
ICLR2022 ViDT | 检测超越YOLOS,实例分割超越SOLOv2,同时达到实时!!!


Transformers被广泛应用于许多视觉问题,特别是视觉识别和检测。Detection Transformers是第一个完全端到端的目标检测学习系统,而Vision Transformers是第一个完全基于Transformer的图像分类体系结构。在本文中,整合
Vision和DetectionTransformers(ViDT)来构造一个有效且高效的目标检测器。ViDT引入了一个重新设计的注意力模块,将最近的Swin Transformer扩展为一个独立的目标检测器,然后是一个计算高效的Transformer解码器,利用多尺度特征和辅助技术,在不增加太多计算负载的情况下提高检测性能。此外,将
ViDT扩展到ViDT+,以支持联合任务学习的目标检测和实例分割。具体地说,附加了一个高效的多尺度特征融合层,并利用另外两个辅助训练损失,IoU-aware loss和token labeling loss。在Microsoft COCO基准数据集上的大量评估结果表明,
ViDT在现有的完全基于Transformer的目标检测器中获得了最好的AP和延迟权衡,其扩展的ViDT+由于其对大型模型的高可伸缩性,实现了53.2AP。
1Vision And Detection Transformers
ViDT首先重新配置Swin Transformer的注意力模型,以支持独立的目标检测,同时完全重用Swin Transformer的参数。接下来,它结合了一个Encoder-free neck layer来利用多尺度特征和两种基本技术:Auxiliary decoding loss和Iterative Box Refinement。
Reconfigured Attention Module(RAM)
将Swin Transformer的Patch reduction和Local attention方案应用于序列到序列的范例是具有挑战性的,因为:
[DET] token的数量必须保持在fixed-scale上[DET] token之间缺乏局部性
为了解决这些问题,作者引入了一个重新配置的注意力模块(RAM),它将与[PATCH]和[DET] token相关的单个全局注意力分解为3个不同的注意力,即[PATCH]×[PATCH],[DET]×[DET]和[DET]×[PATCH]注意力。
基于分解,Swin Transformer的有效方案只适用于[PATCH]×[PATCH]注意力,这是计算复杂度最高的部分,不破坏对[DET] token的两个约束。如图3所示,通过共享[DET]和[PATCH] token的投影层,这些修改完全重用了Swin Transformer的所有参数,并执行3个不同的注意力操作。
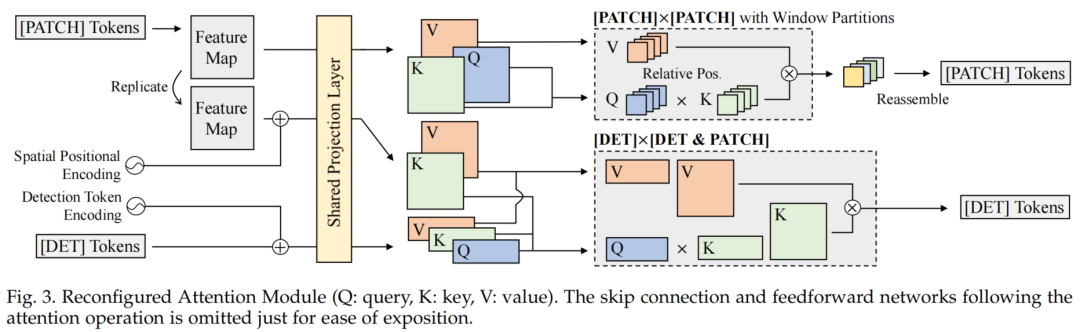
作为一个独立的目标检测器,RAM必须伴随3个注意力操作:
[PATCH]×[PATCH] Attention
初始的
[PATCH] token在Attention层之间逐步校准,使它们根据Attention权重聚合全局特征图中的关键内容(即[PATCH] token的空间形式)。对于[PATCH]×[PATCH]Attention,Swin Transformer对每个窗口分区都进行局部注意力计算,其连续块的移位窗口分区会连接上一层的窗口,提供分区之间的连接以获取全局信息。使用类似的策略来生成分层的
[PATCH] token。因此,每个阶段[PATCH] token的数量减少4倍;特征图的分辨率从H/4×W/4下降到H/32×W/32,总共经过4个阶段,其中H和W分别表示输入图像的宽度和高度。
[DET]×[DET] Attention
与YOLOS类似,添加了100个可学习的
[DET] token作为Swin Transformer的额外输入。由于[DET] token的数量指定了要检测目标的数量,它们的数量必须在Transformer层上以固定的规模进行维护。此外,
[DET] token与[PATCH] token不同,没有任何局部性。因此,对于[DET]×[DET]Attention,在保持其数量的同时进行全局自注意力;这种注意力帮助每个[DET] token通过捕获它们之间的关系来定位不同的目标。
[DET]×[PATCH] Attention
考虑到
[DET]和[PATCH] token之间的交叉注意力,并为每个[DET] token对象生成一个嵌入。对于每个[DET] token,[PATCH] token中的关键内容被聚合以表示目标对象。由于[DET] token指定了不同的目标,它为图像中的不同目标生成不同的目标嵌入。如果没有交叉注意力,就无法实现独立的目标检测。如图3所示,ViDT绑定[DET]×[DET]和[DET]×[PATCH]注意力处理它们以提高效率。
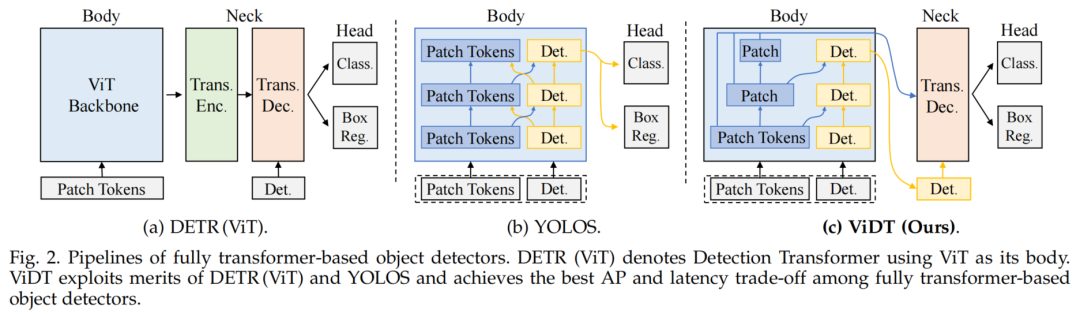
作者将Swin Transformer中的所有注意力模块替换为RAM,它接收[PATCH]和[DET] token(如图2(c)的“body”所示),然后通过并行执行3种不同的注意力操作来输出经过校准的新token。
位置编码
对于不同类型的注意力,
ViDT采用不同的位置编码:
对于
[PATCH]×[PATCH] Attention,使用最初在Swin Transformer中使用的相对位置偏差。对于
[DET]×[DET] Attention,[DET] token添加了可学习的位置编码,因为[DET] token之间没有特定的顺序。对于
[DET]×[PATCH] Attention,向[PATCH] token注入了基于正弦的空间位置编码,因为Transformer中的permutation-equivariant忽略了特征图的空间信息。
使用[DET]×[PATCH] Attention
在
[DET]和[PATCH] token之间应用交叉注意力会给Swin Transformer增加额外的计算开销,特别是当它在底层被激活时带来了大量的[PATCH] tokens。为了最小化这种计算开销,
ViDT只在Swin Transformer的最后阶段(金字塔的顶层)激活交叉注意力,该阶段由2个Transformer层组成,输入token大小为H/32 × W/32的[PATCH] token。因此,除了最后一个阶段,其余阶段只对[DET]和[PATCH] token进行自注意力操作。
绑定[DET]×[DET] Attention和[DET]×[PATCH] Attention
在这项工作中,
[DET]×[DET] Attention和[DET]×[patch] Attention产生了新的[DET] token,它们分别聚合了[DET] token和[PATCH] token中的相关内容。因为2个注意力模块共享完全相同的
[DET] query embedding,投影如图3所示,可以通过对和Embedding执行矩阵乘法,其中Q,K是key和query,[·]是concat。然后,将得到的注意力映射应用于
Embedding,其中V为value,d为Embedding维数,

[DET] token Embedding的维度
在
ViDT中,[DET]×[DET] Attention贯穿于每个阶段,[DET] token的Embedding维度与[PATCH] token一样逐渐增加。对于一个[PATCH] token,它的嵌入维度通过在网格中concat附近的[PATCH] token来增加。然而,这种机制不适用于
[DET] token,因为ViDT需要维护相同数量的[DET] token来检测场景中固定数量的目标。因此,只需沿着嵌入维度重复多次[DET] token以增加其大小。这使得[DET] token可以重用Swin Transformer中的所有投影和规范化层,而无需任何修改。
Encoder-free Neck Structure
为了利用多尺度特征映射,ViDT集成了一个多层可变形的Transformer解码器。在DETR系列中(图2(a)),Neck需要一个Transformer编码器,将从图像分类Backbone提取的特征转换为适合目标检测的特征;
编码器通常是计算昂贵的,因为它涉及[PATCH]×[PATCH] Attention。然而,ViDT只维护一个Transformer解码器作为它的Neck,因为带有RAM的Swin transformer作为独立的目标检测器可以直接提取适合目标检测的细粒度特征。因此,ViDT的Neck结构具有很高计算效率。
解码器接收来自具有RAM的Swin transformer的2个输入:
每个阶段生成的 [PATCH] token,最后一个阶段生成的 [DET] token
如图2(c)中的Neck所示在每个可变形的Transformer层中,[DET]×[DET] Attention是在最前面的。对于每个[DET] token,应用多尺度可变形的注意力来聚合从多尺度特征映射中采样的一小部分关键内容,以产生一个新的[DET] token,
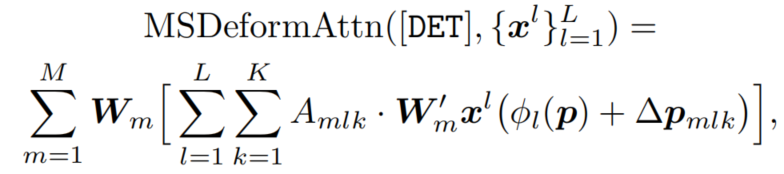
其中,m表示注意力头,K为内容聚合的采样key总数。此外,是为第级特征图重新缩放的[DET] token的参考点,而是可变形注意力的采样偏移量;而是K个采样内容的注意力权值。和是多头注意力的投影矩阵。
附加改进的辅助技术
ViDT的解码器遵循多层transformer的标准结构,在每一层生成细化的[DET] token。因此,ViDT利用在(可变形)DETR中使用的2种辅助技术来进行额外的改进:
Auxiliary Decoding Loss 检测头由2个用于框回归和分类的前馈网络组成,分别附着在每个解码层上。将不同尺度下检测头的训练损失相加。这有助于模型输出正确的对象数量,而无需非最大抑制。
Iterative Box Refinement 每个解码层根据来自前一层检测头的预测来细化边界框。因此,边界框回归过程需要通过解码层逐步Refinement。
这2种技术对于基于transformer的目标检测器至关重要,因为它们在不影响检测效率的情况下显著提高了检测性能。
2ViDT+
前面所提出的ViDT显著提高了端到端transformer检测器的计算复杂度和性能。此外,还分析了ViDT的2个缺点:
多尺度 [PATCH] token线性融合,无法提取复杂的互补信息;ViDT不适用于其他任务,如实例分段。
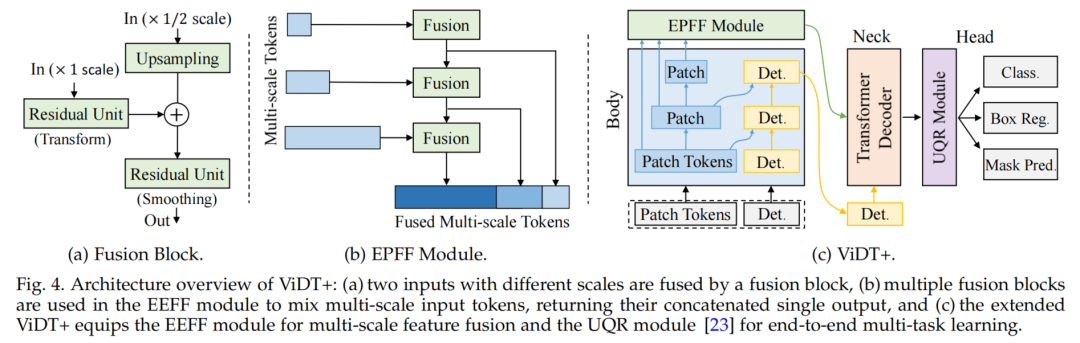
解决这两个问题并非易事。对于前者,需要开发一种不影响推理速度的非线性融合特征的有效方法。对于后者,现有的用于DETR族检测器的fpn型网络不能以端到端方式进行多任务学习。作者通过添加3个组件来解决这些缺陷,即Efficient Pyramid Feature Fusion(EPFF)、Unified Query Representation(UQR)以及IoU-aware and Token Labeling Losses。合并3个组件的方法称为ViDT+,如图4(c)所示。
Efficient Pyramid Feature Fusion Module
所有ViDT的多尺度[PATCH] token都不经过任何处理,直接送入ViDT的Encoder-free Neck组件。然后,[PATCH] token被解码为目标嵌入,即最终的[DET] token。如公式(2)所示,解码器的多尺度可变形注意力通过加权聚合线性融合多尺度[PATCH] token,但为了提高计算效率,只使用少量采样的[PATCH] token(每个尺度K个token)。
因此,引入了一个简单但高效的金字塔特征融合(EPFF)模块,该模块在将所有可用的多尺度token放入解码器之前,使用多个CNN融合块非线性融合所有可用的多尺度token,如图4(a)和4(b)所示。该方法比以往的简单线性聚合方法更有效地从不同尺度的特征映射中提取互补信息。
具体来说,将来自Body不同阶段的所有多尺度[PATCH] token集合起来,形成通道维数4大小相同的多尺度特征图。随后,它们以自顶向下的方式融合。图4(a)中的每个融合块接收2个用于金字塔特征融合的输入特征图:
用于目标l级(高分辨率)的特征图
feature map (较低分辨率)的前一个融合块的融合feature map

其中,Upsample算子通过双线性插值调整低分辨率特征映射的大小与高分辨率特征映射融合,2个ResUnits分别作为特征变换和特征平滑的Bottleneck Residual Block。结果得到融合的多尺度特征,沿空间维数flattened,并将所有尺度的特征拼接起来作为Neck decoder的输入,如图4(b)所示。该模块只增加了1M的参数,在不影响推理速度的前提下,大大提高了检测和分割的准确性。
Unified Query Representation Module
目标检测有助于多任务学习和实例分割的联合监督。因此,在预测头的开头添加了Unified Query Representation Module,如图4(c)的右侧所示。
但是,基于detr方法的[DET] token只对应于要检测的目标。因此,[DET] token无法转换为2D分割任务,使得基于detr的方法无法同时执行目标检测和实例分割任务。
为了解决这个问题,Dong等人提出了UQR模块,该模块利用离散余弦变换(DCT)将每个目标的GT二维二进制Mask变换到频域,生成每个目标的GT Mask向量进行预测。给定一个GT Mask S,对中的低频分量进行采样,对一个GT Mask向量v进行编码,其中A为变换矩阵。
最终的[DET] token直接使用FFN来预测GT Mask向量,该FFN输出预测的Mask向量。该过程与分类和bbox回归的多任务学习并行进行。
因此,联合监督的整体损失函数可以表述为,其中是实例分割任务的系数。另外,在求值和测试时,通过反采样和变换,可以将预测的Mask向量转换为估计的二维二进制Mask S,其中为的反采样结果。
IoU-aware and Token Labeling Losses
对于密集预测任务,当适当地合并多个独立目标时,该模型可以捕获所提供输入的更多不同方面。因此,引入了2个额外的训练目标函数,即IoU-aware Loss和Token Labeling Loss,最终使用提出的ViDT+模型获得可观的性能收益。
注意,它们在测试时不会降低模型推理的速度,因为它们只在训练时被激活。
IoU-aware Loss
直接使用最终的[DET] token预测IoU分数有助于提高检测的可信度,减轻预测与GT框之间的不匹配。因此,添加一个新的FFN分支来预测预测边界框和GT 之间的IoU得分;
IoU-aware loss为:
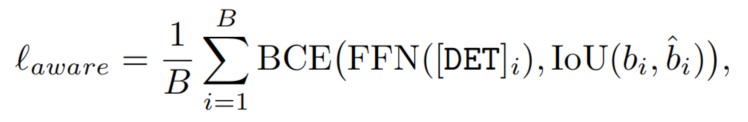
其中是与第i个目标对应的最终[DET] token(从Neck解码器返回);
Token Labeling Loss
Token Labeling允许解决多个token级别的识别问题,方法是为每个[PATCH] token分配一个由机器注释器生成的特定位置的监督。在这里,利用GT Mask为每个[PATCH] token分配特定于位置的类标签。首先,对GT Mask进行插值,使其与Backbone第阶段生成的特征映射的分辨率对齐;
Token Labeling Loss为:

其中是Backbone第阶段的特征映射中的第i个[PATCH] token,返回与 token相对应的token级 soft label;和是特征映射中的比例和 token的数量,Focal是Focal Loss,FFN是分类层。
3实验
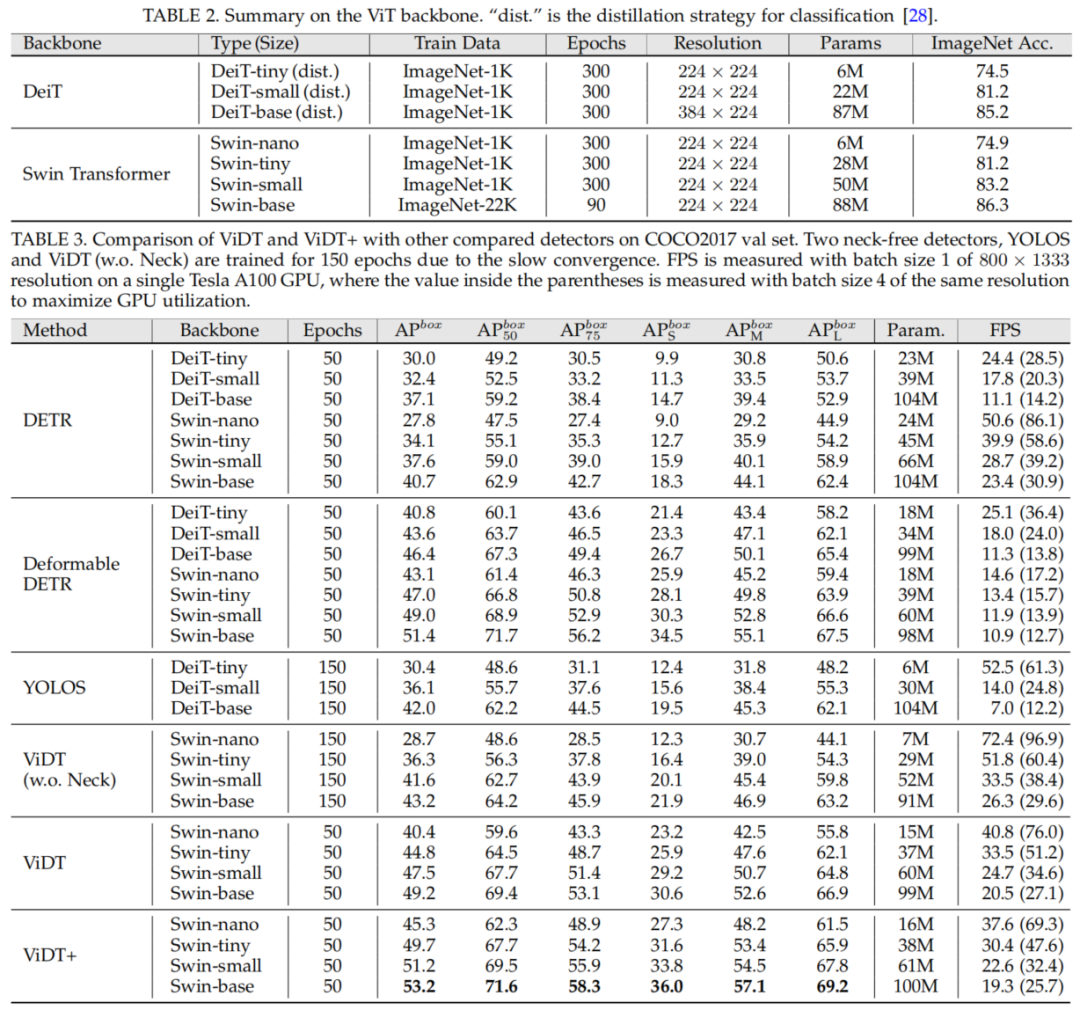
目标检测SOTA对比
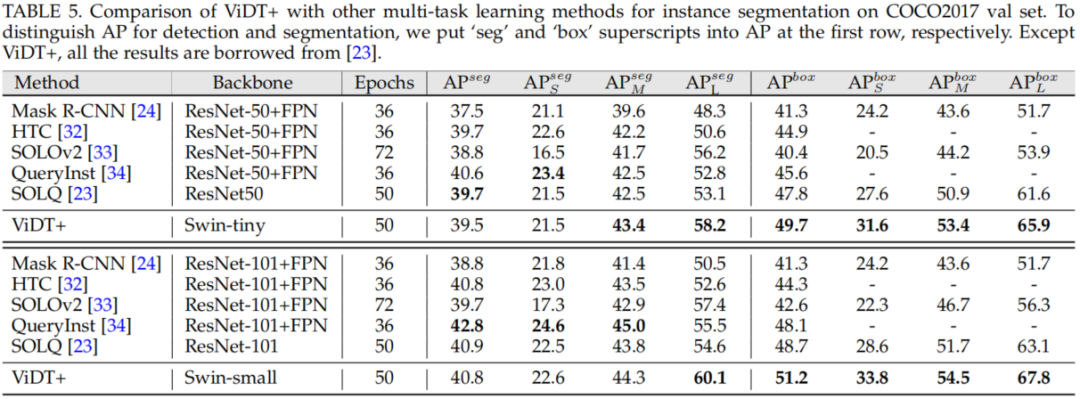
实例分割SOTA对比
4参考
[1].An Extendable, Efficient and Effective Transformer-based Object Detector
5推荐阅读
CenterNet++ | CenterNet携手CornerNet终于杀回来了,实时高精度检测值得拥有!
YOLOv5永不缺席 | YOLO-Pose带来实时性高且易部署的姿态估计模型!!!
Transformer崛起| TopFormer打造Arm端实时分割与检测模型,完美超越MobileNet!
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
