
计算机视觉方向简介:深度图补全
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
微软2010年发布了消费级RGB-D(RGB+depth)相机Kinect1,此后涌现了大量基于RGB-D相机的研究工作,比如用RGB-D相机来进行室内三维重建,比较有名的是KinectFusion、Kintinuous,ElasticFusion,InfiniTAM,BundleFusion等。此外,RGB-D相机还大量用于物体及人脸的三维建模、自动驾驶、增强现实、三维打印等。
目前主流的RGB-D相机有微软的Kinect系列,Intel的realsense系列,structure sensor(需结合iPad使用)等。去年iPhone X前置结构光深度相机(depth)面世后,更是激发了手机产业链深度相机的热潮,目前小米、OPPO、Vivo等手机大厂都在积极推动深度相机在手机上的应用。
虽然RGB-D相机前景无限,但是受制于物理硬件的限制,目前深度相机输出的depth图还有很多问题,比如对于光滑物体表面反射、半/透明物体、深色物体、超出量程等都会造成深度图缺失。而且很多深度相机是大片的深度值缺失,这对于算法工程师来说非常头疼。
因此,深度图补全一直是一个非常有用的研究方向,之前的文献大都只能补全比较小范围的深度缺失,对于较大深度值缺失的情况无能无力,本文介绍的是2018 CVPR 最新的一项研究deep depth completion,不受RGB-D相机类型的限制,只需要输入一张RGB加一张depth图,可以补全任意形式深度图的缺失。对于算法工程师来说真的是喜大普奔啊,目前主要针对的是室内环境。

Deep depth completion算法流程如下,其输入是RGB-D相机拍摄的一张RGB图像和对应的深度图,然后根据分别训练好的两个网络(一个是针对RGB图表面法线的深度学习网络,一个是针对物体边缘遮挡的深度学习网络),预测该彩色图像中所有平面的表面法线和物体边缘遮挡。最后用深度图作为正则化,求解一个全局线性优化问题,最终得到补全的深度图。
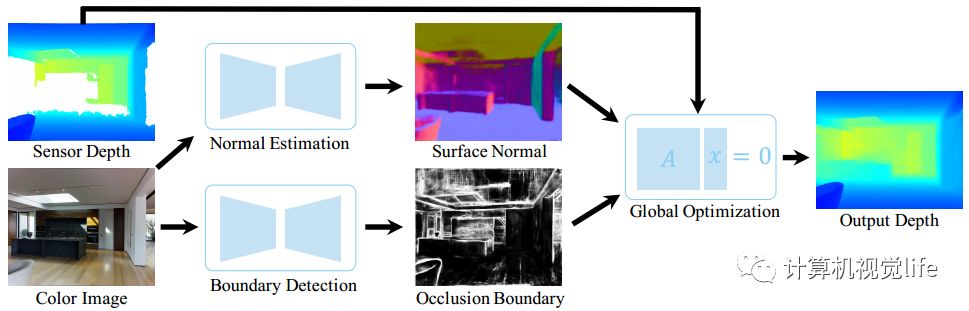
一切看起来顺理成章,但是,做深度学习的小伙伴们纷纷举起了小手,开始提问:我的训练集怎么搞?我去哪里找大量的高精度已经补全的深度图?
的确,这是个大问题,消费级深度相机拍摄的深度图本身就是缺失的,没办法作为深度图的groundtruth,但是现有的RGB-D数据集几乎都是基于消费级深度相机的。而使用高精度的深度相机不仅设备费用成本高,时间成本也非常高,give up吧。
这里要夸一下本文的作者,聪明又勤奋,还乐于奉献。他们之间提供了一个已经补全好深度图的RGB-D数据集,包含105,432幅RGB-D图,而且给你都对齐了的。那他们是怎么做到的?
主要是因为他们聪明。对,你没看错!他们利用现有的消费级RGB-D相机拍摄的数据集(Matterport3D、ScanNet、SUN3D、SceneNN)先进行稠密的三维重建,然后再进行优化和渲染。虽然单一视角的深度图可能会有因为不同原因引起的缺失,但是经过多个不同视角的重建和优化,这些缺失的地方都被填补了。然后将其深度结果反投影回到输入深度图。最后得到的深度图就是groundtruth啦,简直完美!省时省力省钱,还顺带学习了稠密三维重建,就是这么棒!看看下面的图,还是比较形象的,黄色代表不同视点的图,红色是当前视点渲染后的深度图。

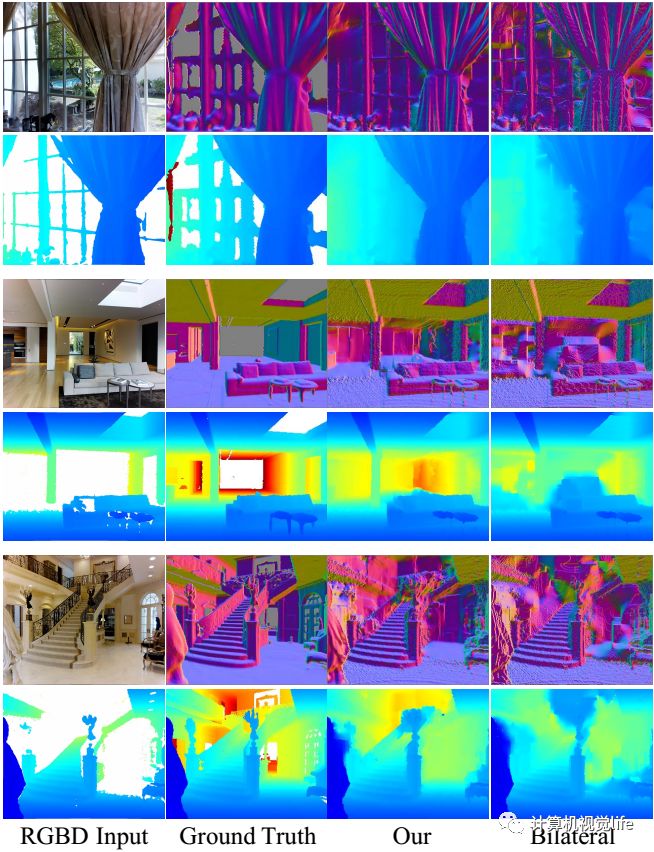
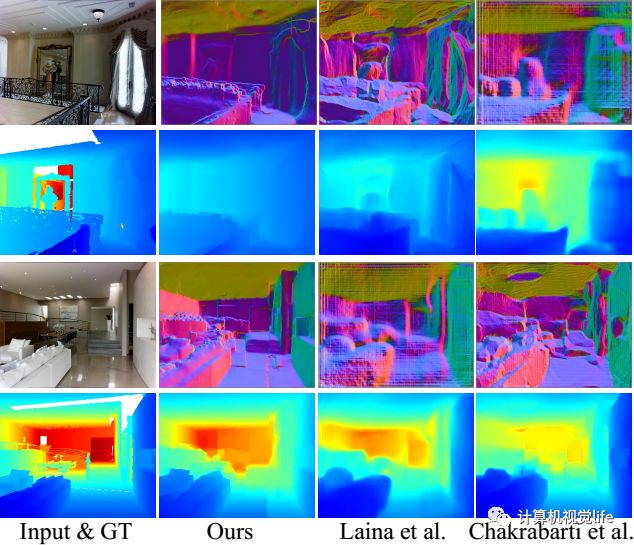
亲自测试,效果杠杠滴!具体的量化比较就不放了,可以查看论文,目前效果是该领域最好的,我这里只放几张比较直观的视觉效果的比较结果。
首先是和联合双边滤波的inpainting方法进行比较,如下所示,可以明显看出边缘信息保存的很好,噪点也很少。
再看一下和深度神经网络深度估计方法的对比,如下图所示。不仅深度值更准确,大尺度的几何结构也更准确。
来看一下点云结果对比吧,原始的RGB-D生成的点云结果如下:
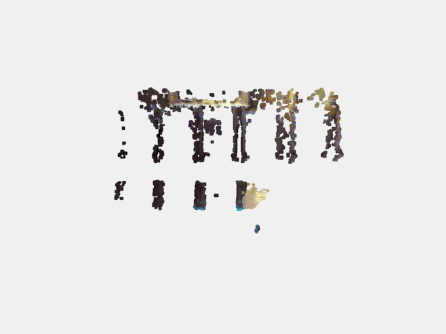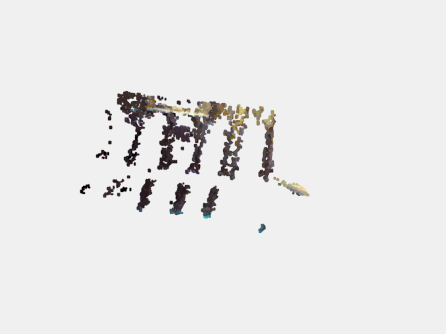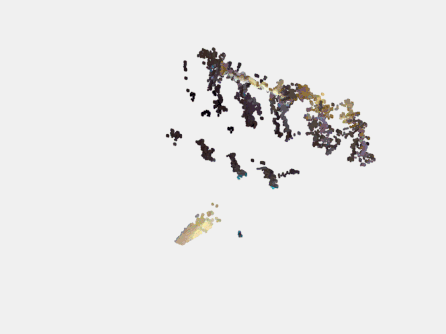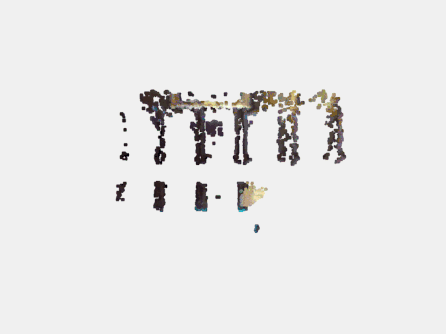
经过深度图补全后生成的点云结果如下:

运行速度怎么样?
学术界对运行速度不是特别关注,但是产业界就是死死的盯住运行速度不放,因为这直接关系到能否直接用在嵌入式设备上。
他的运行速度是这样的:
实验环境:对于一幅320x256的RGB-D输入图来说,用NVIDIA TITAN X GPU预测表面法线和边界遮挡需要0.3s。在Intel Xeon 2.4GHz CPU上求解线性方程需要1.5秒。
虽然慢了点,但是也给算法优化的同志们留了一个不大不小的挑战,不是吗?
良心的作者不仅给了数据集,还开源了代码,还给了训练好了结果,如此良心负责人的作者必须给个大大的点赞!
项目地址:
http://deepcompletion.cs.princeton.edu/
开源代码地址:
https://github.com/yindaz/DeepCompletionRelease
本文仅做学术分享,如有侵权,请联系删文。