
百行代码入手数据挖掘竞赛~
数据及背景
给定实际业务中借款人信息,邀请大家建立风险识别模型,预测可能拖欠的借款人。
实践&数据下载地址:https://challenge.xfyun.cn/topic/info?type=car-loan&ch=dw-sq-1
实践代码
Baseline采用LightGBM模型,进行了必要的注释和代码实现,分数为0.58左右。
## 导入第三方包
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import KFold
from sklearn.metrics import f1_score, roc_auc_score
import warnings
warnings.filterwarnings('ignore')
## 读取数据集,具体下载方式可见操作手册
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
sample_submit = pd.read_csv('sample_submit.csv')
## 训练数据及测试数据准备
all_cols = [f for f in train.columns if f not in ['customer_id','loan_default']]
x_train = train[all_cols]
x_test = test[all_cols]
y_train = train['loan_default']
## 作为baseline部分仅使用经典的LightGBM作为训练模型,我们还能尝试XGBoost、CatBoost和NN(神经网络)
def cv_model(clf, train_x, train_y, test_x, clf_name='lgb'):
folds = 5
seed = 2021
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
train = np.zeros(train_x.shape[0])
test = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt',
'objective': 'binary',
'metric': 'auc',
'min_child_weight': 5,
'num_leaves': 2 ** 7,
'lambda_l2': 10,
'feature_fraction': 0.9,
'bagging_fraction': 0.9,
'bagging_freq': 4,
'learning_rate': 0.01,
'seed': 2021,
'nthread': 28,
'n_jobs':-1,
'silent': True,
'verbose': -1,
}
model = clf.train(params, train_matrix, 50000, valid_sets=[train_matrix, valid_matrix], verbose_eval=500,early_stopping_rounds=200)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
train[valid_index] = val_pred
test += test_pred / kf.n_splits
cv_scores.append(roc_auc_score(val_y, val_pred))
print(cv_scores)
print("%s_scotrainre_list:" % clf_name, cv_scores)
print("%s_score_mean:" % clf_name, np.mean(cv_scores))
print("%s_score_std:" % clf_name, np.std(cv_scores))
return train, test
lgb_train, lgb_test = cv_model(lgb, x_train, y_train, x_test)
## 预测结果
sample_submit['loan_default'] = lgb_test
sample_submit['loan_default'] = sample_submit['loan_default'].apply(lambda x:1 if x>0.25 else 0).values
sample_submit.to_csv('baseline_result.csv', index=False)
上分策略
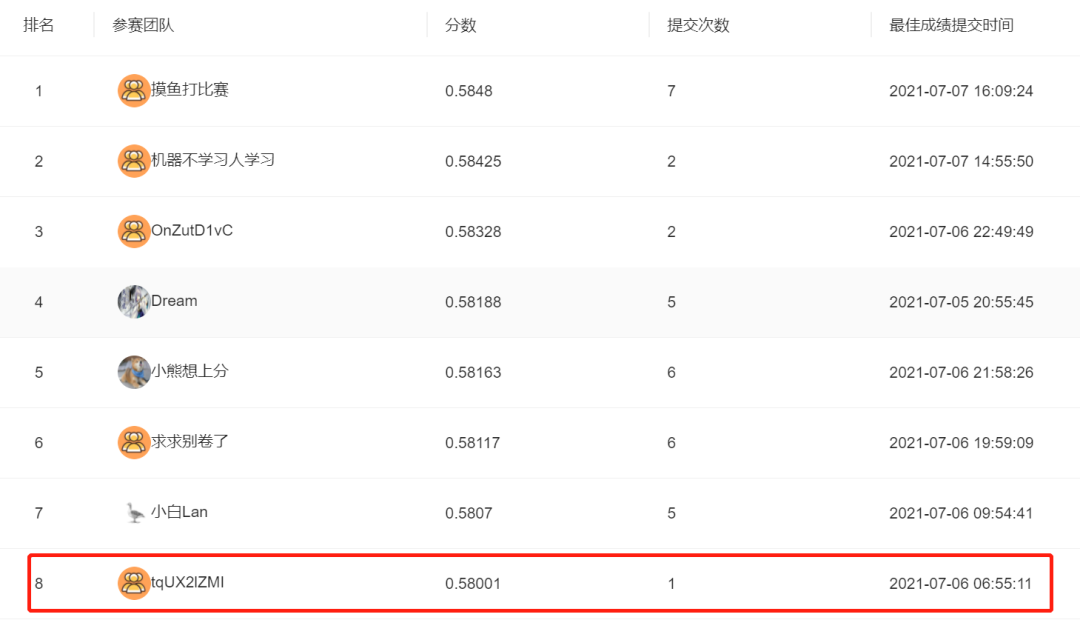
上述Baseline是一个较为简单的Baseline,试跑排名第8。如果想常挂榜首,需要考虑持续优化,这里给出几种方法:
本代码实践仅使用了赛题原始的特征,并没有进行过多的特征工程,这里还是很值得优化,并且相信会有很多提升点。特征工程对比赛结果的影响非常大,这里给出常见的几种特征工程操作的介绍:特征交互、特征编码和特征选择。
特征交互
交互特征的构造非常简单,使用起来却代价不菲。如果线性模型中包含有交互特征时,那它的训练时间和评分时间就会从 O(n) 增加到 O(n2),其中 n 是单一特征的数量。
特征和特征之间组合
特征和特征之间衍生
特征编码
one-hot编码
label-encode编码
特征选择
特征选择技术可以精简掉无用的特征,以降低最终模型的复杂性,它的最终目的是得到一个简约模型,在不降低预测准确率或对预测准确率影响不大的情况下提高计算速度。
特征选择不是为了减少训练时间(实际上,一些技术会增加总体训练时间),而是为了减少模型评分时间
2. 进行参数优化
对于模型的参数部分baseline部分并没有进行过多的优化和实验,当然这也是个比较大的优化的,下面给出几种调参的参考方法。
贪心调参
先使用当前对模型影响最大的参数进行调优,达到当前参数下的模型最优化,再使用对模型影响次之的参数进行调优,如此下去,直到所有的参数调整完毕。
网格调参
sklearn 提供GridSearchCV用于进行网格搜索,只需要把模型的参数输进去,就能给出最优化的结果和参数。相比起贪心调参,网格搜索的结果会更优,但是网格搜索只适合于小数据集,一旦数据的量级上去了,很难得出结果。
贝叶斯调参
给定优化的目标函数(广义的函数,只需指定输入和输出即可,无需知道内部结构以及数学性质),通过不断地添加样本点来更新目标函数的后验分布(高斯过程,直到后验分布基本贴合于真实分布)。简单的说,就是考虑了上一次参数的信息,从而更好的调整当前的参数。
3. 尝试新的模型
作为Baseline部分仅使用经典的LightGBM作为训练模型,我们还能尝试XGBoost、CatBoost和NN(神经网络),这里推荐两篇Datawhale成员吴忠强的文章做参考。
上分利器
XGBoost模型
LightGBM模型
4. 进行模型融合
模型融合是一种能在各种的机器学习任务上提高准确率的强有力技术,可谓是机器学习比赛大杀器,现在介绍基础上分和进阶上分两种方式。
基础上分
简单平均和加权平均是常用的两种比赛中模型融合的方式。其优点是快速、简单。
平均:(简单实用) 简单平均法 加权平均法 投票: 简单投票法 加权投票法 综合: 排序融合 log融合
进阶上分
stacking在众多比赛中大杀四方,但是跑过代码的小伙伴想必能感受到速度之慢,同时stacking多层提升幅度并不能抵消其带来的时间和内存消耗,实际环境中应用还是有一定的难度。
此外,在有答辩环节的比赛中,主办方也会一定程度上考虑模型的复杂程度,所以说并不是模型融合的层数越多越好的。
stacking:
构建多层模型,并利用预测结果再拟合预测。 blending:
选取部分数据预测训练得到预测结果作为新特征,带入剩下的数据中预测。 boosting/bagging
当然在比赛中将加权平均、stacking、blending等混用也是一种策略,可能会收获意想不到的效果哦!