
视觉词袋模型简介
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
视觉单词袋是一种描述计算图像之间相似度的技术。常用于用于图像分类当中。该方法起源于文本检索(信息检索),是对NLP“单词袋”算法的扩展。在“单词袋”中,我们扫描整个文档,并保留文档中出现的每个单词的计数。然后,我们创建单词频率的直方图,并使用此直方图来描述文本文档。在“视觉单词袋”中,我们的输入是图像而不是文本文档,并且我们使用视觉单词来描述图像。
文字文档袋
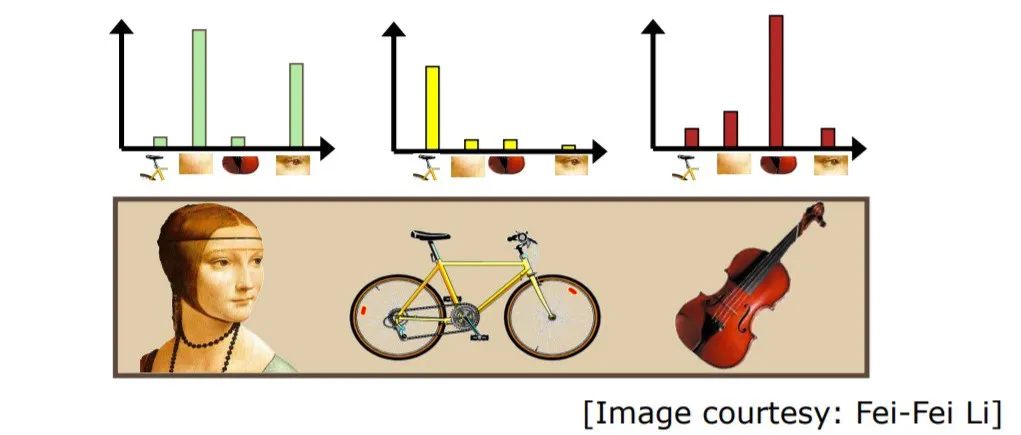
图像视觉词袋

视觉单词
在BovW中,我们将图像分解为一组独立的特征,特征由关键点和描述符组成,关键点与兴趣点是同一件事。它们某些是空间位置或图像中的点,这些位置定义了图像中的突出部分。它们受图像的旋转、缩放、平移,变形等等因素的影响。描述符是这些关键点的值(描述),而创建字典时所使用聚类算法是基于这些描述符进行的。我们遍历图像并检查图像中是否存在单词。如果有,则增加该单词的计数。最后我们为该图像创建直方图。
要创建字典,我们需要使用特征提取器(例如SIFT,BRISK等)。正如前面所描述的那样,这些技术检测图像中的关键点并为输入图像计算其值(描述符)。这些特征检测器返回包含描述符的数组。我们对训练数据集中的每个图像都执行此操作。
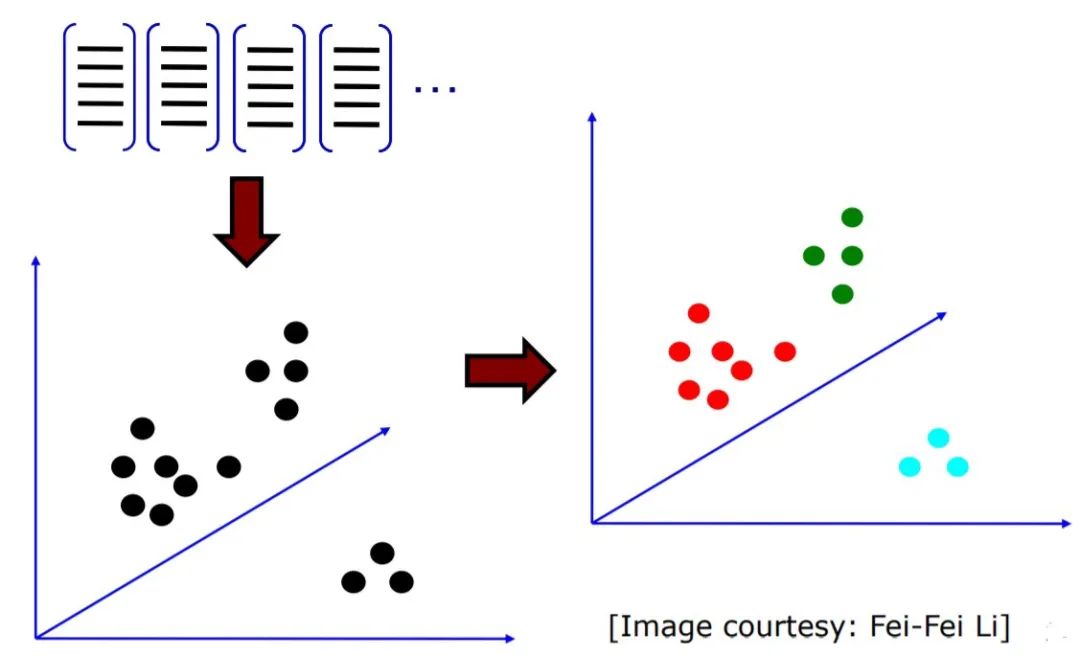
现在,假设我们将拥有N个(训练数据集中没有图像)数组。将这些数组垂直堆叠,使用类似与K-Means的聚类算法来形成K个聚类.K-Means将数据点分组为K个组,并将返回每个组的中心(见下图)。每个聚类的中心(质心)都充当一个视觉单词,所有这些K组的重心构成了我们的字典。
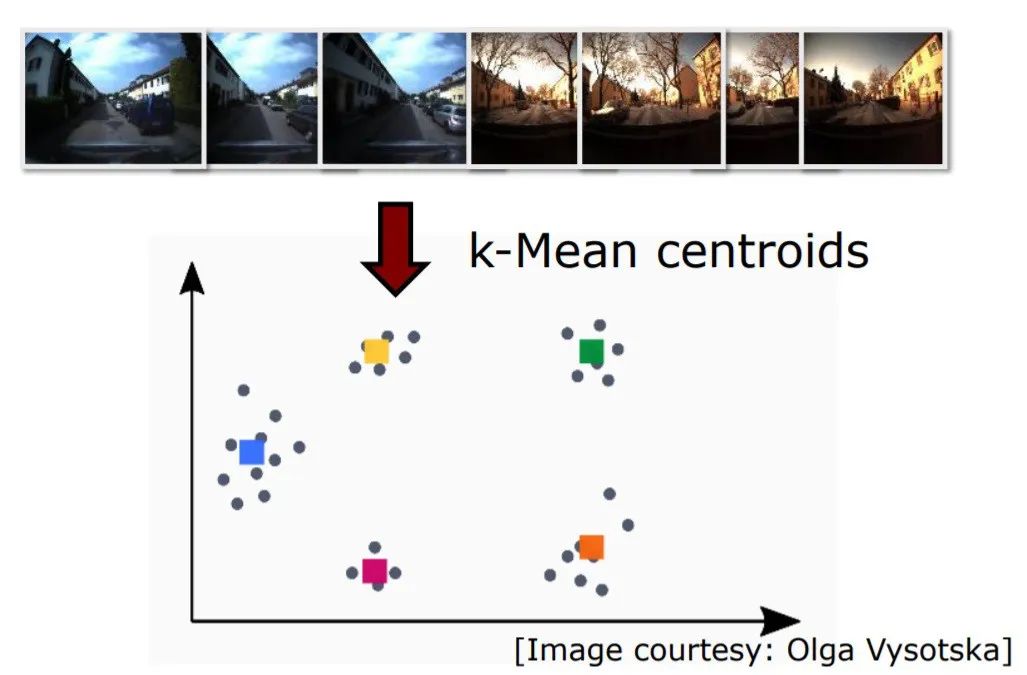
K均值聚类

检测视觉单词
现在我们将创建一个(N,K)的二维数组,我们将在接下来的几行中看到如何填充此数组。一旦检测到字典和图像中都存在一个单词,就会增加该特定单词的计数(即array [i] [w] + = 1,其中i是当前图像,w是该单词)。
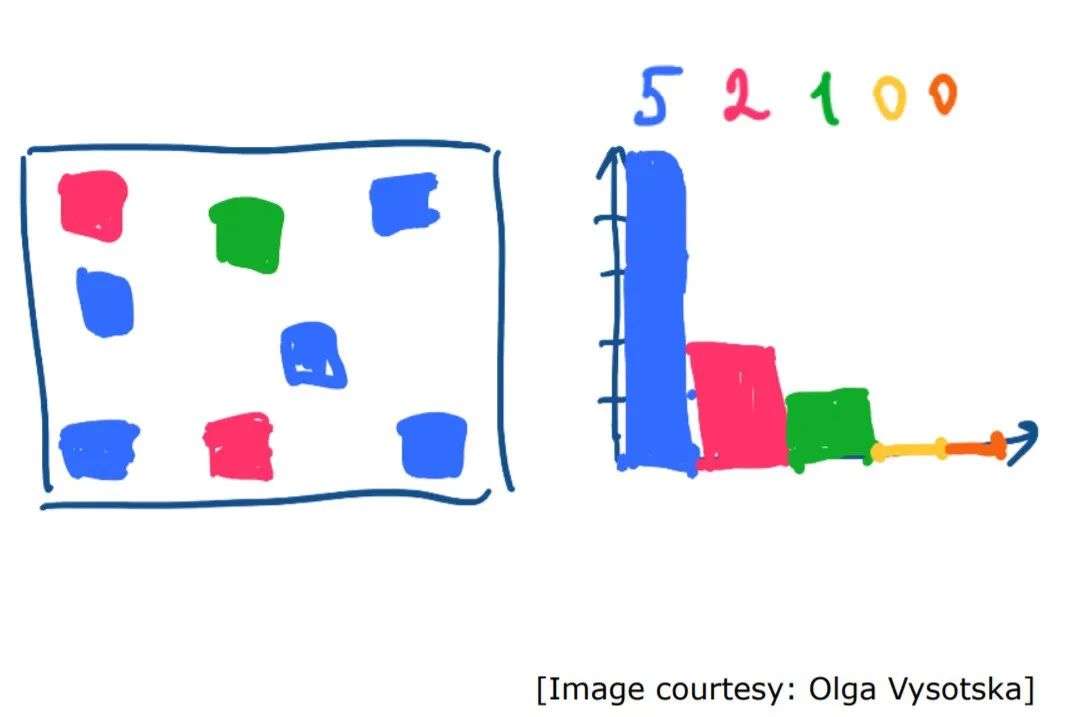
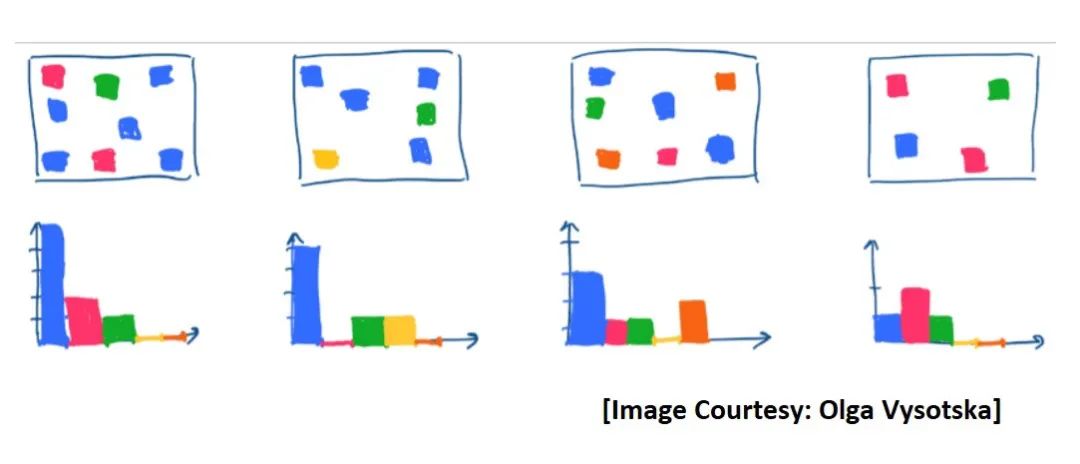
创建直方图
BoVW方法适用于捕获多细节的大型显微镜图像。但是,这种方法存在的问题是。当视觉单词出现在图像数据库的很多图像或每幅图像中时,就会导致一些并没有实际意义的单词的统计值较大。大家想想一个文本文档中像is,are之类的单词并没有多大帮助,因为它们几乎会出现在所有的文本当中。这些单词会导致分类任务变得更加困难。为了解决这个问题,我们可以使用TF-IDF(术语频率-逆文档频率)重加权方法。它可以对直方图的每个像素进行加权,来降低“非信息性”单词的权重(即,出现在许多图像/各处的特征),并增强了稀有单词的重要性。使用下图中给出的TF-IDF公式就可以计算出直方图中的每个单词的新权重。

TF-IDF加权
该公式清楚的表达了图像中每个的单词的重要性是如何定义的。
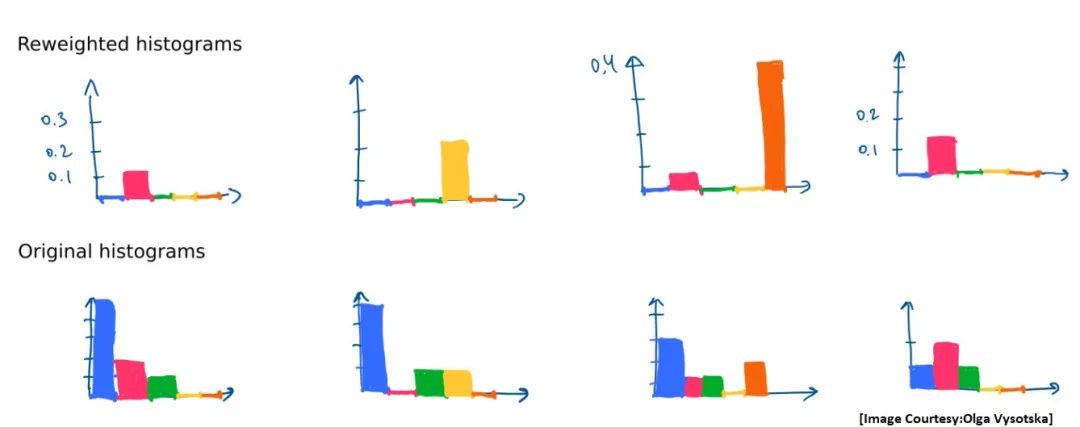
在经过加权之后的直方图中可以看出,蓝色单词的权重几乎为零。

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~