
本文将使用OpenCV和立体视觉来赋予计算机这种深度知觉能力。
你是否曾经好奇过,为什么你带上特制的3D眼镜就可以体会到电影奇妙的立体效果?或者为什么闭上一只眼睛就很难抓住一个飞来的棒球?这都和立体视觉有关,它是我们利用双眼来感知深度的能力。这篇推送将使用OpenCV和立体视觉来赋予计算机这种深度知觉能力。我们将提供Python和C++代码。

上面这张动图中,一个很厉害的地方在于,这台计算机不仅能检测到不同的物体,而且还能标出它们有多远。这说明它能探测深度!在这段视频中,我们使用了OAK-D立体相机设置(OpenCV AI Kit-Depth)(外链)来帮助计算机感知深度。那么,什么是立体相机设备呢?我们如何用它来帮助计算机感知深度?这和立体视觉有什么关系呢?这篇推送将通过讲解对极几何和立体视觉的基本概念来解答上述问题。本文的大多数理论解释都来自于这本书:Multiple View Geometry in Computer Vision,作者是RichardHartley和Andrew Zisserman。这是讲解计算机视觉领域很多基本概念的一本非常著名的经典教材。本文是“空间AI技术简介系列”的第一部分,它将会提供很多基本概念的介绍,是理解本系列后续内容的基础。当我们用一张照片来捕捉(投影)一个三维物体时,我们实际上是把它从一个三维空间投影到了一个二维(平面)投影空间。这被称为平面投影。问题在于平面投影导致我们失去了深度信息。那么我们要如何还原深度呢?我们能仅仅用一张图像就算出一个场景的深度吗?让我们来看一个简单的例子: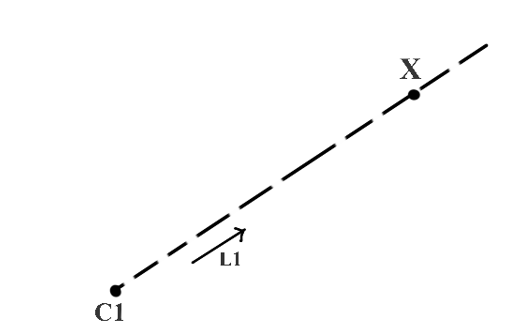
图1. 用一个三维空间中已知的点(C1)和一个方向向量(L1)来确定一个深度未知的三维空间中的点(X)在图1中,C1和X是三维空间中的点,单位向量L1给出了从C1到X射线的方向。现在,如果我们知道C1和单位向量L1的相关值,能够找到X的位置吗?从数学上来说,其实就是要解出下面等式中的X: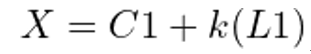
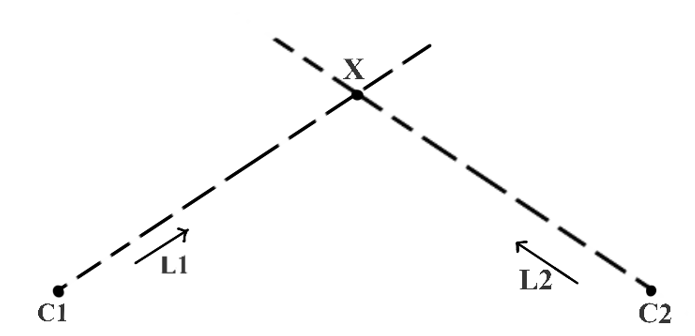
图2. 用两个三维空间中已知的点(C1和C2)以及方向向量(L1和L2)来定位三维空间中一个深度位置的点(X)——三角测量在图2中,我们新增了一个点C2,以及一个表示从C2到X的射线方向的向量L2。如果已知C2和L2,我们可以确定一个唯一的X吗?答案是肯定的!因为从C1和C2出发的射线显然相交于一点,也就是X。这被称为三角测量。也就是说,我们对点X进行了三角测量。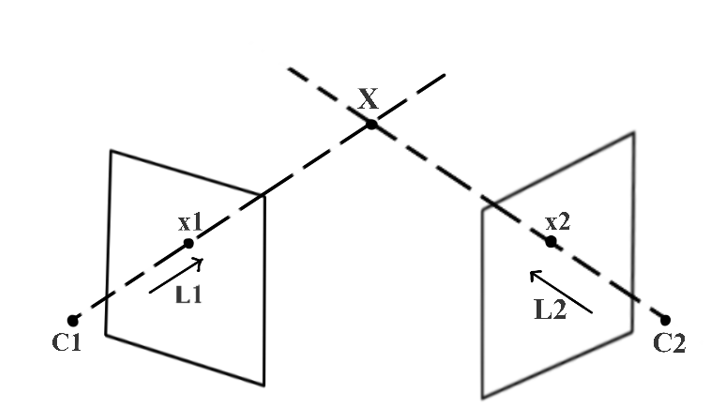
图3. 针对三维空间空间的一点(X),已知两个机位(C1和C2)和两个像素坐标(x1和x2),用拍出这点的两张图像来算出这点的深度,这个方法可以借用三角测量的概念来解释图3展示了当一个点(X)被捕捉(投影)到两张不同的图像中时,如何用三角测量来计算它的深度。在这张图中,C1和C2分别代表左、右两个相机在三维空间中的位置,它们是已知的。x1是左相机捕捉到的三维空间中点X的图像,而x2则是右相机捕捉到的。x1和x2被称作对应点,因为他们是同一个三维点点投影。我们用x1和C1确定L1,用x2和C2确定L2。这样我们就可以像图2那样用三角测量找出X。从上面的例子中,我们知道了根据两张不同角度的照片、用三角测量找到一个三维空间中的点,需要知道下面这些关键信息:注意,这只是计算一个三维点。我们如何通过两个不同机位的图像计算一个真实场景中的三维结构呢?一个显然的答案是,对图中的每一个点重复上述的过程。让我们更仔细地看看实操中的麻烦!
图4展示了从两个不同角度捕捉的一个现实场景。为了计算一个三维结构,我们试着找找前面提到的两个必要前提:1. 现实世界参考系中相机的位置(C1和C2)。为了简化计算三维点的问题,我们假定其中一个机位(C1或C2)是初始的。我们通过一种已知的标定模式标定双视系统来找到相机的位置,这个过程被称为立体相机标定。2. 计算场景中的每个三维点(X)的对应点(x1和x2)。我们将讨论很多优化对应点计算的方法,最后会理解对极几何将如何帮助我们简化这个问题。注意:两个相机的相对位置必须严格固定,只有这样捕捉到的图像,才能用立体相机标定处理。如果用一个相机从两个不同的位置捕捉图像,那么我们只能得到深度的比例。我们只能通过捕捉的场景中一些特别的几何信息,来找到绝对的深度。
图5展示了人工标注的对应点。我们人类很容易看出哪些点相互对应,但怎么让计算机做到这点呢?计算机视觉领域人们常用的一种方法叫做特征匹配。图6展示了用ORB特征标注器标出左图和右图之间相互匹配的特征。这是找到对应点(配对)的一种方法。
然而,我们观察到,具有已知点对应关系的像素数量与总像素数量的比率是最小的。这意味着我们将有一个非常稀疏的三维场景的重建。对于密集的重建,我们需要尽可能获得最大数量的像素的点对应关系。
找到点对应关系的一个简化方法是找到具有相似相邻像素信息的像素。在图7中,我们观察到,使用这种具有相似相邻信息的像素匹配方法,会导致一个图像中的单个像素在另一个图像中具有多个匹配。我们发现写一个算法来确定真正的匹配是有难度的。有什么方法可以减少我们的搜索空间吗?我们可以用一些定理来消除所有额外的错误匹配,减少不正确的点对应?我们在这里利用了对极几何学。所有这些解释和铺垫都是为了介绍对极几何的概念。现在我们将理解对极几何在减少点对应的搜索空间方面的重要性。
在图8中,我们假设有一个与图3类似的立体相机设备。一个三维点X被C1和C2的摄像机分别在x1和x2处捕获。由于x1是X的投影,如果我们试图从C1延伸出一条穿过x1的射线R1,它也应该穿过X。这条射线R1被捕获为线L2,而X在图像i2中被捕获为x2。由于X位于R1上,x2应该位于L2上。这样一来,x2的可能位置就被限制在一条线上,因此我们可以说,图像i2中对应于像素x1的像素的搜索空间被缩小到一条线L2。我们使用对极几何来寻找L2。现在是时候定义一些技术术语了!与X一起,我们也可以在各自的相反图像中投射出相机中心。e2是相机中心C1在图像i2中的投影,而e1是相机中心C2在图像i1中的投影。e1和e2的技术术语是“对极点”(epipole)。因此,在一个双视图的几何设置中,对极是一个视图的摄像机中心在另一个视图中的影像。连接两个摄像机中心的线被称为基线(baseline)。因此,对极也可以被定义为基线与图像平面的交点。图8显示,使用R1和基线,我们可以定义一个平面P。这个平面也包含X、C1、X1、X2和C2。我们称这个平面为对极平面(the epipolar plane)。此外,从对极平面和图像平面的交点得到的线被称为极线(the epipolar line)。因此,在我们的例子中,L2是一条极线。对于不同的X值,我们将有不同的对极平面,因此也有不同的极线。然而,所有的对极平面都相交于基线,而所有的极线都相交于对极。所有这些共同构成了对极几何。我们有了用基线B和射线R1构成的平面P。e1和e2是对极点,L2是极线。基于所给图像的对极几何,在图像i2中与像素x1相对应的像素的搜索空间被限制在一条二维线上,即极线L2。这就是所谓的极线约束。有没有一种方法可以用一个单一的矩阵来表示整个对极几何形状?此外,我们能否只用两张拍摄的图像来计算这个矩阵?好消息是,有这样一个矩阵,它被称为基本矩阵(the Fundamental matrix)。在接下来的两节中,我们首先理解投射几何和齐次表征的含义,然后尝试推导出基本矩阵的表达。最后,我们通过使用基本矩阵来计算极线和表征极线约束。我们如何在二维平面上表示一条直线?二维平面内直线的方程是ax + by + c = 0。随着a、b、c值的不同,我们在二维平面内得到不同的直线。因此,可以用一个矢量(a,b,c)来表示一条直线。假设我们有直线ln1定义为2x+3y+7=0,直线ln2定义为4x+6y+14=0。根据我们上面的讨论,l1可以用向量(2,3,7)表示,l2可以用向量(4,6,14)表示。我们可以很容易地说,l1和l2基本上代表了同一条线,而向量(4,6,14)基本上是向量(2,3,7)的缩放版本,缩放系数为2。因此,任何两个矢量(a,b,c)和k(a,b,c),其中k是一个非零比例常数,代表同一条线。这样的等价向量,只通过一个缩放常数就可以联系起来,形成一类齐次向量。矢量(a,b,c)是其各自等价矢量类的齐次表示。由(a,b,c)代表的所有等价类的集合,对于a=b=c=0以外的所有可能的实值,构成了投影空间。我们使用齐次坐标的齐次表示法来定义投影空间中的点、线、平面等元素。我们使用投影几何的规则来对投射空间中这些元素进行任何转换。在图3中,假设我们知道两台摄像机的投影矩阵,例如C1处的摄像机的P1和C2处的摄像机的P2。什么是投影矩阵?摄像机的投影矩阵定义了摄像机拍摄的三维世界坐标和其相应的像素坐标之间的关系。要了解更多关于相机投影矩阵的信息,请阅读这篇关于相机校准的文章。就像P1将三维世界坐标投射到图像坐标一样,我们定义P1inv,即P1的伪逆,这样我们可以定义从C1经过x1和X的射线R1为: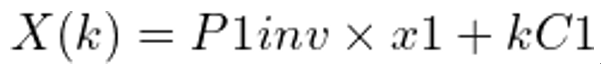
k是一个比例参数,因为我们不知道X与C1的实际距离。我们需要找到表极线Ln2来减少i2中对应于i1中像素x1的搜索空间,因为我们知道Ln2是i2中捕获的射线R1的图像。因此,为了计算Ln2,我们首先在射线R1上找到两个点,用P2将它们投射到图像i2中,并使用这两个点的投影图像来寻找Ln2。我们可以考虑的R1上的第一个点是C1,因为射线从这个点开始。第二个点可以通过保持k=0来计算。因此我们得到的点是C1和(P1inv)(x1)。使用投影矩阵P2,我们得到这些点在图像i2中的图像坐标分别为P2*C1和P2*P1inv*x1。我们还观察到,P2*C1基本上是图像i2中的外极e2。在投影几何学中,可以用两点p1和p2来定义一条线,只需找到它们的交积p1x p2。因此: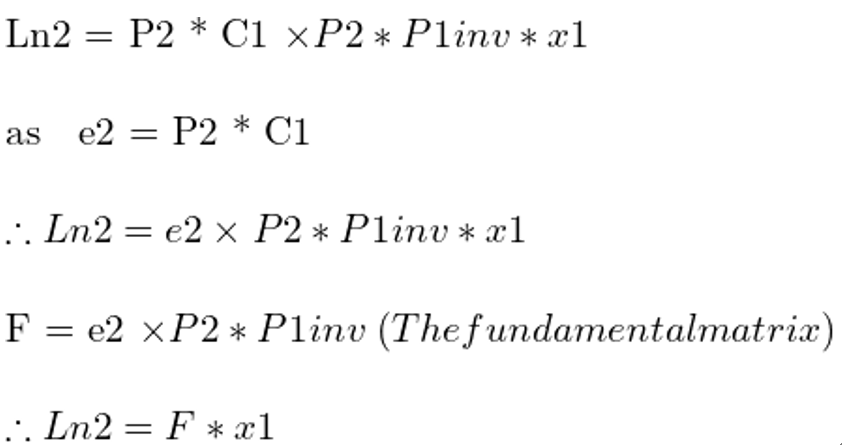
在投影几何学中,如果一个点x位于一条线L上,我们可以把它写成方程的形式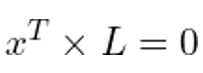
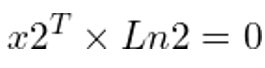
将Ln2的值从上式中替换出来,我们就得到了这个方程: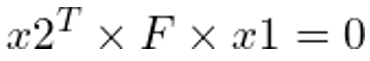
这是两个点x1和x2成为对应点的必要条件,也是一种极线约束的形式。因此,F代表了双视角系统的整体对极几何形状。由于x1和x2是方程中的对应点,如果我们能找到一些点的对应关系,使用ORB或SIFT等特征匹配方法,我们可以用它们来解决上述方程的F。OpenCV的findFundamentalMat()方法提供了各种算法的实现,如7点算法、8点算法、RANSAC算法和LMedS算法,以利用匹配的特征点计算基本矩阵。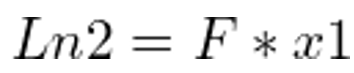
如果我们知道Ln2,我们就可以利用极点约束来限制我们对与像素x1对应的像素x2的搜索。我们一直在尝试解决对应问题。我们开始使用特征匹配,但我们观察到它导致了一个稀疏的三维结构,因为总像素中只有极小部分的点对应关系是已知的。然后,我们看到我们可以使用基于模板的搜索来寻找像素的对应关系。我们学习了如何利用对极几何学将点的对应关系的搜索空间减少到一条线——极线。我们能否进一步简化这个寻找密集点对应关系的过程呢?
图9. 上方的一对图像显示了特征匹配的结果,下方的一对图像显示了一幅图像中的一个点(左)和第二幅图像中位于各自极线上的相应点(右)

图10. 双视图几何的特殊情况。上方的一对图像显示了特征匹配的结果,下方的一对图像显示了一幅图像中的一个点(左)和第二幅图像中位于各自极线上的相应点(右)。(来源:2005 Stereo Dataset(外链))图9和图10显示了两对不同图像的特征匹配结果和极线的约束情况。这两张图在特征匹配和极线方面最明显的区别是什么?是的,你说对了!在图10中,匹配的特征点具有相等的垂直坐标。所有对应的点都有相等的纵坐标。图10中的所有极线都必须是平行的,并且与左图中的相应点具有相同的垂直坐标。那么,这有什么好的?正是如此!与图9的情况不同,不需要明确计算每条极线。如果左图中的像素位于(x1,y1),那么第二幅图像中相应的极线的方程就是y=y1。我们为左图中的每个像素搜索其在右图同一行中的相应像素。这是一个双视角几何学的特例,成像平面是平行的。因此,对极(一个相机拍摄的图像被另一个相机捕获)在无限远处形成。根据我们对对极几何的理解,极线在对极处相遇。因此,在这种情况下,由于对极在无限远处,我们的极线是平行的。真棒!这大大简化了密集点的对应问题。然而,我们仍然要对每个点进行三角测量。我们能不能把这个问题也简化呢?好吧,平行成像平面的特殊情况再一次给我们带来了好消息!它可以帮助我们应用立体视差。它类似于立体视像或立体视觉,是帮助人类感知深度的方法。让我们详细了解一下。下面的动图是用Middlebury立体数据集2005(外链)的图像生成的。它展示了相机的纯平移运动,使成像平面平行。你能分辨出哪些物体离相机更近吗?
我们可以清楚地说,底部的玩具牛比最上面一排的玩具更靠近相机。我们是如何做到这一点的呢?我们基本上可以看到物体在两幅图像中的移动。移位越多,物体就越近。这种偏移就是我们所说的视差(disparity)。我们如何利用它来避免计算深度时的三角测量?我们计算每个像素的差距(两个图像中像素的移动),并应用比例映射来寻找给定差距值的深度。这在图12中得到了进一步的论证。我们将使用OpenCV的StereoSGBM方法来编写代码,计算给定一对图像的视差图。StereoSGBM方法是基于[3]的。
图13. 左、右图为真实世界场景的图像和相应的真实世界场景的输出视差图像。(来源:2014 HighResolution Stereo Datasets [2])试着玩玩不同的参数,观察它们如何影响最终输出的视差图计算。关于StereoSGBM的详细解释将在随后的空间AI系列介绍中介绍。在下一篇文章中,我们将学习创建自己的立体相机设备并录制实时的视差图视频,我们还将学习如何将视差图转换成深度图。还将解释立体相机的一个有趣应用,但这是目前的一个惊喜!参考文献
[1] Richard Hartley and AndrewZisserman. 2003. Multiple View Geometry in Computer Vision (2nd. ed.).Cambridge University Press, USA.
[2] D. Scharstein, H. Hirschmüller, Y. Kitajima,G. Krathwohl, N. Nesic, X. Wang, and P. Westling. High-resolution stereodatasets with subpixel-accurate ground truth. In German Conference on PatternRecognition (GCPR 2014), Münster, Germany, September 2014.
[3] H. Hirschmuller, “Stereo Processingby Semiglobal Matching and Mutual Information,” in IEEE Transactions on PatternAnalysis and Machine Intelligence, vol. 30, no. 2, pp. 328-341, Feb. 2008, doi:10.1109/TPAMI.2007.1166.
原文标题:
Introductionto Epipolar Geometry and Stereo Vision
独家|OpenCV 1.1 Mat - 基本图像容器(附链接)
独家|OpenCV 1.3 矩阵的掩膜操作(附链接)
独家|OpenCV 1.5 利用OpenCV叠加(混合)两幅图像
独家|OpenCV 1.6 改变图像的对比度和亮度!
独家|OpenCV 1.7 离散傅里叶变换
独家|OpenCV 1.8 使用XML和YAML文件实现文件的输入/输出
独家|OpenCV 1.9 如何利用OpenCV的parallel_for_并行化代码(附代码)
独家|OpenCV 1.10 使用OpenCV实现摄像头标定
编辑:王菁
黄瑞迪,清华大学外国语言学及应用语言学硕士在读,本科毕业于清华大学外国语言文学系。对儿童如何利用环境中的数据迅速学会自己的母语非常感兴趣,同时也希望从纷繁复杂的数据中把握住关键点,让为信息所困的自己和人们不再迷茫。
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

