
9个技巧让你的PyTorch模型训练变得飞快!
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自|视觉算法


使用DataLoaders DataLoader中的workers数量 Batch size 梯度累计 保留的计算图 移动到单个 16-bit 混合精度训练 移动到多个GPUs中(模型复制) 移动到多个GPU-nodes中 (8+GPUs) 思考模型加速的技巧

from pytorch_lightning import Trainer
model = LightningModule(…)
trainer = Trainer()
trainer.fit(model)1.DataLoaders

dataset = MNIST(root=self.hparams.data_root, train=train, download=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in loader:
x, y = batch
model.training_step(x, y)
...2.DataLoaders中的workers的数量

# slow
loader = DataLoader(dataset, batch_size=32, shuffle=True)
# fast (use 10 workers)
loader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=10)3.Batch size


# clear last step
optimizer.zero_grad()
# 16 accumulated gradient steps
scaled_loss = 0
for accumulated_step_i in range(16):
out = model.forward()
loss = some_loss(out,y)
loss.backward()
scaled_loss += loss.item()
# update weights after 8 steps. effective batch = 8*16
optimizer.step()
# loss is now scaled up by the number of accumulated batches
actual_loss = scaled_loss / 16
accumulate_grad_batches=16:trainer = Trainer(accumulate_grad_batches=16)
trainer.fit(model)5.保留的计算图

losses = []
...
losses.append(loss)
print(f'current loss: {torch.mean(losses)'})
# bad
losses.append(loss)
# good
losses.append(loss.item())

# put model on GPU
model.cuda(0)
# put data on gpu (cuda on a variable returns a cuda copy)
x = x.cuda(0)
# runs on GPU now
model(x)
Trainer(gpus=1)。# ask lightning to use gpu 0 for training
trainer = Trainer(gpus=[0])
trainer.fit(model)
# expensive
x = x.cuda(0)# very expensive
x = x.cpu()
x = x.cuda(0)
# really bad idea. Stops all the GPUs until they all catch up
torch.cuda.empty_cache()
# enable 16-bit on the model and the optimizer
model, optimizers = amp.initialize(model, optimizers, opt_level='O2')
# when doing .backward, let amp do it so it can scale the loss
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
Trainer(precision=16)就可以了。trainer = Trainer(amp_level='O2', use_amp=False)
trainer.fit(model)8.移动到多个GPUs中
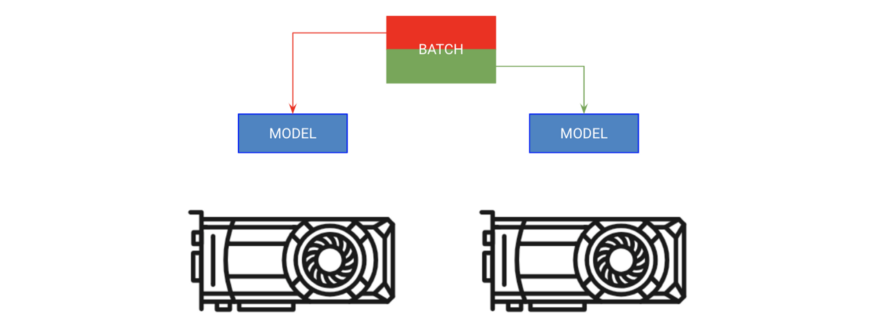
# copy model on each GPU and give a fourth of the batch to each
model = DataParallel(model, devices=[0, 1, 2 ,3])
# out has 4 outputs (one for each gpu)
out = model(x.cuda(0))
# ask lightning to use 4 GPUs for training
trainer = Trainer(gpus=[0, 1, 2, 3])
trainer.fit(model)
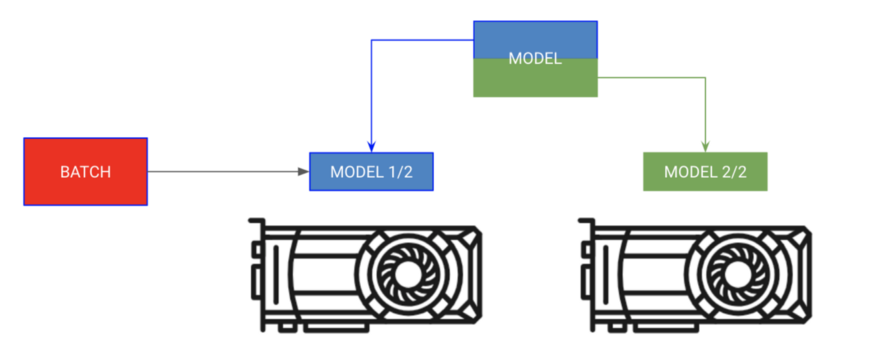
# each model is sooo big we can't fit both in memory
encoder_rnn.cuda(0)
decoder_rnn.cuda(1)
# run input through encoder on GPU 0
encoder_out = encoder_rnn(x.cuda(0))
# run output through decoder on the next GPU
out = decoder_rnn(encoder_out.cuda(1))
# normally we want to bring all outputs back to GPU 0
out = out.cuda(0)
class MyModule(LightningModule):
def __init__():
self.encoder = RNN(...)
self.decoder = RNN(...)
def forward(x):
# models won't be moved after the first forward because
# they are already on the correct GPUs
self.encoder.cuda(0)
self.decoder.cuda(1)
out = self.encoder(x)
out = self.decoder(out.cuda(1))
# don't pass GPUs to trainer
model = MyModule()
trainer = Trainer()
trainer.fit(model)
# change these lines
self.encoder = RNN(...)
self.decoder = RNN(...)
# to these
# now each RNN is based on a different gpu set
self.encoder = DataParallel(self.encoder, devices=[0, 1, 2, 3])
self.decoder = DataParallel(self.encoder, devices=[4, 5, 6, 7])
# in forward...
out = self.encoder(x.cuda(0))
# notice inputs on first gpu in device
sout = self.decoder(out.cuda(4)) # <--- the 4 here
如果模型已经在GPU上了,model.cuda()不会做任何事情。 总是把输入放在设备列表中的第一个设备上。 在设备之间传输数据是昂贵的,把它作为最后的手段。 优化器和梯度会被保存在GPU 0上,因此,GPU 0上使用的内存可能会比其他GPU大得多。
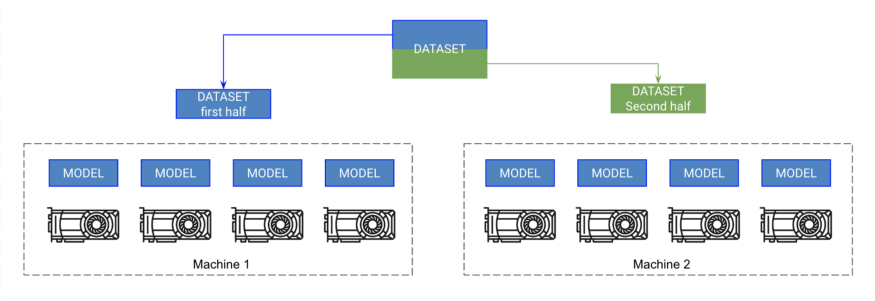
在每个GPU上初始化一个模型的副本(确保设置种子,让每个模型初始化到相同的权重,否则它会失败)。 将数据集分割成子集(使用DistributedSampler)。每个GPU只在它自己的小子集上训练。 在.backward()上,所有副本都接收到所有模型的梯度副本。这是模型之间唯一一次的通信。
def tng_dataloader():
d = MNIST()
# 4: Add distributed sampler
# sampler sends a portion of tng data to each machine
dist_sampler = DistributedSampler(dataset)
dataloader = DataLoader(d, shuffle=False, sampler=dist_sampler)
def main_process_entrypoint(gpu_nb):
# 2: set up connections between all gpus across all machines
# all gpus connect to a single GPU "root"
# the default uses env://
world = nb_gpus * nb_nodes
dist.init_process_group("nccl", rank=gpu_nb, world_size=world)
# 3: wrap model in DPP
torch.cuda.set_device(gpu_nb)
model.cuda(gpu_nb)
model = DistributedDataParallel(model, device_ids=[gpu_nb])
# train your model now...
if __name__ == '__main__':
# 1: spawn number of processes
# your cluster will call main for each machine
mp.spawn(main_process_entrypoint, nprocs=8)
# train on 1024 gpus across 128 nodes
trainer = Trainer(nb_gpu_nodes=128, gpus=[0, 1, 2, 3, 4, 5, 6, 7])
# train on 4 gpus on the same machine MUCH faster than DataParallel
trainer = Trainer(distributed_backend='ddp', gpus=[0, 1, 2, 3])
好消息,小白学视觉团队的知识星球开通啦,为了感谢大家的支持与厚爱,团队决定将价值149元的知识星球现时免费加入。各位小伙伴们要抓住机会哦!

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
评论