
让PyTorch训练速度更快,你需要掌握这17种方法

作者:LORENZ KUHN
机器之心编译
编辑:陈萍
掌握这 17 种方法,用最省力的方式,加速你的 Pytorch 深度学习训练。
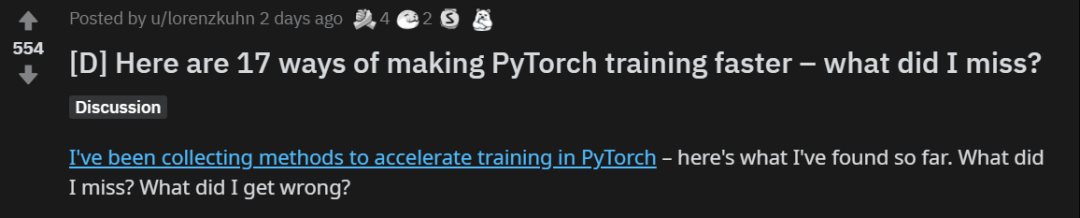
import torch# Creates once at the beginning of trainingscaler = torch.cuda.amp.GradScaler()for data, label in data_iter:optimizer.zero_grad()# Casts operations to mixed precisionwith torch.cuda.amp.autocast():loss = model(data)# Scales the loss, and calls backward()# to create scaled gradientsscaler.scale(loss).backward()# Unscales gradients and calls# or skips optimizer.step()scaler.step(optimizer)# Updates the scale for next iterationscaler.update()
model.zero_grad() # Reset gradients tensorsfor i, (inputs, labels) in enumerate(training_set):predictions = model(inputs) # Forward passloss = loss_function(predictions, labels) # Compute loss functionloss = loss / accumulation_steps # Normalize our loss (if averaged)loss.backward() # Backward passif (i+1) % accumulation_steps == 0: # Wait for several backward stepsoptimizer.step() # Now we can do an optimizer stepmodel.zero_grad() # Reset gradients tensorsif (i+1) % evaluation_steps == 0: # Evaluate the model when we...evaluate_model() # ...have no gradients accumulate

程序员GitHub,现已正式上线!
接下来我们将会在该公众号上,专注为大家分享GitHub上有趣的开源库包括Python,Java,Go,前端开发等优质的学习资源和技术,分享一些程序员圈的新鲜趣事。
年度爆款文案
点这里,获取腾讯课堂畅学卡

评论