
以隐私的名义,一场数据的战争打响了

当数据已经成为新时代的石油,当数据所有权尚未清晰,科技圈的暗战已然开打。
采写 | 汤一涛
说这话的鸭子来自 DuckDuckGo,一家主打隐私保护的搜索引擎公司。
 DuckDuckGo 在旧金山「新硅谷」SOMA 地区的广告牌|图片来源:WIRED
DuckDuckGo 在旧金山「新硅谷」SOMA 地区的广告牌|图片来源:WIRED
在美国,DuckDuckGo 有 2245 块广告牌,在欧洲是 2261 块。这对于一家科技公司来说并不寻常。
通常,科技公司更倾向于在线上投放广告。根据用户数据生成的定向广告可以让公司更高效地找到他们的目标用户。DuckDuckGo 选择了广告牌这种老派的方式——这是为了以行动树立这家企业的价值观:不追踪用户。
去年,DuckDuckGo 的应用下载量超过了 5000 万次,比之前所有年份的总和还多,年收入也相应突破了 1 亿美元(约合 6.5 亿元人民币)。要知道,这家成立于 2008 年的公司,在上一轮融资过后,估值也就 7480 万美元(约合 4.86 亿元人民币)。看起来,它主打隐私的价值观奏效了。
最近,DuckDuckGo 凭借 2.42% 的市占率,超越必应、雅虎成为了美国第二的移动搜素引擎。而第一名的谷歌,是 94.36%,DuckDuckGo 的 39 倍。
这是一个大卫挑战哥利亚的故事,但在这个故事中,「大卫」挥舞的不是石子,而是「隐私」这杆大旗。
种种数据表明:在巨头格局确立,新秀创业公司本没有多少增长空间的当下,以隐私为名的新一代数据之争已经拉开序幕。
苹果掀起的数据战争
2020 年 6 月,苹果的隐私工程经理凯蒂·史金纳(Katie Skinner)在 WWDC(世界开发者大会)上用 20 秒介绍了 iOS 14 的一个「小小更新」:App 在搜集用户数据之前,必须征求用户同意。一旦用户不同意,就会关闭 IDFA 码(Identifier For Advertisers),苹果的广告主标识符。
这个搜集用户数据的 IDFA 开关,在去年 6 月之前还是默认开启的。但在 iOS 14 上,这成为了一个显性的可选项。当用户第一次打开 App 时,iOS 会弹窗询问:「是否同意 App 对你进行跨网站、App 的追踪?」显然,多数用户并不会同意,这就直接切断了定向广告的数据来源。
这是苹果应用追踪透明度(App Tracking Transparency,ATT)的一部分。2021 年 5 月,一项针对美国 300 名 iPhone 用户的调查指出,73% 的受访者对这项隐私政策都表示赞同。苹果的 CEO 蒂姆·库克(Tim Cook)也在 2021 年第三季度的财报电话会议上回应,在 ATT 推出之后,苹果受到了相当积极的回馈。
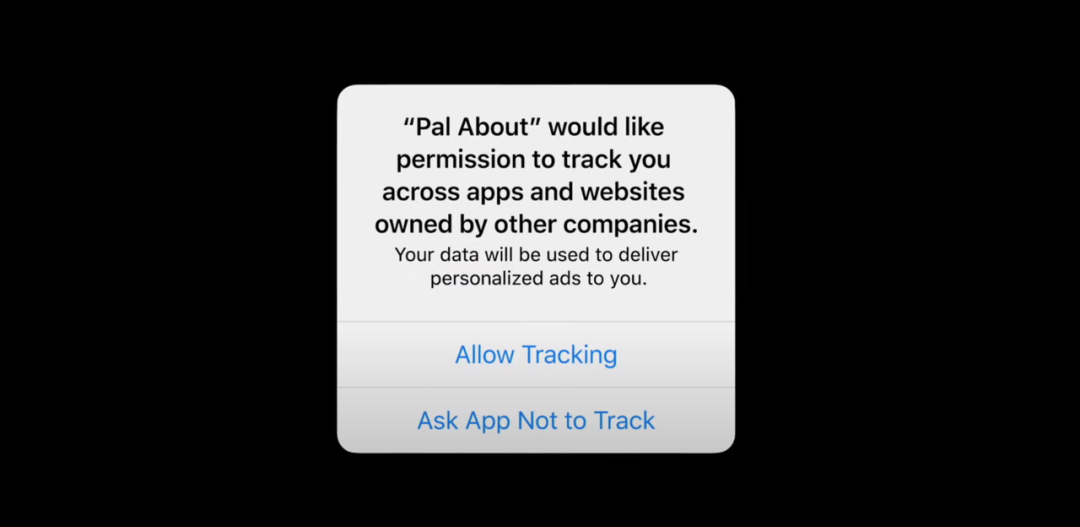 「你的 App 想要追踪你的数据给你发广告,你同意追踪吗?」|图片来源:Apple
「你的 App 想要追踪你的数据给你发广告,你同意追踪吗?」|图片来源:Apple
但对于所有以线上广告为商业模式的公司来说,这可能是一场性命攸关的大震荡。反应最激烈的是 Facebook。2020 年 12 月,它买了下了《纽约时报》的一整个版面,公开反对苹果。
在 Facebook 的口径中,苹果的做法严重限制了中小企业的生存。大企业有足够的财力进行大规模广告投放,但中小企业如果没有精准投放技术,就很难找到潜在的用户群,广告投放的效率会大大降低。根据 Facebook 说法,这会平均降低中小企业 60% 的收入。
 Facebook 认为苹果的做法扼杀了中小企业,而 Facebook 将立场鲜明地与中小企业站在一起。|图片来源:Twitter@DaveStangis
Facebook 认为苹果的做法扼杀了中小企业,而 Facebook 将立场鲜明地与中小企业站在一起。|图片来源:Twitter@DaveStangis
虽然 Facebook 的言论看起来是纯粹利他的,但和大众印象不同,表面上是一家科技公司的 Facebook 其实是一家广告公司。2020 年四季度财报显示,Facebook 的 280.7 亿美元(约合 1825.84 亿元人民币)的收入中,96.8% 都来自广告。Facebook 曾在 iOS 14 测试版上小规模测试过,结果广告收入出现了 50% 的下跌。
在财报公布后的电话会议上,Facebook 的 CEO 扎克伯格更是直白地说道:「苹果嘴上说他们在帮助用户,但实际上这件事显然是利益驱使。」
Facebook 和苹果的本质矛盾在于这两家公司商业模式的不同。广告是 Facebook 的核心业务,广告商是它的主要客户。但苹果是一家电子消费品公司,面向的是 C 端用户,包括 iPhone、iPad、Mac 和其他可穿戴式设备的硬件销售才是它的主要收入。
实际上,让业界如此在意的 IDFA 就是苹果隐私政策的产物。在 IDFA 问世之前,App 可以直接读取到手机的唯一识别码,无论是 MAC 地址、UDID 还是 UUID。IDFA 的不同之处在于用户可以重置或者关闭这个识别码。虽然 IDFA 的关闭入口隐藏得很深,但苹果给了用户一个选择:是否要让 App 给你推送定向广告。需要注意的是,关闭 IDFA 并不会减少广告数量,只是定向广告的精度会下降。
但扎克伯格的「攻击」不是没有来由,苹果并非隐私保护的「天使」。在打击竞争对手广告业务的同时,苹果也在扩大自身的广告版图。
苹果的广告业务主要有两种,App Store 的搜索广告和新闻、股市应用的展示广告。目前,苹果的搜索广告业务(Apple Search Ads)已经在中国上线。这项在 2016 年就推出的业务允许开发者以竞价的方式投放广告。
而根据 FT 中文网的报道,苹果正在计划为 App Store 增加第二个广告位。
 以抖音为例,在 App Store 搜索「抖音」后,排名第一的是「快手」的广告
以抖音为例,在 App Store 搜索「抖音」后,排名第一的是「快手」的广告
事实上,苹果一直在试图进入广告业务。早在 2010 年,苹果就推出了移动广告平台 iAd。在乔布斯看来,当时的移动广告「实在太烂了」。他不想把 iAd 做成低俗的广告平台,而是希望这个平台上可以呈现优雅的、不会让用户反感的广告。也因此,iAd 设立了 50 万美元的高门槛,这让很多中小公司望而却步。最终 iAd 于 2016 年 6 月关闭。
三年前,苹果也自己设计了一套广告追踪框架——SKAdNetwork。它和 IDFA 一样可以追踪广告投放的效果,但出于种种数据保护方面的限制,也很难称得上好用。但是在眼下「严苛」的苹果新政面前,SKAdNetwork 可能是广告主们最好的选择了。
虽然目前广告业务只占苹果营收中非常小的一部分,但是对于既当「裁判」又做「守门员」的苹果来说,它用一套新的隐私规则,完成了「清场」。
根据投资管理公司 Alliance Bernstein 的分析师托尼·萨克纳吉(Toni Sacconaghi)估计,苹果公司在 2021 财年的广告收入将从 2017 财年的 3 亿美元增加到 30 亿美元左右。到 2023 或 2024 财年,苹果广告的年销售额可能会增至 70 亿至 100 亿美元之间,这将推动苹果服务业务的增长高达 3 个百分点。
自 2011 年 iPhone4 问世以来已经过去了 10 年,苹果领先业界的硬件优势逐渐被各大安卓手机厂商追平,甚至超越。当用户需要一个「为什么非得是苹果而不是安卓」的理由时,隐私保护可能就是非常重要的一环。
在乔布斯选择封闭系统开始,就为 iOS 种下了隐私保护的基因。苹果的隐私政策并非横空出世,而是在逐步收紧。IDFA 的风波切中了一个我们当下这个时代必须回应的问题:技术在侵犯用户隐私吗?
个人数据,21 世纪的石油?
2006 年的时候,英国数学家克莱夫·汉比(Clive Humby)首次把「数据」比喻成了「新的石油」。此后,这种说法就在经济学家、学者和 CEO 的口中频频出现。
石油的珍贵在于它是不可再生的能源,但数据是可以无限产生和重复利用的,今天的互联网上每天都在产生海量的数据。
这个比喻成立的逻辑在于,整个 20 世纪,标准石油、荷兰皇家壳牌、英国石油公司,这些控制着石油的公司也控制着经济的命脉。放在今天,是谷歌、Facebook 这些科技巨头。
本世纪初,手握海量数据的科技巨头们发展出了一门新生意——线上定向广告。到 2019 年,全球网络广告的市场规模已经突破 3000 亿美元(约合 1.95 万亿元人民币)。
在广告业一直流传着这么一句话:「我知道在广告上的投资有一半是无用的,但问题是我不知道是哪一半。」说这话的是百货业之父约翰·沃纳梅克 (John Wanamaker),那是 100 多年前,传统广告的黄金时代。
情况在互联网时代发生了变化,科技的进步让广告成为了一件很高效的事情。某种程度上,沃纳梅克的迷思已经不再成立,各大科技公司可以很方便地追踪用户行为、记录广告投放所获得的下载或购买转化次数,而广告主以此决定向各流量平台支付多少广告费用。
你或许有过这样的经历,在网页搜索咖啡之后,就会在电商平台发现咖啡相关的推荐商品,手机 App 似乎在时刻监视你的网络生活。很多人甚至怀疑 App 在窃听用户,这在理论上可行,但实际上并不成立。
实时监听对话有很高的带宽成本,巨大的流量很容易被用户察觉,也会给公司带来很高的存储和人员压力,是一笔不划算的买卖。并且,仅就定向推荐而言,已经有很成熟的技术支持,亚马逊在二十年前就使用的邻近算法推荐在今天依旧在广泛运用。
最为关键的是,窃听用户本身就是违法的,越是大公司,对数据合规就越谨慎。
而科技公司之所以能做到这种近乎监控式的广告推送,都建立在对用户的信息采集上。科技公司通常会搜集三类用户数据——行为数据:比如网页浏览历史、停留时长、使用了哪些在线服务;消费记录:比如你购买了哪些商品、退换货记录;个人信息:用户的年龄、学历、性别、所在地区等。
这些信息在后台就是一个个事实标签。通过算法,这些标签就形成了所谓的用户画像。在大公司内部,这些数据是流通的。这也就是为什么你在谷歌搜索的商品会出现在 Youtube 的前插广告中,早在 2006 年,谷歌就以 16.5 亿美元(约合 107.25 亿元人民币)的价格收购了 Youtube。
除此之外,这些大公司也会为中小 App、网站提供相似的用户分析服务,并通过平台联系广告主投放广告,形成广告联盟。
这种做法最早由亚马逊发明,时至今日,大型的科技公司几乎都创建了类似的广告联盟,Facebook 的 Audience Network,谷歌的 Adsence,阿里巴巴的友盟,腾讯的广点通和字节跳动的穿山甲。
在这些公司对外的口径中,所有的数据都是经过脱敏处理的,所输出的是一个群体画像,无法从中反推出个人信息。但这些信息是如何采集的,又是如何在公司的内部和外部流通的,对于普通用户来说依旧是一个无法打破的黑箱。而目前也并没有一家科技公司明确地地向用户披露这个过程。
当科技公司频频爆出数据泄漏丑闻时,这种「不透明」就成为了用户恐惧的源头。2018 年,英国咨询公司剑桥分析(Cambridge Analytica)就被爆出在未经 Facebook 用户同意的情况下,利用 5000 万用户数据为美国前总统唐纳德·特朗普(Donald Trump)的竞选活动提供帮助。
事后,有人在 Twitter 上发起了 #DeleteFacebook 的运动,好莱坞导演罗素兄弟甚至以此为题材拍摄了一部电影。
「为什么我的数据,成为了你牟利的工具?」这可能是绝大多数 Facebook 用户的心声。尤其当数据交易已经成为一门事实上的生意时,数据的归属权,就成为了一个绕不开的问题。
尚无定论的「数据确权」问题
等价交换是通行千年的交易准则,买卖双方一手交钱,一手交货,完成价值交换。
而对于定向广告而言,交易的双方发生在公司和广告主之间,用户并不从中获利。很多用户对于信息采集的反感都来自于此:我好像失去了什么东西,但并没有得到相应的回报,而那些科技公司却轻松赚取了上亿的利润。
关于数据的归属权,主流的评论大致有两种观点。
有一方观点认为数据的归属权应该归平台所有,因为用户享受了科技公司提供的免费服务。经济学家薛兆丰曾经引用过著名的「科斯定律」。
一项有价值的资源,不管从一开始他的产权归谁,最后这项资源都会流动到最善于利用他、能最大化利用其价值的人受理区。这是科斯定律的一个重要含义。而在制度设计中,我们应该尽量让这种资源的流动和分配更方便、容易,从而提高各项经济资源的使用效率。
简单来说,薛兆丰的结论是,(资源)谁用得好,就应该归谁。从经济学的角度来说,这是效率最高的方式。
市场研究公司爱德曼·博岚(Edelman Berland)曾对全球 15 个国家的 1.5 万名用户展开调查:「你愿意以牺牲一些隐私为代价,换取更多便利与舒适吗?」有 51% 的受访者表示不愿意,27% 表示愿意,剩下的受访者没有意见或不知道如何回答。
这揭示了一个关于隐私的悖论:公众越来越意识到在线共享数据的风险,但是,为了某种便利,人们依旧在披露自己的数据。
因为用户往往是最没有话语权的,也很难对数据使用产生有效的监督。当科技公司的产品已经成为了某种意义上的基础设施时,用户没有别的选择。举个例子,即使你不同意微信的隐私条款,也很难不使用微信,因为你所有的社交关系几乎都在微信上。
另一方观点认为数据理所当然应该归用户所有。2018 年 5 月 25 日生效的《欧盟通用保护数据条列》(General Data Protection Regulations,GDPR)号称「史上最严格的隐私保护法」。在这部条列中,人类首次在法律层面上明确了用户数据的所有权属于用户,而平台只能管理及合理使用这些数据。
但是在我国,数据的归属权问题还没有明确的结论。我国 2021 年实施的《民法典》明确了「个人信息」的定义和处理原则,必须征得个人同意才能处理个人信息,但没有明确个人信息的归属权。而 2017 年生效的《网络安全法》,包括正在审议的《数据安全法》和《个人信息保护法》,也都未明确个人信息的归属权。法律的缺位,造成了个人数据确权的模糊。
技术带来的问题,最终要靠技术来解决
20 世纪 30 年代,由于摄影技术的进步,新闻业开始在报纸中大量使用照片。但这些照片往往未经个人同意。
1980 年,律师萨缪尔·沃伦(Samuel D. Warren)和路易斯·布兰戴斯(Louis Brandeis)就这个问题在《哈佛法学评论》发表文章《隐私权》,这是法学界首次提出了隐私权的概念。
 沃伦和布兰戴斯发表在《哈佛法学评论》上的文章:《隐私权》|图片来源:布兰戴斯大学
沃伦和布兰戴斯发表在《哈佛法学评论》上的文章:《隐私权》|图片来源:布兰戴斯大学
技术的扩张侵犯了个人的边界,从一开始,技术就与隐私相伴而生。
在眼下数据流通越来越严格,而数据红利将尽的情况下,包括谷歌、英特尔、微众银行在内的许多公司都在开发一种叫做联邦学习或者共享学习的技术。
由于数据合规或者商业竞争的关系,许多数据在行业甚至公司内部都无法流通,这就是公司们头疼的「数据孤岛」问题。
联邦学习是隐私计算的一种。在手机上训练模型后,它只将模型加密上传,而把用户的数据留在了本地。
微众银行的首席 AI 官杨强曾经把这个模型比作是「羊」,而数据就是「草料」。
过去训练模型的做法是从各个草场运草过来喂羊。但是在运送过程中,草有丢失的风险,这就是数据泄漏。
联邦学习的做法是,让这头「羊」走起来,到各个草场自己吃草。这样,草就永远只留在本地,也就没有了丢失的风险。
 主人不知道羊吃了哪些草,但羊依旧长大了|图片来源:微众银行
主人不知道羊吃了哪些草,但羊依旧长大了|图片来源:微众银行
其实把模型训练比作「耕牛」可能更好理解,这些耕牛原来是吃八方来的数据草料,变得强壮后再成为企业服务客户的「生产力」。而现在是把「耕牛」送到用户的田地里,吃用户数据草料,也直接更好地服务用户。加上「数据模型的集体升级能力」,这让你家的牛也和其他的牛可以一起成长,更好地服务你。
显然,通过技术模式的进步,才可以根本上避免数据泄露和恶意使用。对于日趋白热化的数据争夺而言,有了这种根本性的改变,才可以让公司间的数据共享成为可能。而在技术上建立一套数据保护的制度,也才能赢得用户的信任。
说到底,没有任何的公司,可以依靠价值观来成为个人数据问题的救世主。这些由技术带来的问题,最终还是需要由技术来解决它。

