
《如何打一场数据挖掘赛事》入门版
—— 贡献者:牧小熊、骆秀韬
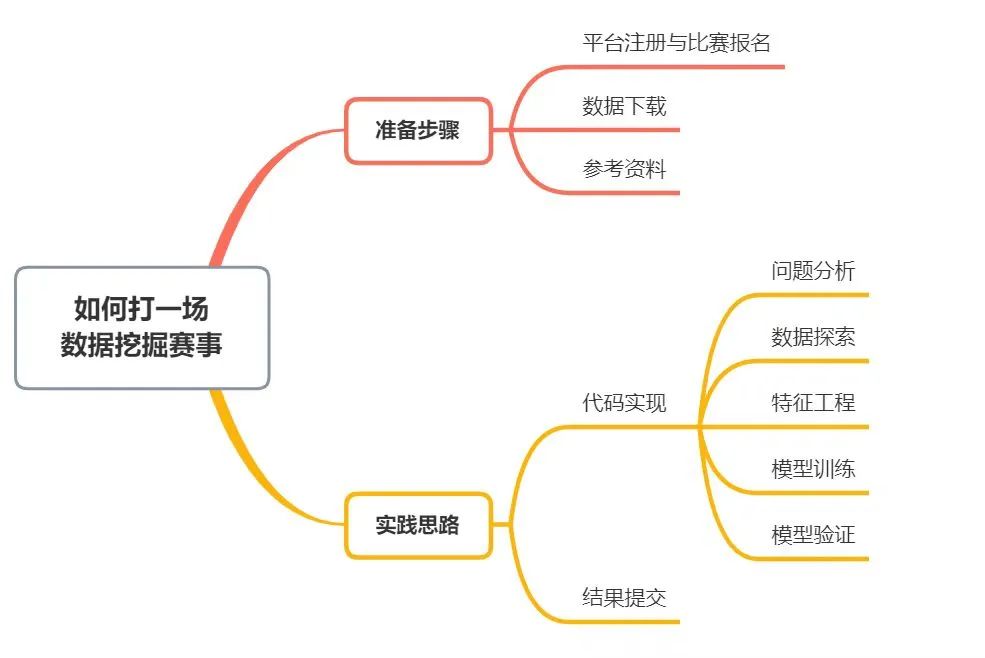
一、准备步骤
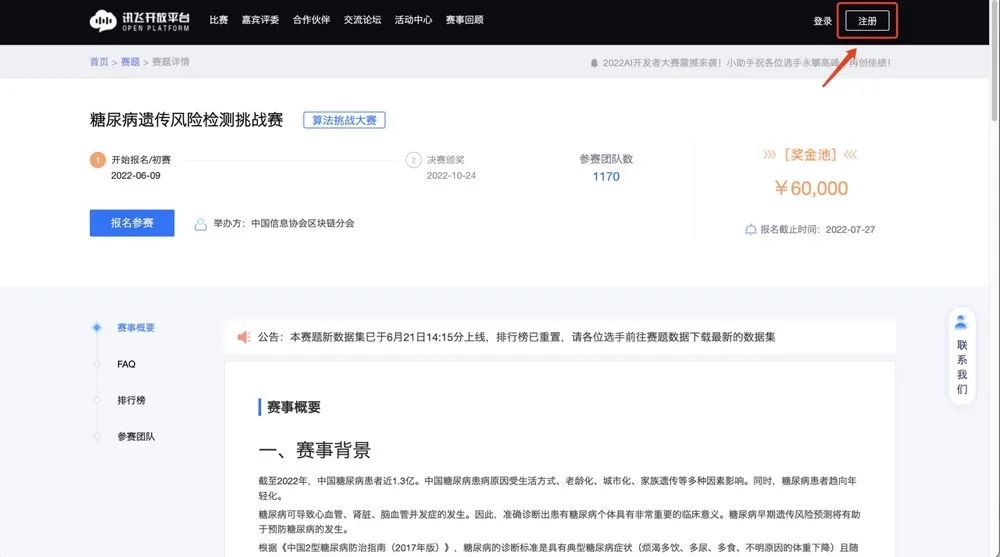
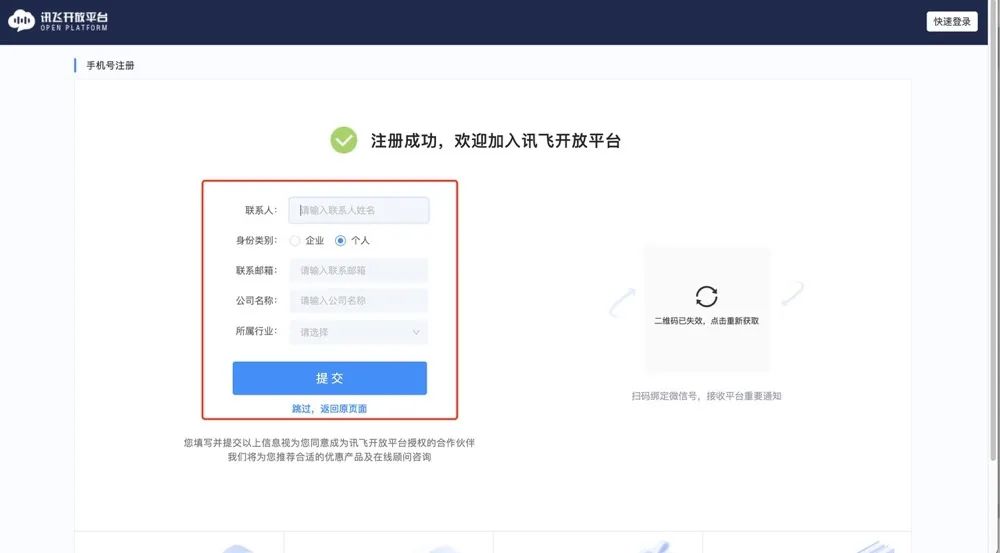
1.1 平台注册与比赛报名
赛事链接:
https://challenge.xfyun.cn/topic/info?type=diabetes&ch=ds22-dw-gzh02注册(记得填写个人信息)
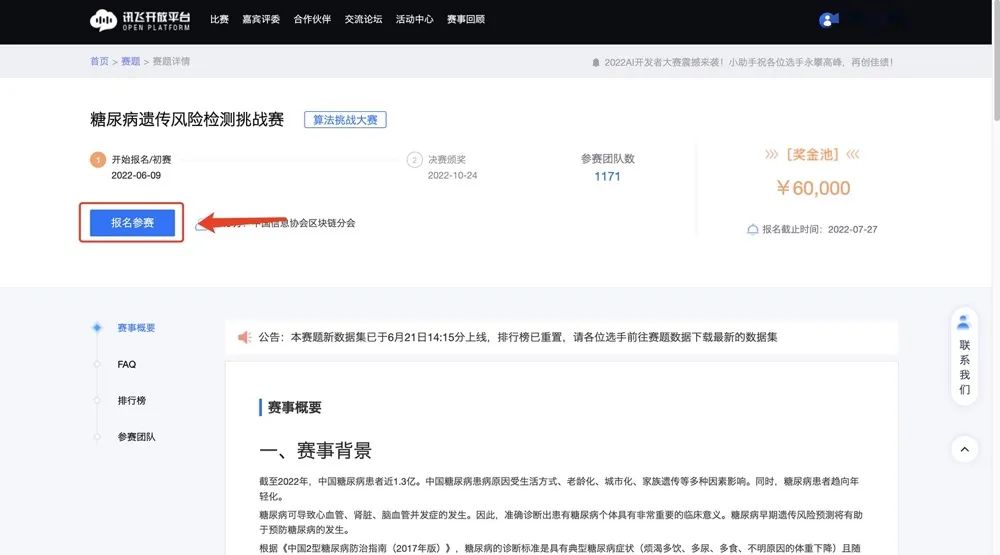
点击报名参赛,显示成功报名
1.2 数据下载
数据获取
官网下载数据:下载数据及实名认证。
详细操作可查看:https://xj15uxcopw.feishu.cn/docx/doxcn11gwo7cEuAXWhCrDld4Inb请把数据文件和代码文件放在同一个文件夹下,保证正常运行
1.3 参考资料
python环境的搭建请参考:
Mac设备:Mac上安装Anaconda最全教程
https://zhuanlan.zhihu.com/p/350828057Windows设备:Anaconda超详细安装教程 https://blog.csdn.net/fan18317517352/article/details/123035625
二、实践思路
本次比赛是一个数据挖掘赛,需要选手通过训练集数据构建模型,然后对验证集数据进行预测,预测结果进行提交。
本题的任务是构建一种模型,该模型能够根据患者的测试数据来预测这个患者是否患有糖尿病。这种类型的任务是典型的二分类问题(患有糖尿病 / 不患有糖尿病),模型的预测输出为 0 或 1 (患有糖尿病:1,未患有糖尿病:0)
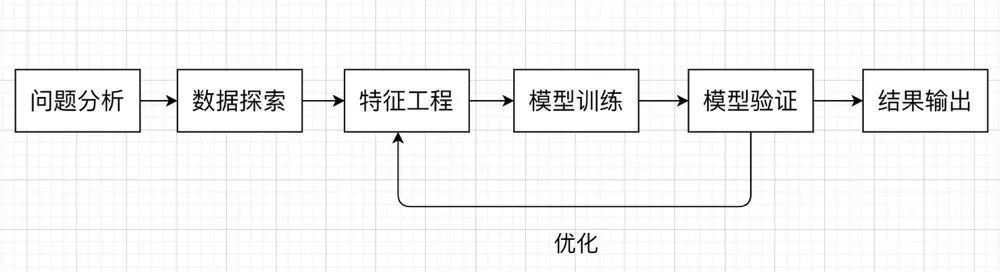
机器学习中,关于分类任务我们一般会想到逻辑回归、决策树等算法,在这个 Baseline 中,我们尝试使用决策树来构建我们的模型。我们在解决机器学习问题时,一般会遵循以下流程:
2.1 代码实现
以下代码,请在jupyter notbook或python编译器环境中实现
#安装相关依赖库 如果是windows系统,cmd命令框中输入pip安装,参考上述环境配置
#!pip install sklearn
#!pip install pandas
#---------------------------------------------------
#导入库
#----------------数据探索----------------
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
#数据预处理
data1=pd.read_csv('比赛训练集.csv',encoding='gbk')
data2=pd.read_csv('比赛测试集.csv',encoding='gbk')
#label标记为-1
data2['患有糖尿病标识']=-1
#训练集和测试机合并
data=pd.concat([data1,data2],axis=0,ignore_index=True)
#将舒张压特征中的缺失值填充为-1
data['舒张压']=data['舒张压'].fillna(-1)
#----------------特征工程----------------
"""
将出生年份换算成年龄
"""
data['年龄']=2022-data['出生年份'] #换成年龄
"""
人体的成人体重指数正常值是在18.5-24之间
低于18.5是体重指数过轻
在24-27之间是体重超重
27以上考虑是肥胖
高于32了就是非常的肥胖。
"""
def BMI(a):
if a<18.5:
return 0
elif 18.5<=a<=24:
return 1
elif 24<a<=27:
return 2
elif 27<a<=32:
return 3
else:
return 4
data['BMI']=data['体重指数'].apply(BMI)
#糖尿病家族史
"""
无记录
叔叔或者姑姑有一方患有糖尿病/叔叔或姑姑有一方患有糖尿病
父母有一方患有糖尿病
"""
def FHOD(a):
if a=='无记录':
return 0
elif a=='叔叔或者姑姑有一方患有糖尿病' or a=='叔叔或姑姑有一方患有糖尿病':
return 1
else:
return 2
data['糖尿病家族史']=data['糖尿病家族史'].apply(FHOD)
"""
舒张压范围为60-90
"""
def DBP(a):
if 0<=a<60:
return 0
elif 60<=a<=90:
return 1
elif a>90:
return 2
else:
return a
data['DBP']=data['舒张压'].apply(DBP)
#------------------------------------
#将处理好的特征工程分为训练集和测试集,其中训练集是用来训练模型,测试集用来评估模型准确度
#其中编号和患者是否得糖尿病没有任何联系,属于无关特征予以删除
train=data[data['患有糖尿病标识'] !=-1]
test=data[data['患有糖尿病标识'] ==-1]
train_label=train['患有糖尿病标识']
train=train.drop(['编号','患有糖尿病标识','出生年份'],axis=1)
test=test.drop(['编号','患有糖尿病标识','出生年份'],axis=1)
#----------------模型训练----------------
model = DecisionTreeClassifier()
model.fit(train, train_label)
y_pre=model.predict(test)
y_pre
#----------------结果输出----------------
result=pd.read_csv('提交示例.csv')
result['label']=y_pre
result.to_csv('result-de.csv',index=False)
2.2 结果提交
在提交结果处提交,提交 预测结果.csv(程序生成的CSV文件),查看自己的成绩排名


往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 机器学习交流qq群955171419,加入微信群请扫码
评论