
【数据竞赛】从0梳理1场数据挖掘赛事!
摘要:数据竞赛对于大家理论实践和增加履历帮助比较大,但许多读者反馈不知道如何入门,本文以河北高校数据挖掘邀请赛为背景,完整梳理了从环境准备、数据读取、数据分析、特征工程和数据建模的整个过程。
赛事分析
本次赛题为数据挖掘类型,通过机器学习算法进行建模预测。 是一个典型的回归问题。 主要应用xgb、lgb、catboost,以及pandas、numpy、matplotlib、seabon、sklearn、keras等数据挖掘常用库或者框架来进行数据挖掘任务。 通过EDA来挖掘数据的信息。 赛事地址(复制打开或阅读原文):https://tianchi.aliyun.com/s/f4ea3bec4429458ea03ef461cda87c3f
数据概况
了解列的性质会有助于我们对于数据的理解和后续分析。Tip:匿名特征,就是未告知数据列所属的性质的特征列。数据下载地址:https://tianchi.aliyun.com/competition/entrance/531858/information

代码实践
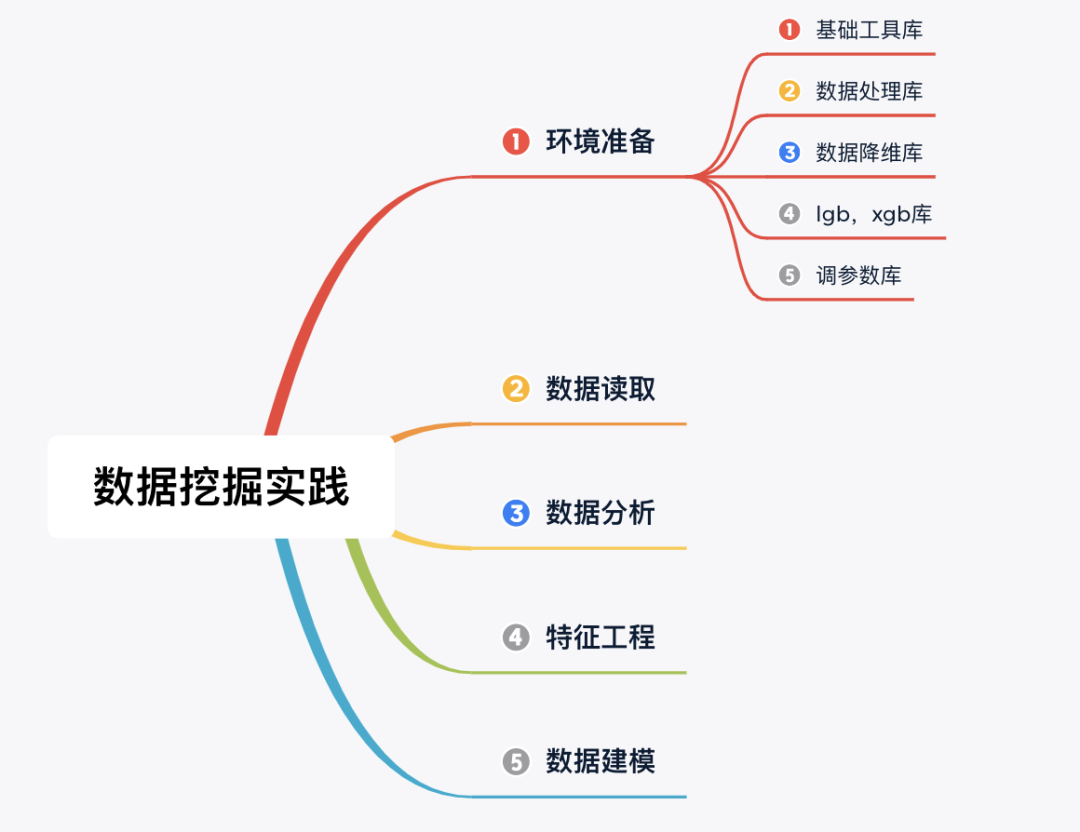
Step 1:环境准备(导入相关库)
## 基础工具
import numpy as np
import pandas as pd
import warnings
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.special import jn
from IPython.display import display, clear_output
import time
warnings.filterwarnings('ignore')
%matplotlib inline
## 数据处理
from sklearn import preprocessing
## 数据降维处理的
from sklearn.decomposition import PCA,FastICA,FactorAnalysis,SparsePCA
## 模型预测的
import lightgbm as lgb
import xgboost as xgb
## 参数搜索和评价的
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold,train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error
Step 2:数据读取
## 通过Pandas对于数据进行读取 (pandas是一个很友好的数据读取函数库)
#Train_data = pd.read_csv('datalab/231784/used_car_train_20200313.csv', sep=' ')
#TestA_data = pd.read_csv('datalab/231784/used_car_testA_20200313.csv', sep=' ')
path = './data/'
## 1) 载入训练集和测试集;
Train_data = pd.read_csv(path+'train.csv', sep=' ')
TestA_data = pd.read_csv(path+'testA.csv', sep=' ')
## 输出数据的大小信息
print('Train data shape:',Train_data.shape)
print('TestA data shape:',TestA_data.shape)
Train data shape: (150000, 31)
TestA data shape: (50000, 30)可以发现训练集有 15w 样本,而测试集有 5w 样本,特征维度并非很高,总体只有30维。
1) 数据简要浏览
## 通过.head() 简要浏览读取数据的形式
Train_data.head()

2) 数据信息查看
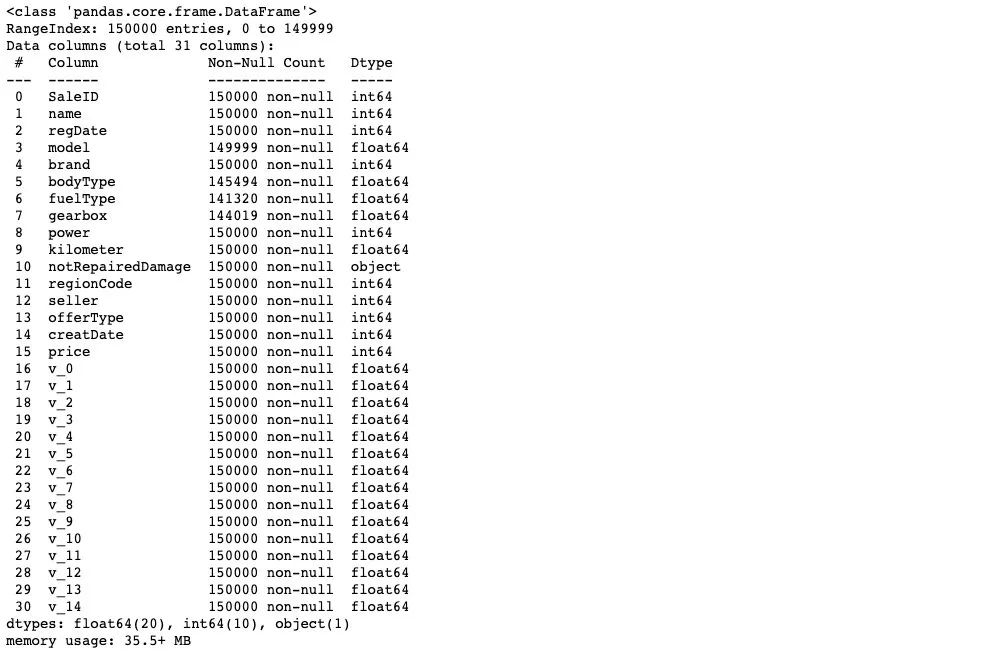
## 通过 .info() 简要可以看到对应一些数据列名,以及NAN缺失信息
Train_data.info()
# nan可视化
missing = Train_data.isnull().sum()
missing = missing[missing > 0]
missing.sort_values(inplace=True)
missing.plot.bar()
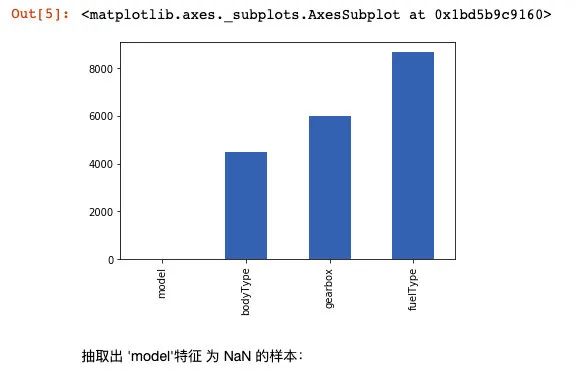
抽取出 'model'特征 为 NaN 的样本:
Train_data[np.isnan(Train_data['model'])]

TestA_data.info()

通过对于数据的基础 Infomation的查看,我们知道 'model','bodyType','fuelType','gearbox'特征 中存在缺失。
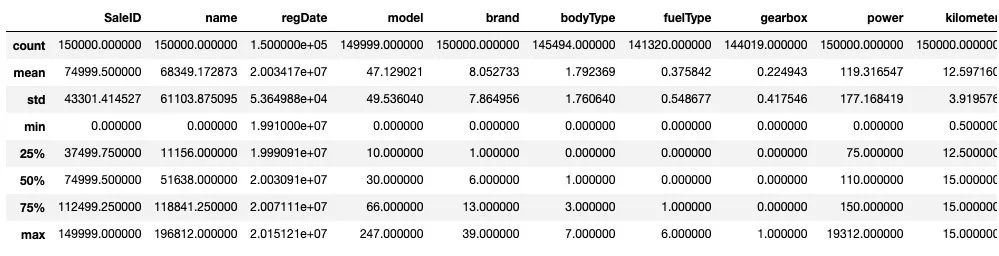
3) 数据统计信息浏览
#显示所有列
pd.set_option('display.max_columns', None)
## 通过 .describe() 可以查看数值特征列的一些统计信息
Train_data.describe()
TestA_data.describe()
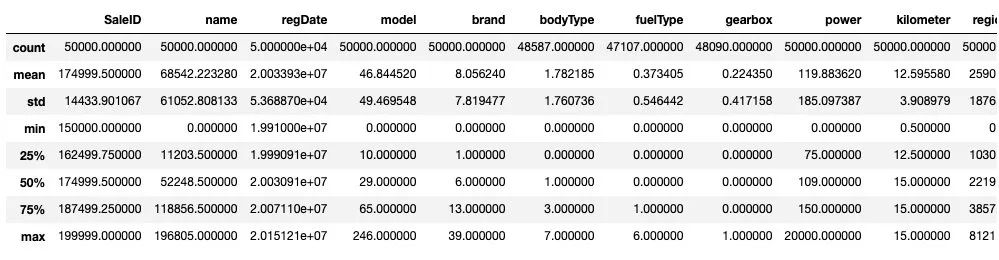
通过数据的统计信息,可以对于数据中的特征的变化情况有一个整体的了解。
Step 3: 数据分析(EDA)
1) 提取数值类型特征列名
numerical_cols = Train_data.select_dtypes(exclude = 'object').columns
print(numerical_cols)

categorical_cols = Train_data.select_dtypes(include = 'object').columns
print(categorical_cols)
# out: Index(['notRepairedDamage'], dtype='object')
首先我们对于非数字特征列进行数值化处理
set(Train_data['notRepairedDamage'])
# Out:{'-', '0.0', '1.0'}
Train_data['notRepairedDamage'] = Train_data['notRepairedDamage'].map({'-':-1,'0.0':0,'1.0':1})
TestA_data['notRepairedDamage'] = TestA_data['notRepairedDamage'].map({'-':-1,'0.0':0,'1.0':1})
由于数据特征可以分为 三种不同类型的特征,分别为时间特征,类别特征 和 数值类型特征, 我们对于不同特征进行分类别处理。
date_features = ['regDate', 'creatDate']
numeric_features = ['power', 'kilometer'] + ['v_{}'.format(i) for i in range(15)]
categorical_features = ['name', 'model', 'brand', 'bodyType', 'fuelType', 'gearbox', 'notRepairedDamage', 'regionCode',]
首先对于时间特征进行处理:
from tqdm import tqdm
def date_proc(x):
m = int(x[4:6])
if m == 0:
m = 1
return x[:4] + '-' + str(m) + '-' + x[6:]
def num_to_date(df,date_cols):
for f in tqdm(date_cols):
df[f] = pd.to_datetime(df[f].astype('str').apply(date_proc))
df[f + '_year'] = df[f].dt.year
df[f + '_month'] = df[f].dt.month
df[f + '_day'] = df[f].dt.day
df[f + '_dayofweek'] = df[f].dt.dayofweek
return df
Train_data = num_to_date(Train_data,date_features)
TestA_data = num_to_date(TestA_data,date_features)

plt.figure()
plt.figure(figsize=(16, 6))
i = 1
for f in date_features:
for col in ['year', 'month', 'day', 'dayofweek']:
plt.subplot(2, 4, i)
i += 1
v = Train_data[f + '_' + col].value_counts()
fig = sns.barplot(x=v.index, y=v.values)
for item in fig.get_xticklabels():
item.set_rotation(90)
plt.title(f + '_' + col)
plt.tight_layout()
plt.show()
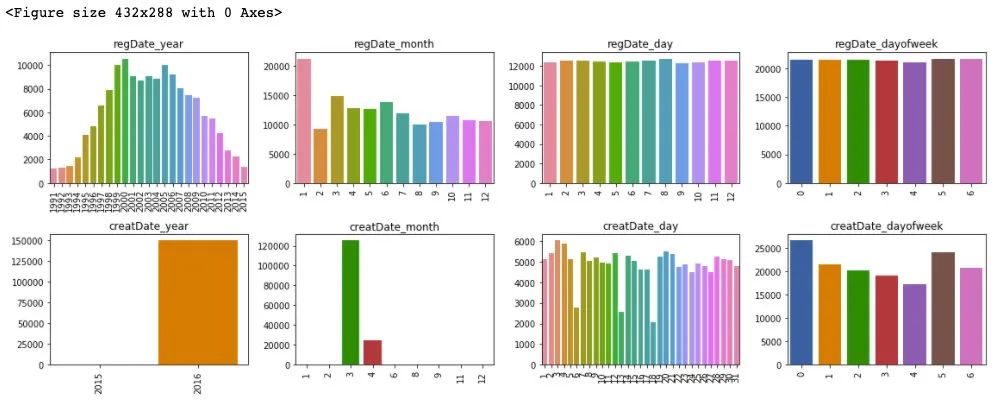
plt.figure()
plt.figure(figsize=(16, 6))
i = 1
for f in date_features:
for col in ['year', 'month', 'day', 'dayofweek']:
plt.subplot(2, 4, i)
i += 1
v = TestA_data[f + '_' + col].value_counts()
fig = sns.barplot(x=v.index, y=v.values)
for item in fig.get_xticklabels():
item.set_rotation(90)
plt.title(f + '_' + col)
plt.tight_layout()
plt.show()
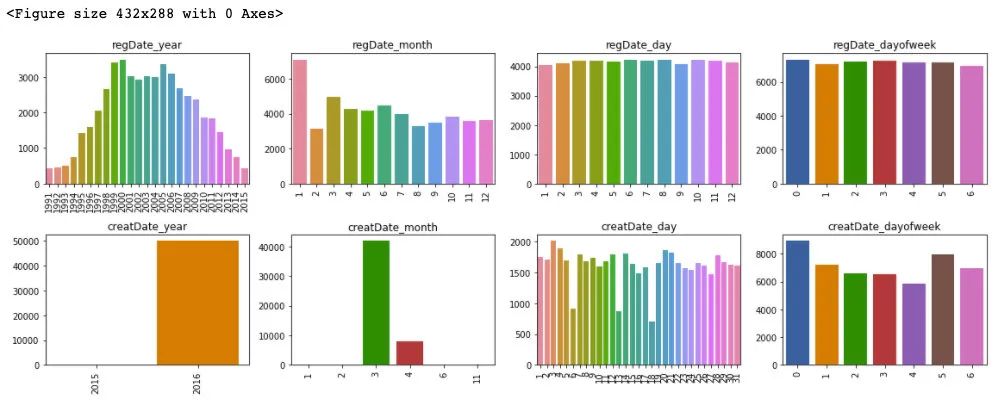
通过对于训练集和测试集的时间特征可视化,我们可以发现其分布是近似的,所以时间方面不会造成切换数据所导致的分布不一致的问题,进一步的,这里对于数据特征和标签绘制箱型图来判断标签关于特征的分布差异性。
plt.figure()
plt.figure(figsize=(16, 6))
i = 1
for f in date_features:
for col in ['year', 'month', 'day', 'dayofweek']:
plt.subplot(2, 4, i)
i += 1
fig = sns.boxplot(x=Train_data[f + '_' + col], y=Train_data['price'])
for item in fig.get_xticklabels():
item.set_rotation(90)
plt.title(f + '_' + col)
plt.tight_layout()
plt.show()
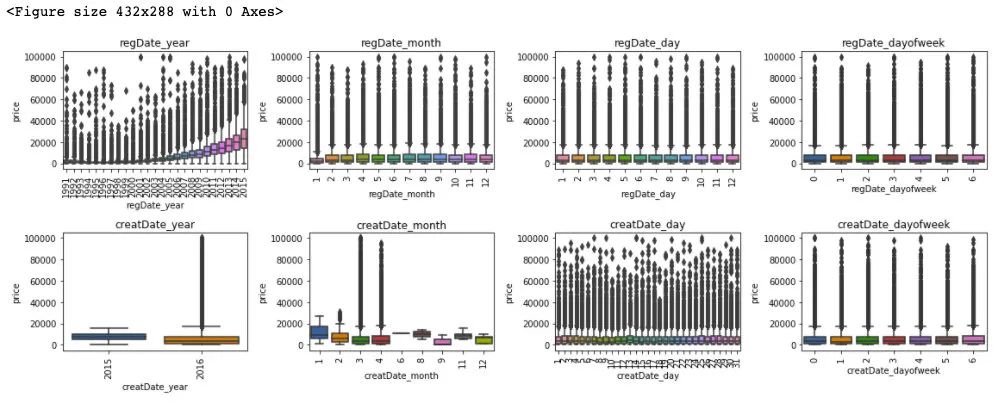
## 更新数据特征
date_features = ['regDate_year', 'regDate_month', 'regDate_day', 'regDate_dayofweek', 'creatDate_month', 'creatDate_day', 'creatDate_dayofweek']
可以发现,时间特征和价格的相关性来说,随着 regDate_year 的时间越久远,其价格越低,然后 creatDate_month 特征和价格变化也有较大波动,但这通过前面的样本统计量来看,是由于相对于3,4月份,剩余月份的样本量较少的缘故。所以从时间特征中我们可以提前 regDate_year 作为模型预测的一个重要特征。
类别特征处理:
对于类别类型的特征,首先这里第一步进行类别数量统计
from scipy.stats import mode
def sta_cate(df,cols):
sta_df = pd.DataFrame(columns = ['column','nunique','miss_rate','most_value','most_value_counts','max_value_counts_rate'])
for col in cols:
count = df[col].count()
nunique = df[col].nunique()
miss_rate = (df.shape[0] - count) / df.shape[0]
most_value = df[col].value_counts().index[0]
most_value_counts = df[col].value_counts().values[0]
max_value_counts_rate = most_value_counts / df.shape[0]
sta_df = sta_df.append({'column':col,'nunique':nunique,'miss_rate':miss_rate,'most_value':most_value,
'most_value_counts':most_value_counts,'max_value_counts_rate':max_value_counts_rate},ignore_index=True)
return sta_df
sta_cate(Train_data,categorical_features)
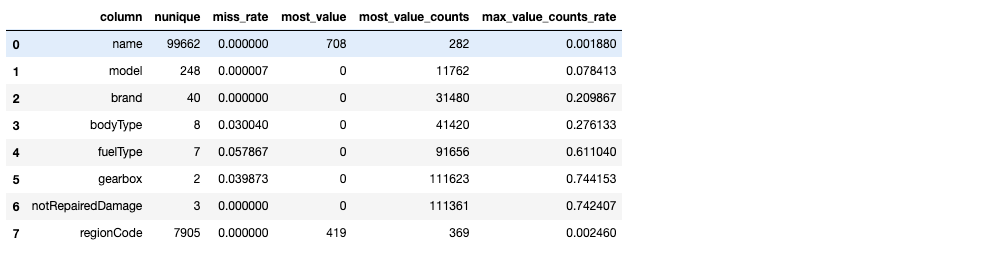
sta_cate(TestA_data,categorical_features)
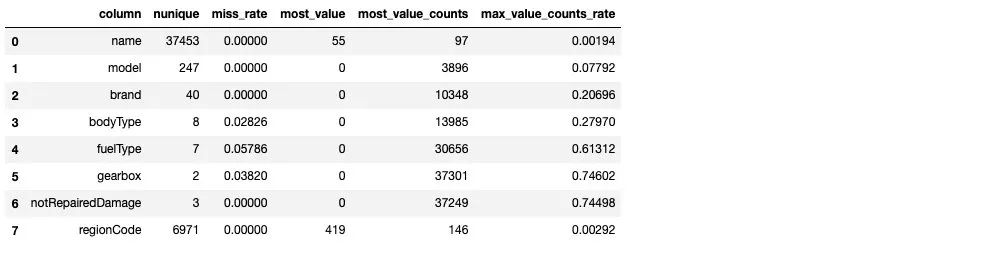
从上述样本的统计情况来看,其中 name 特征和 regionCode 特征数量众多,不适宜做类别编码。model 特征需要做进一步的考虑,这里我们先对于 剩余的类别特征做统计可视化:
plt.figure()
plt.figure(figsize=(16, 6))
i = 1
for col in ['bodyType', 'fuelType', 'gearbox', 'notRepairedDamage']:
plt.subplot(1, 4, i)
i += 1
fig = sns.boxplot(x=Train_data[col], y=Train_data['price'])
for item in fig.get_xticklabels():
item.set_rotation(90)
plt.tight_layout()
plt.show()
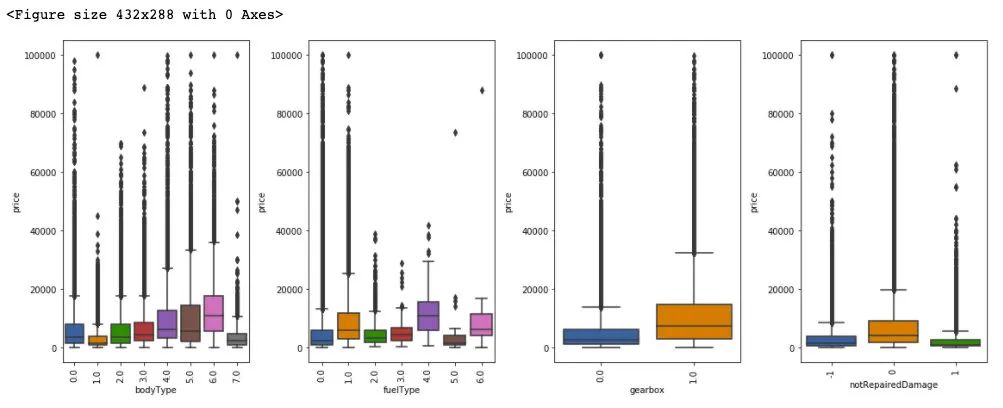
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
def cate_encoder(df,df_test,cols):
le = LabelEncoder()
ohe = OneHotEncoder(sparse=False,categories ='auto')
for col in cols:
print(col+':')
print(set(df[col]))
print(set(df_test[col]))
le = le.fit(df[col])
integer_encoded = le.transform(df[col])
integer_encoded_test = le.transform(df_test[col])
# binary encode
integer_encoded = integer_encoded.reshape(len(integer_encoded), 1)
integer_encoded_test = integer_encoded_test.reshape(len(integer_encoded_test), 1)
ohe = ohe.fit(integer_encoded)
onehot_encoded = ohe.transform(integer_encoded)
onehot_encoded_df = pd.DataFrame(onehot_encoded)
onehot_encoded_df.columns = list(map(lambda x:str(x)+'_'+col,onehot_encoded_df.columns.values))
onehot_encoded_test = ohe.transform(integer_encoded_test)
onehot_encoded_test_df = pd.DataFrame(onehot_encoded_test)
onehot_encoded_test_df.columns = list(map(lambda x:str(x)+'_'+col,onehot_encoded_test_df.columns.values))
df = pd.concat([df,onehot_encoded_df], axis=1)
df_test = pd.concat([df_test,onehot_encoded_test_df], axis=1)
return df,df_test
cate_cols = ['bodyType', 'fuelType', 'gearbox', 'notRepairedDamage']
Train_data[cate_cols] = Train_data[cate_cols].fillna(-1)
TestA_data[cate_cols] = TestA_data[cate_cols].fillna(-1)
Train_data,TestA_data = cate_encoder(Train_data,TestA_data,cate_cols)
## 对类别特征进行 OneEncoder
# data = pd.get_dummies(data, columns=cate_cols)

Train_data
plt.figure(figsize=(15, 15))
i = 1
for col in numeric_features:
plt.subplot(5, 4, i)
i += 1
sns.distplot(Train_data[col], label='train', color='r', hist=False)
sns.distplot(TestA_data[col], label='test', color='b', hist=False)
plt.tight_layout()
plt.show()
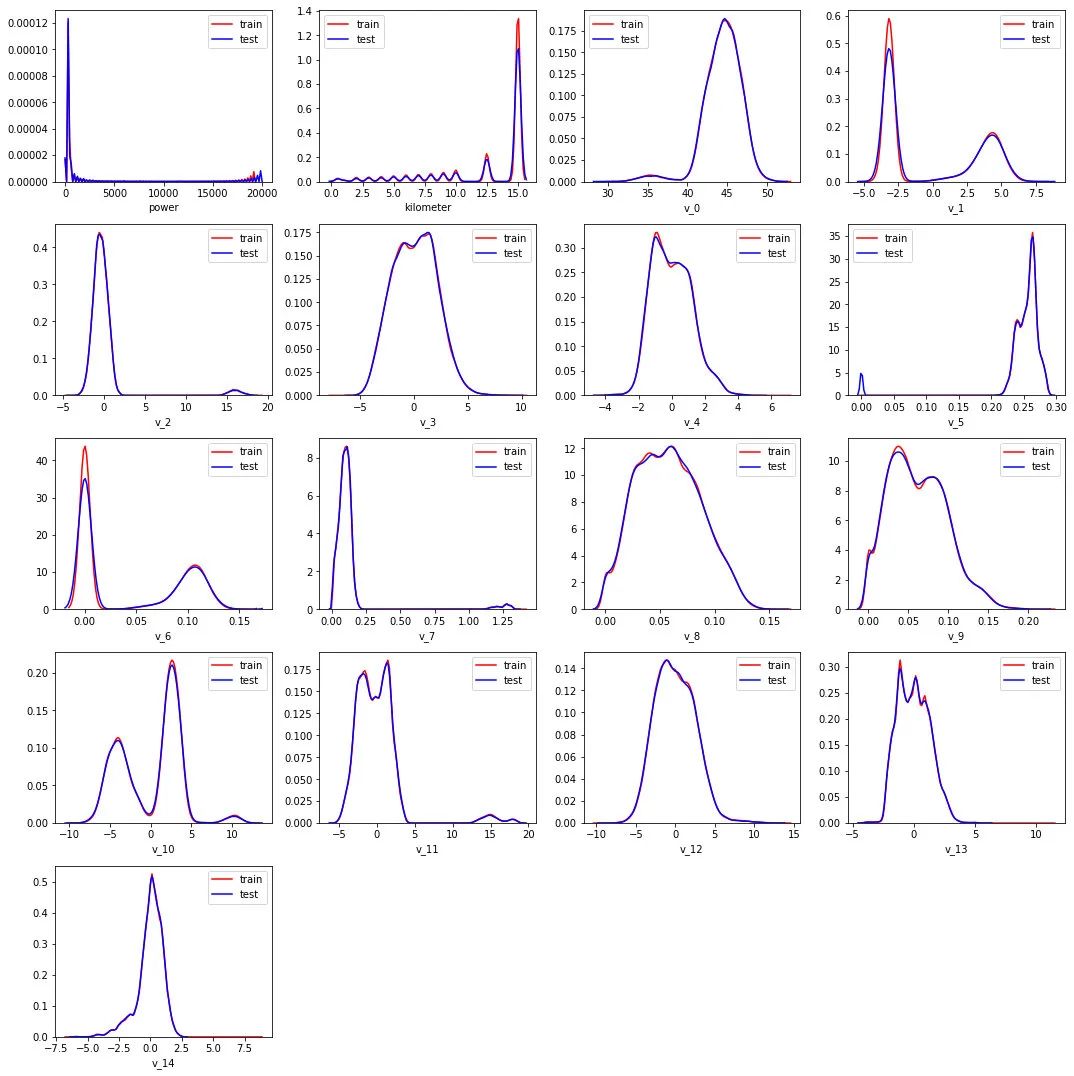
可以发现数值类型的特征分布在训练集和测试集上是近似的。
corr = Train_data[numeric_features+['price']].corr()
plt.figure(figsize=(20, 20))
sns.heatmap(abs(np.around(corr,2)), linewidths=0.1, annot=True,cmap=sns.cm.rocket_r)
plt.show()
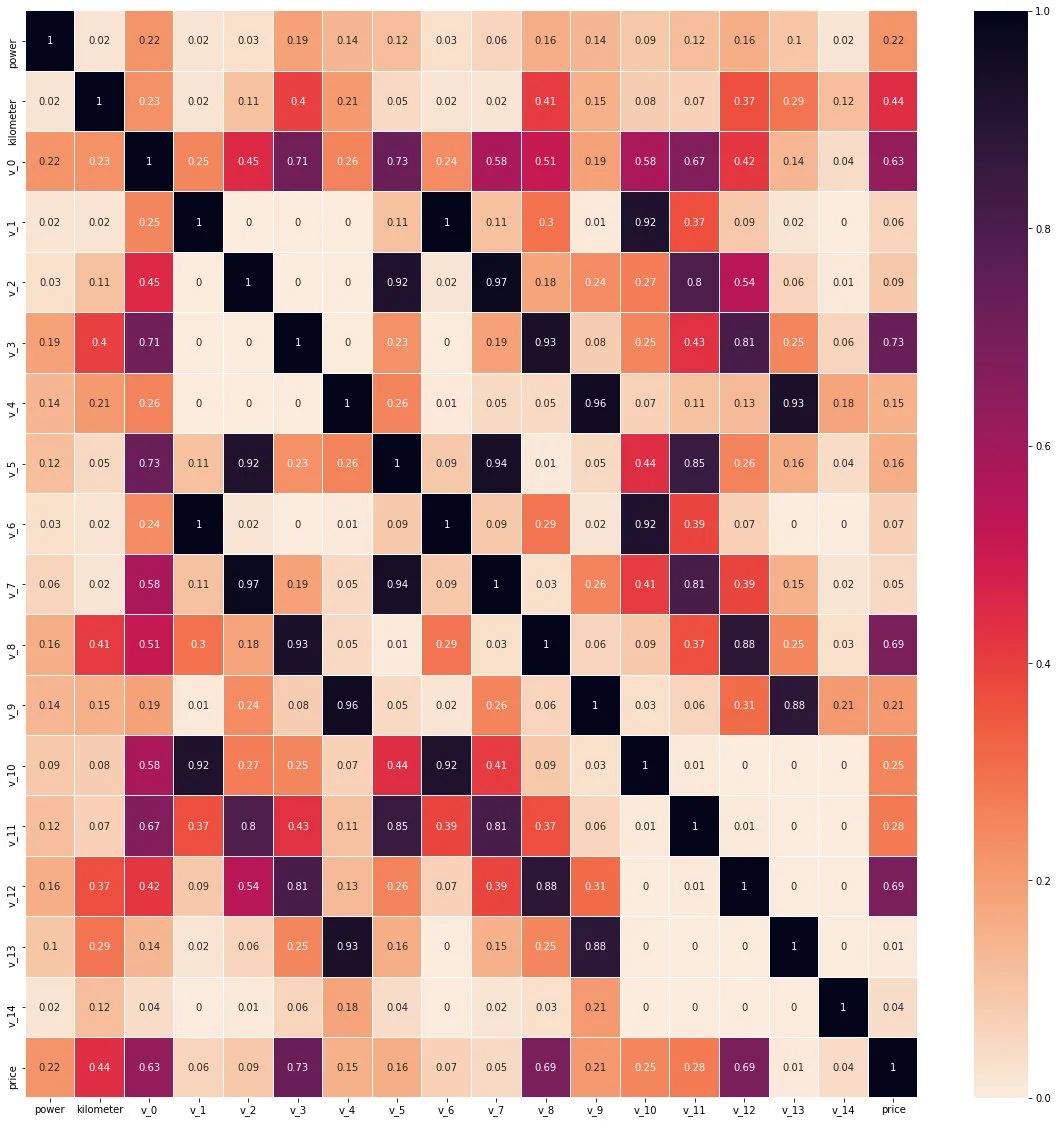
从数值特征维度来看 v_0,v_3,v_8,v_12 和标签的线性相关性(皮尔逊相关系数)是较为相关的。
Step 4: 特征工程
1) 特征工程
# 训练集和测试集放在一起,方便构造特征
Train_data['train']=1
TestA_data['train']=0
data = pd.concat([Train_data, TestA_data], ignore_index=True, sort=False)
一些特殊的特征生成:
data['used_time'] = (pd.to_datetime(data['creatDate'], format='%Y%m%d', errors='coerce') -
pd.to_datetime(data['regDate'], format='%Y%m%d', errors='coerce')).dt.days
# 看一下空数据,有 15k 个样本的时间是有问题的,我们可以选择删除,也可以选择放着(不管或者作为一个单独类别)。
# XGBoost 之类的决策树,其本身就能处理缺失值,所以可以不用管;
data['used_time'].isnull().sum()
# Out:0
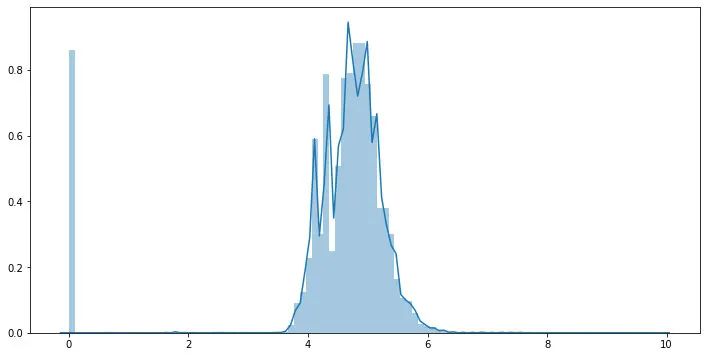
## 由于power 特征的分布特性,这里对于其进行log变化
data['power'] = np.log1p(data['power'])
plt.figure(figsize=(12,6))
sns.distplot(data['power'].values ,bins=100)
plt.show()
# 计算某品牌的销售统计量,这种特征不能细粒度的统计,防止发生信息过多的泄露
train_gb = Train_data.groupby("brand")
all_info = {}
for kind, kind_data in train_gb:
info = {}
kind_data = kind_data[kind_data['price'] > 0]
info['brand_amount'] = len(kind_data)
info['brand_price_max'] = kind_data.price.max()
info['brand_price_median'] = kind_data.price.median()
info['brand_price_min'] = kind_data.price.min()
info['brand_price_sum'] = kind_data.price.sum()
info['brand_price_std'] = kind_data.price.std()
info['brand_price_average'] = round(kind_data.price.sum() / (len(kind_data) + 1), 2)
all_info[kind] = info
brand_fe = pd.DataFrame(all_info).T.reset_index().rename(columns={"index": "brand"})
data = data.merge(brand_fe, how='left', on='brand')
统计特征生成:
统计特征这部分就有多种形式了,有多项式特征,类别和类别的交叉特征,类别和数值之间的交叉特征等
## 这部分就参考天才的代码了
from scipy.stats import entropy
feat_cols = []
### count编码
for f in tqdm(['regDate_year','model', 'brand', 'regionCode']):
data[f + '_count'] = data[f].map(data[f].value_counts())
feat_cols.append(f + '_count')
### 用数值特征对类别特征做统计刻画,随便挑了几个跟price相关性最高的匿名特征
for f1 in tqdm(['model', 'brand', 'regionCode']):
group = data.groupby(f1, as_index=False)
for f2 in tqdm(['v_0', 'v_3', 'v_8', 'v_12']):
feat = group[f2].agg({
'{}_{}_max'.format(f1, f2): 'max', '{}_{}_min'.format(f1, f2): 'min',
'{}_{}_median'.format(f1, f2): 'median', '{}_{}_mean'.format(f1, f2): 'mean',
'{}_{}_std'.format(f1, f2): 'std', '{}_{}_mad'.format(f1, f2): 'mad'
})
data = data.merge(feat, on=f1, how='left')
feat_list = list(feat)
feat_list.remove(f1)
feat_cols.extend(feat_list)
### 类别特征的二阶交叉
for f_pair in tqdm([['model', 'brand'], ['model', 'regionCode'], ['brand', 'regionCode']]):
### 共现次数
data['_'.join(f_pair) + '_count'] = data.groupby(f_pair)['SaleID'].transform('count')
### nunique、熵
data = data.merge(data.groupby(f_pair[0], as_index=False)[f_pair[1]].agg({
'{}_{}_nunique'.format(f_pair[0], f_pair[1]): 'nunique',
'{}_{}_ent'.format(f_pair[0], f_pair[1]): lambda x: entropy(x.value_counts() / x.shape[0])
}), on=f_pair[0], how='left')
data = data.merge(data.groupby(f_pair[1], as_index=False)[f_pair[0]].agg({
'{}_{}_nunique'.format(f_pair[1], f_pair[0]): 'nunique',
'{}_{}_ent'.format(f_pair[1], f_pair[0]): lambda x: entropy(x.value_counts() / x.shape[0])
}), on=f_pair[1], how='left')
### 比例偏好
data['{}_in_{}_prop'.format(f_pair[0], f_pair[1])] = data['_'.join(f_pair) + '_count'] / data[f_pair[1] + '_count']
data['{}_in_{}_prop'.format(f_pair[1], f_pair[0])] = data['_'.join(f_pair) + '_count'] / data[f_pair[0] + '_count']
feat_cols.extend([
'_'.join(f_pair) + '_count',
'{}_{}_nunique'.format(f_pair[0], f_pair[1]), '{}_{}_ent'.format(f_pair[0], f_pair[1]),
'{}_{}_nunique'.format(f_pair[1], f_pair[0]), '{}_{}_ent'.format(f_pair[1], f_pair[0]),
'{}_in_{}_prop'.format(f_pair[0], f_pair[1]), '{}_in_{}_prop'.format(f_pair[1], f_pair[0])
])
data
train = data[data['train']==1]
test = data[data['train']==0]
categorical_cols = train.select_dtypes(include = 'object').columns
categorical_cols
# Out:Index([], dtype='object')
2) 构建训练和测试样本
## 选择特征列
feature_cols = [col for col in data.columns if col not in ['SaleID','name','regDate','creatDate','price','model','brand',
'regionCode','seller','bodyType','fuelType','offerType','train']]
feature_cols = [col for col in feature_cols if col not in date_features[1:]]
## 提前特征列,标签列构造训练样本和测试样本
X_data = train[feature_cols]
Y_data = train['price']
X_test = test[feature_cols]
print('X train shape:',X_data.shape)
print('X test shape:',X_test.shape)
### Out ###
X train shape: (150000, 149)
X test shape: (50000, 149)
3) 统计标签的基本分布信息
Y_data.describe()

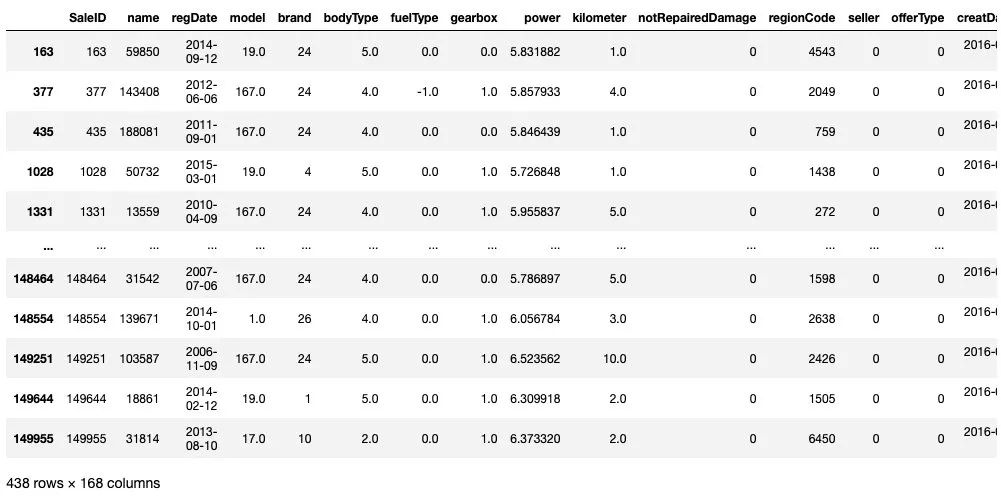
train[train['price']<1e2]
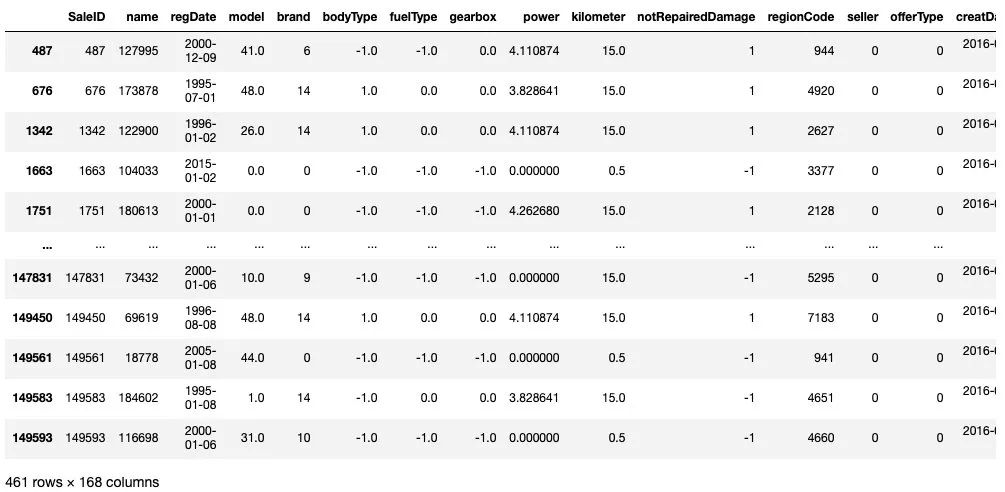
train[train['price']>5e4]
## 绘制标签的统计图,查看标签分布
plt.figure(figsize=(12,6))
sns.distplot(Y_data,bins=100)
plt.show()
plt.figure(figsize=(12,6))
Y_data.plot.box()
plt.show()
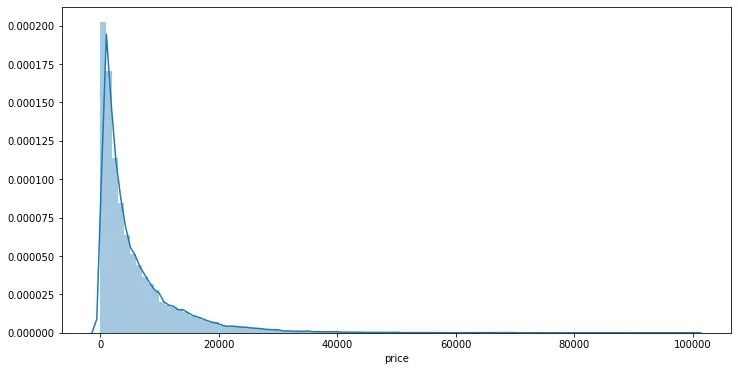
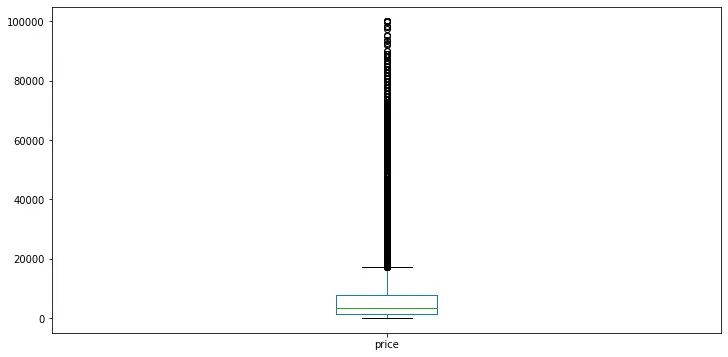
可以发现标签是非正态分布的,这里对于标签进行log变换
Y_data_log = np.log1p(Y_data)
## 绘制标签的统计图,查看标签log分布
plt.figure(figsize=(12,6))
sns.distplot(Y_data_log,bins=100)
plt.show()
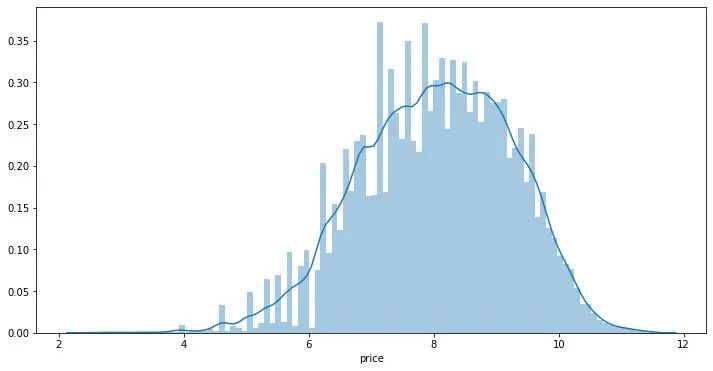
在实验中可以尝试利用log后的标签训练再exp回去 和 直接用标签训练的效果进行对比。
4) 缺省值用-1填补
X_data = X_data.fillna(-1)
X_test = X_test.fillna(-1)
Step 5: 模型构建
这里分别举例;1.利用交叉验证预测;2.模型混合预测。
1) 利用xgb进行五折交叉验证查看模型的参数效果并预测
from sklearn.model_selection import KFold
def cv_predict(model,X_data,Y_data,X_test,sub):
oof_trn = np.zeros(X_data.shape[0])
oof_val = np.zeros(X_data.shape[0])
## 5折交叉验证方式
kf = KFold(n_splits=5,shuffle=True,random_state=0)
for idx, (trn_idx,val_idx) in enumerate(kf.split(X_data,Y_data)):
print('--------------------- {} fold ---------------------'.format(idx))
trn_x, trn_y = X_data.iloc[trn_idx].values, Y_data.iloc[trn_idx]
val_x, val_y = X_data.iloc[val_idx].values, Y_data.iloc[val_idx]
xgr.fit(trn_x,trn_y,eval_set=[(val_x, val_y)],eval_metric='mae',verbose=30,early_stopping_rounds=20,)
oof_trn[trn_idx] = xgr.predict(trn_x)
oof_val[val_idx] = xgr.predict(val_x)
sub['price'] += xgr.predict(X_test.values) / kf.n_splits
pred_trn_xgb=xgr.predict(trn_x)
pred_val_xgb=xgr.predict(val_x)
print('trn mae:', mean_absolute_error(trn_y, oof_trn[trn_idx]))
print('val mae:', mean_absolute_error(val_y, oof_val[val_idx]))
return model,oof_trn,oof_val,sub
## log标签预测
sub = test[['SaleID']].copy()
sub['price'] = 0
## xgb-Model
xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #,objective ='reg:squarederror'
model,oof_trn,oof_val,sub = cv_predict(xgr,X_data,Y_data_log,X_test,sub)
print('Train mae:',mean_absolute_error(Y_data_log,oof_trn))
print('Val mae:', mean_absolute_error(Y_data_log,oof_val))
print('Train mae trans:',mean_absolute_error(np.expm1(Y_data_log),np.expm1(oof_trn)))
print('Val mae trans', mean_absolute_error(np.expm1(Y_data_log),np.expm1(oof_val)))

## 原始标签预测
sub2 = test[['SaleID']].copy()
sub2['price'] = 0
oof_trn = np.zeros(train.shape[0])
oof_val = np.zeros(train.shape[0])
## xgb-Model
xgr = xgb.XGBRegressor(n_estimators=120, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #,objective ='reg:squarederror'
model2,oof_trn,oof_val,sub2 = cv_predict(xgr,X_data,Y_data,X_test,sub2)
print('Train mae:',mean_squared_error(Y_data,oof_trn))
print('Val mae:', mean_squared_error(Y_data,oof_val))
2) 定义xgb和lgb模型函数,并对于lgb参数进行网格化寻优
def build_model_xgb(x_train,y_train):
model = xgb.XGBRegressor(n_estimators=150, learning_rate=0.1, gamma=0, subsample=0.8,\
colsample_bytree=0.9, max_depth=7) #, objective ='reg:squarederror'
model.fit(x_train, y_train)
return model
def build_model_lgb(x_train,y_train):
estimator = lgb.LGBMRegressor(num_leaves=127,n_estimators = 150)
param_grid = {
'learning_rate': [0.01, 0.05, 0.1, 0.2],
}
gbm = GridSearchCV(estimator, param_grid)
gbm.fit(x_train, y_train)
return gbm
3)切分数据集(Train,Val)进行模型训练,评价和预测
## Split data with val
x_train,x_val,y_train,y_val = train_test_split(X_data,Y_data,test_size=0.3)
## 定义了一个统计函数,方便后续信息统计
def Sta_inf(data):
print('_min',np.min(data))
print('_max:',np.max(data))
print('_mean',np.mean(data))
print('_ptp',np.ptp(data))
print('_std',np.std(data))
print('_var',np.var(data))
print('Sta of label:')
Sta_inf(Y_data)
print('Train lgb...')
model_lgb = build_model_lgb(x_train,y_train)
val_lgb = model_lgb.predict(x_val)
MAE_lgb = mean_absolute_error(y_val,val_lgb)
print('MAE of val with lgb:',MAE_lgb)
print('Predict lgb...')
model_lgb_pre = build_model_lgb(X_data,Y_data)
subA_lgb = model_lgb_pre.predict(X_test)
print('Sta of Predict lgb:')
Sta_inf(subA_lgb)
print('Train xgb...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
MAE_xgb = mean_absolute_error(y_val,val_xgb)
print('MAE of val with xgb:',MAE_xgb)
print('Predict xgb...')
model_xgb_pre = build_model_xgb(X_data,Y_data)
subA_xgb = model_xgb_pre.predict(X_test)
print('Sta of Predict xgb:')
Sta_inf(subA_xgb)
4)进行两模型的结果加权融合
## 这里我们采取了简单的加权融合的方式
val_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*val_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*val_xgb
val_Weighted[val_Weighted<10]=10 # 由于我们发现预测的最小值有负数,而真实情况下,price为负是不存在的,由此我们进行对应的后修正
print('MAE of val with Weighted ensemble:',mean_absolute_error(y_val,val_Weighted))
sub_Weighted = (1-MAE_lgb/(MAE_xgb+MAE_lgb))*subA_lgb+(1-MAE_xgb/(MAE_xgb+MAE_lgb))*subA_xgb
sub_Weighted[sub_Weighted<10]=10## 查看预测值的统计,判断和训练集是否接近
print('Sta of Predict lgb:')
Sta_inf(sub_Weighted)
5)输出结果
sub3 = test[['SaleID']].copy()
sub3['price'] = sub_Weighted
sub3.to_csv('./sub_Weighted.csv',index=False)
sub3.head()
希望能帮助你完整实践一场数据挖掘赛事。
往期精彩回顾
本站知识星球“黄博的机器学习圈子”(92416895)
本站qq群704220115。
加入微信群请扫码: