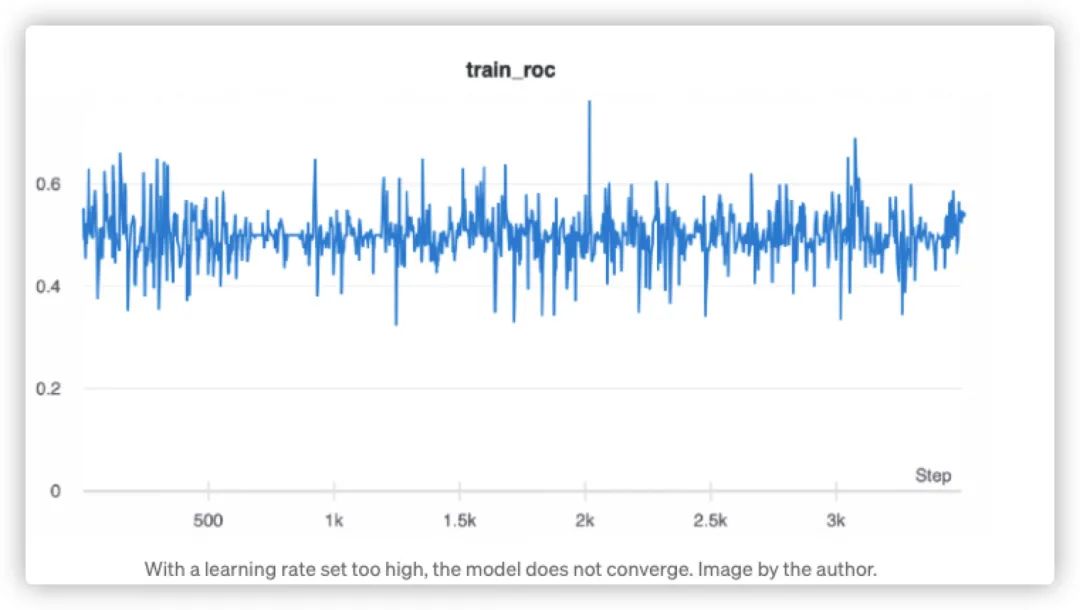
点击可查看大图
相比之下,如果使用一个不同的、较小的初始学习率,我们可以得到下面的结果:
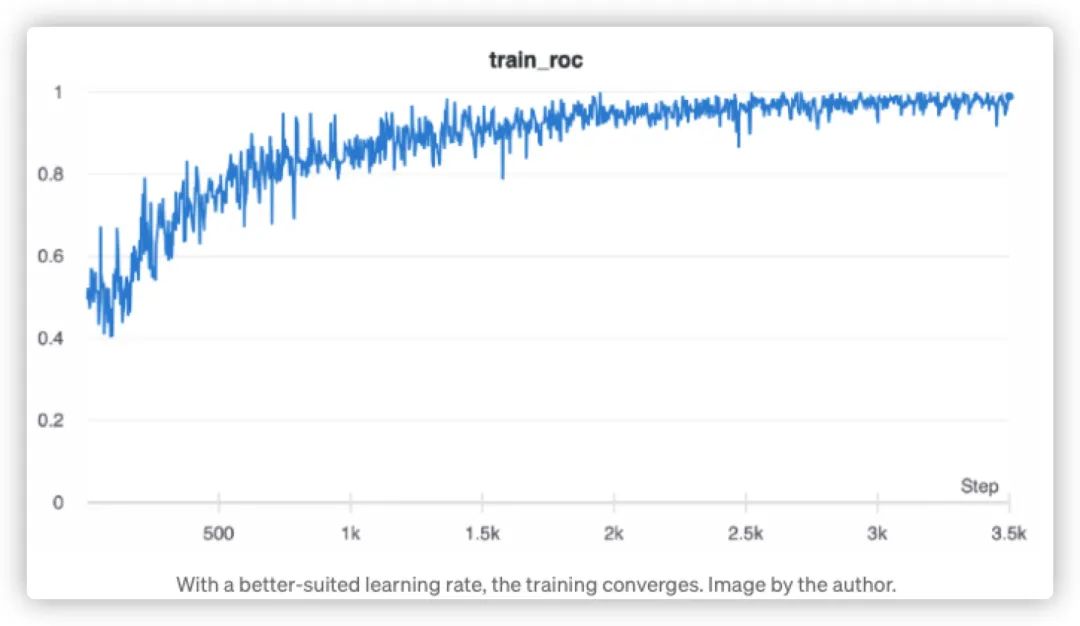 点击可查看大图
点击可查看大图
显而易见,学习率选择对应模型的训练时间消耗和准确度,都尤为重要,这里我们不会展开讲解如果设计策略来通过训练选取一个最优学习率,而是会在后续文章中详细给出选取最优学习率的方法(欢迎关注后续文章)。这里,我们给出经验的学习数值,也就是给出初始学习率范围为0.001和0.01之间。
8 Use fast data pipelines
(使用快速数据流程)
对于小项目来说,我们可以采用一个定制化生成器。而当我们参与一个大项目时,我们可以使用一个专门的数据集机制来替换生成器。在TenorFlow例子中,我们可以采用tf.data这个API,这个API函数包含大部分需要的方法,例如:shuffling、batching和prefetching等等。这个专业的数据集机制,替代我们定制化的数据生成器,可以很好应用在我们实际项目中。
9 Use data augmentation
(使用数据增强)
数据增强可以让我们训练一个更加鲁棒的网络模型,通过增加数据集的数量,或者通过上采样小类别数据,但是这些数据增强,带来的消耗就是训练次数的增加,下面我们给出一些常用的普通图像数据增强方法:
1.Flip(翻转)
我们可以水平翻转或者垂直翻转,很多框架提供了翻转的实现,话不多说,我们直接给出代码示例(以TensorFlow为例):
#You can perform flips by using any of the following commands, #from
your favorite packages. Data Augmentation Factor = 2 to #4x
# NumPy.'img' = A single image.
flip_1 = np.fliplr(img)
# TensorFlow. 'x' = A placeholder for an image.
shape = [height, width, channels] x = tf.placeholder(dtype = tf.float32, shape = shape)
flip_2 = tf.image.flip_up_down(x)
flip_3 = tf.image.flip_left_right(x)
flip_4 = tf.image.random_flip_up_down(x)
flip_5 = tf.image.random_flip_left_right(x)

点击查看大图
2.Rotation(旋转)
注意,在旋转之后,图像的维度信息就不会得到保存,下面给出代码示例:
# Placeholders: 'x' = A single image, 'y' = A batch of images
# 'k' denotes the number of 90 degree anticlockwise rotations
shape = [height, width, channels] x = tf.placeholder(dtype = tf.float32, shape = shape)
rot_90 = tf.image.rot90(img, k=1)
rot_180 = tf.image.rot90(img, k=2)
# To rotate in any angle. In the example below, 'angles' is in
radians
shape = [batch, height, width, 3] y = tf.placeholder(dtype = tf.float32, shape = shape)
rot_tf_180 = tf.contrib.image.rotate(y, angles=3.1415)
# Scikit-Image. 'angle' = Degrees. 'img' = Input Image
# For details about 'mode', checkout the interpolation section below.
rot = skimage.transform.rotate(img, angle=45, mode='reflect')

点击查看大图
3.Scale(缩放)
图像可以向内缩放或者向外缩放,这里我们给出代码示例:
# Scikit Image. 'img' = Input Image, 'scale' = Scale factor
# For details about 'mode', checkout the interpolation section below.
scale_out = skimage.transform.rescale(img, scale=2.0,
mode='constant')
scale_in = skimage.transform.rescale(img, scale=0.5, mode='constant')
# Don't forget to crop the images back to the original size (for
# scale_out)

点击查看大图
4.Crop(剪切)
注意,剪切不同于缩放,剪切只是随机采样原始图片,代码示例如下:
# TensorFlow. 'x' = A placeholder for an image.
original_size = [height, width, channels] x = tf.placeholder(dtype = tf.float32, shape = original_size)
# Use the following commands to perform random crops
crop_size = [new_height, new_width, channels]
seed = np.random.randint(1234) x = tf.random_crop(x, size = crop_size, seed = seed)
output = tf.images.resize_images(x, size = original_size)

点击查看大图
这里,我们对于数据增强也就不在赘述,一些高级的数据增强方法,包括使用GAN方法等等,我们也会在后续文章系列中详细讲述,欢迎关注。
10 Train an AutoEncoder on unlabeled data, use latent space representation as embedding
(在未标记的数据上训练AutoEncoder,使用潜在空间表示作为嵌入信息)
如果我们用来训练的标注数据集相对较小,那么我们仍然可以利用一些策略来使用这些数据集来完成任务。其中一个方法就是采用AutoEncoder,这其中的背景是,我们可以很方便的采集未标记的数据。那么,我们就可以使用AutoEncoder,并且AutoEncoder巨头一个合适大小的潜在空间(例如:300到600条目),来获得一个合理且较小的重建损失函数值。为了获取实际数据的嵌入信息,我们可以丢弃decoder网络层,然后我们使用保留的encoder网络层来生成嵌入信息。
11 Utilize embeddings from other models
(利用来自其他模型的嵌入信息)
不同于第10条,使用的是我们自己的数据来获得嵌入信息,我们还可以从其他模型学习到嵌入信息。对于文本数据任务,下载预学习的嵌入信息是很普遍的方法。而对对于图像数据任务,我们可以使用在大数据集(例如:ImageNet)上训练好的模型,选择一个充分训练的网络层,并且对这些输出进行切割,然后使用这些切割的结果作为嵌入信息。
12 Use embeddings to shrink data
(使用嵌入来缩小数据)
首先,假设我们的数据集样例都有一个类别特征信息,那么在一开始,某个数据样例对应的类别特征只可能取两个值,也就是对应的one-hot编码有两个下标。但是,一旦这个类别值扩大到1000类或者更大的值,那么一个稀疏的one-hot编码方法就不再高效,因为我们可以在一个相对较低的维度表示这些数据,那么采用信息嵌入就是一个有效的方法。我们可以在训练之前插入一个嵌入层(将大类别数据信息,从0到1000,甚至更大类别),将类别信息输入,或者一个降维的嵌入信息。这样的表示,可以通过网络模型学习来获得。
13 Use checkpointing
(使用检查点)
当我们训练一个网络模型数个小时甚至更久时间之后,但是很不幸,这个模型奔溃了,但是训练的所有信息都丢失,那么这就是一个很令人沮丧的事情。考虑到硬件和软件都不是百分之分完善的运行,那么我们做好保存点的存储是一个很重要的操作。在简单的检查点使用中,我们可能只是保存了每k步模型的权重,到后面复杂的检查点使用中,我们可以保存优化器的状态,以及当前和任何其他的关键信息。然后,在训练运行开始后,我们可以检查任何失败的运行快照,并且基于这个运行快照快速恢复所有必要的设置。尤其是,在14条自定义训练训练结合使用检查点非常有效。
14 Write custom training loops
(编写自定义训练循环)
在大多数情况下,使用默认的训练流程,例如TensorFlow中的model.fit\(\),这就足够有效了。但是,我们注意到使用默认训练流程的灵活性具有局限,一些微小的改动可能很容易合并,但是较大的修改就很难实施。这也就是我们建议自行编写自定义算法。这里,我们也不再赘述,会在后续系列文章中展开来讲,如何通过不同的代码案例,快速实现修改算法,整合我们自己的最新想法。
15 Set hyperparameters appropriately
(设置合适的超参数)
现代GPU非常擅长矩阵计算,这也就是它们被广泛用于训练大型神经网络模型的原因。通过选择合适的超参数,我们可以进一步提高算法的效率,例如对于Nvidia GPU(目前主流的GPU),我们可以参考下列指南:
1. 选择的batchsize可以被4正常,或者2的倍数
2. 对于稠密网络层,设定输入和输出都可以被64整除
3. 对于卷积层,设定输入和输出通道可以被4正常,或者2的倍数
4. 将输入图像从RGB三通道padding到4通道
5. 使用BHWC的数据模式(Batch_height_width_channels)
6. 对于递归网络层,设定batch和隐藏层可以被4整除,理想值为64、128、256
这些建议遵循的思想是,让数据的分布更加均衡。这里,我们给出一些参考文档:
Nvidia文档1:https://docs.nvidia.com/deeplearning/performance/index.html
Nvidia文档2:https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html
Nvidia文档3https://docs.nvidia.com/deeplearning/performance/dl-performance-convolutional/index.html
16 Use EarlyStopping
(使用EarlyStopping)
什么时候可以停止训练模型,这个问题很难回答。可能发生的一种现象就是深度双层下降:也就是你的模型指标在稳步改善之后开始恶化,然后,经过一些训练更新后,模型分数再次提高,甚至比之前更好。为了避免在这之间来回震荡,我们可以使用验证数据集。这个单独分出来的数据集用来衡量算法,在新的、看不见数据上的性能。如果性能在我们设定的“耐心步数”范围内不在更新,那么模型就不再继续训练了。这里,关键就是选择合适的“耐心步数参数”,可以帮助我们的模型客服克服暂时的分数高原,一个常用的“耐心步数参数”可以选取为5到20epochs之间。
17 Use transfer-learning
(使用迁移学习)
迁移学习背后的想法,就是利用从业中已经在大量数据集上训练得到的模型结果成就,应用在我们的任务上。理想情况下,我们使用的网络针对相同的数据类型(图像、文本、音频)和我们的任务(分类、翻译、检测)类似的任务进行了训练。主要有两种相关的方法:
1.Fine-tuning(微调)
微调是采用已经训练好的模型,并更新特点问题的权重的任务。通常情况下,我们会冻结前几层,应为它们经过训练可以识别基本特征,然后在我们的数据集上对其余层进行微调。
2.Feature extraction(特征提取)
与微调相反,特征提取描述了一种使用经过训练的网络来提取特征的方法。在预选训练好的模型上,添加自己的分类器,只更新这部分的网络;而基层被冻结。我们遵循此方法的原因是,原始顶层网络只是针对特点问题进行训练的,但是我们的任务是有所不同的。通常从头开始学习自定义部分网络层,我们就可以确保专注于我们的数据集----同时保持大型基础模型的优势。
18 Employ data-parallel training
(采用数据并行训练)
如果我们想要更快的训练我们的模型,那么可以在多个GPU上运行算法来计算训练速度。通常情况下,这是按照数据并行的方式完成的:网络在不同的设备上复制,不同批次的数据被拆分和分发。然后,将梯度平均并应用在每个网络副本上。在TensorFlow上,我们可以采用多种不同的分布式训练策略。最简单的选择就是“MirroredStategy”,但是还有很多其他策略,这里不再赘述。例如,如果我们编写自定义训练循环(如上面14条),则可以遵循这些教程。按照我们的训练经验来看,将数据从一个GPU分布到二到三个训练,速度是最快的,对于大型数据集来说,这是减少训练次数的有效途径。
19 Use sigmoid activation for multi-label tasks
(将sigmoid激活用于多标签任务)
在样本可以有多个标签的情况下,我们可以使用sigmoid激活函数,与softmax不同的是,sigmoid单独应用于每个神经元,这意味着多个神经元可以被触发,并且输出值都介于0和1之间,这样方便于解释。这个方法在一些任务中很重要,例如,将样本分类为多个类别或者检测各种不同的对象。
20 One-hot encode categorical data
(One-hot编码分类数据)
由于我们使用数字表示的需要,因此需要将分类数据编码为数字。例如,我们不能直接反馈得到“金毛”类别,而只能得到表示“金毛”的类别数字。一个比较吸引人的选择就是枚举所有可能的值,也就是说,这种方法意味着在编码为1的“金毛”和编码为2的“橘猫”,来进行排序。但是,实际使用中这些排序很少使用,这也就是我们依赖one-hot编码的原因,这种编码保证了变量的独立性。
21 Rescale numerical inputs
(重调整数值输入)
网络模型通过更新权重进行训练,而优化器主要负责这一点。通常情况下,如果输出值介于[-1,1]之间,它们可以被调整为最佳值,那么这是为啥呢?让我们假设一个丘陵景观,我们为了寻找最低点,如果周围区域的丘陵越多,那么我们花在寻找局部丘陵最小值上的时间就越多。但是,如果我们可以修改景观的现状呢?我们是否可以更快地找到解决方案吗?这就是我们通过调整数值所实现的,当我们将数值缩放到[-1,1]时,我们使用曲率更加球型(也就是更圆、更均匀)。如果我们使用这个范围的数据训练我们的模型,我们可以更快地收敛。这是为什么呢?因为特征的大小(即权重值)影响梯度的大小,较大的特征会产生较大的梯度,从而导致较大的权重更新,这些更新需要更多的步骤来收敛,导致训练速度降低。大家还想进一步了解这方面的内容,可以查阅TensorFlow的教程。
22 Use knowledge distillation
(使用知识蒸馏)
大家一定听说过BERT模型吧?这个Transformer模型有几亿个参数,但是我们可能无法在我们的GPU上进行训练它,这大量的参数就是知识蒸馏过程变得有效的地方,我们通过训练第二个模型来产生更大模型的输出,而作为输出仍是原始数据集,但是标签确实参考模型的输出,也被称为软输出。这种技术的目标是在小模型的帮助下,复制更大的模型。这里,我们也没有过度讲解知识蒸馏和教师--学生网络模型的知识,大家有进一步了解的需要,可以查阅这些相关教程。
参考文献
[1].https://towardsdatascience.com/tips-and-tricks-for-neural-networks-63876e3aad1a?gi=2 732cb2a6e99
[2].https://nanonets.com/blog/data-augmentation-how-to-use-deep-learning-when-you-ha ve-limited-data-part2/
[3].https://www.tensorflow.org/tutorials/structured_data/imbalanced_data#optional_set_the_ correct_initial_bias
[4].https://docs.nvidia.com/deeplearning/performance/index.html
[5].https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/inde x.html
[6].https://docs.nvidia.com/deeplearning/performance/dl-performance-convolutional/index. html
[7].https://openai.com/blog/deep-double-descent/
[8].https://www.tensorflow.org/tutorials/distribute/multi_worker_with_ctl
[9].https://www.tensorflow.org/tutorials/images/transfer_learning#rescale_pixel_values
[10].https://medium.com/huggingface/distilbert-8cf3380435b5
如果觉得有用,就请分享到朋友圈吧!
△点击卡片关注极市平台,获取最新CV干货
公众号后台回复“79”获取CVPR 2021:TransT 直播链接~
极市干货
YOLO教程:一文读懂YOLO V5 与 YOLO V4|大盘点|YOLO 系目标检测算法总览|全面解析YOLO V4网络结构
实操教程:PyTorch vs LibTorch:网络推理速度谁更快?|只用两行代码,我让Transformer推理加速了50倍|PyTorch AutoGrad C++层实现
算法技巧(trick):深度学习训练tricks总结(有实验支撑)|深度强化学习调参Tricks合集|长尾识别中的Tricks汇总(AAAI2021)
最新CV竞赛:2021 高通人工智能应用创新大赛|CVPR 2021 | Short-video Face Parsing Challenge|3D人体目标检测与行为分析竞赛开赛,奖池7万+,数据集达16671张!

# CV技术社群邀请函 #

△长按添加极市小助手
添加极市小助手微信(ID : cvmart4)
备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
觉得有用麻烦给个在看啦~
