
【Python】整理20个Pandas统计函数
公众号:尤而小屋
作者:Peter
编辑:Peter
最近整理了pandas中20个常用统计函数和用法,建议收藏学习~

模拟数据
为了解释每个函数的使用,模拟了一份带有空值的数据:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.DataFrame({
"sex":["male","male","female","female","male"],
"age":[22,24,25,26,24],
"chinese":[100,120,110,100,90],
"math":[90,np.nan,100,80,120], # 存在空值
"english":[90,130,90,80,100]})
df
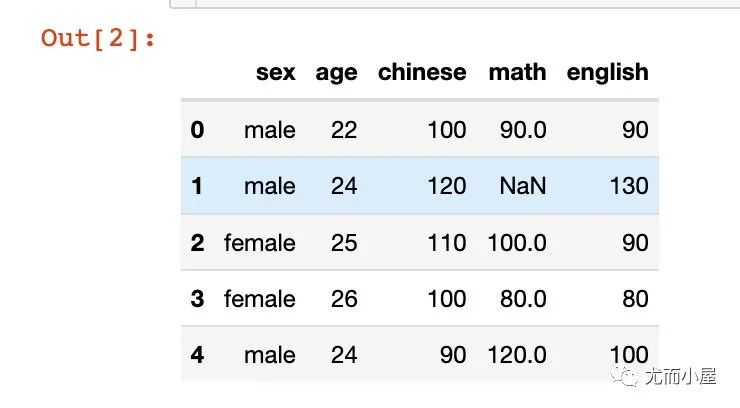
描述统计信息describe
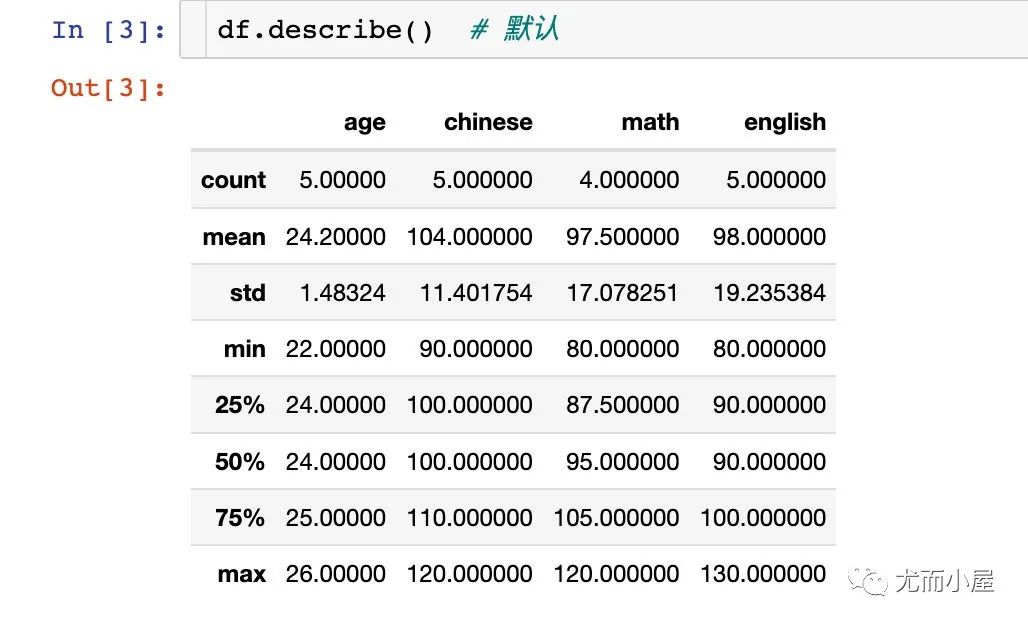
descirbe方法只能针对序列或数据框,一维数组是没有这个方法的;同时默认只能针对数值型的数据进行统计:
DataFrame.describe(percentiles=None,include=None,exclude=None)
percentiles:可选折的百分数,列表形式;数值在0-1之间,默认是[.25,.5,.75] include/exclude:包含和排除的数据类型信息
返回的信息包含:
非空值的数量count;特例:math字段中有一个空值 均值mean 标准差std 最小值min 最大值max 25%、50%、75%分位数
df.describe()
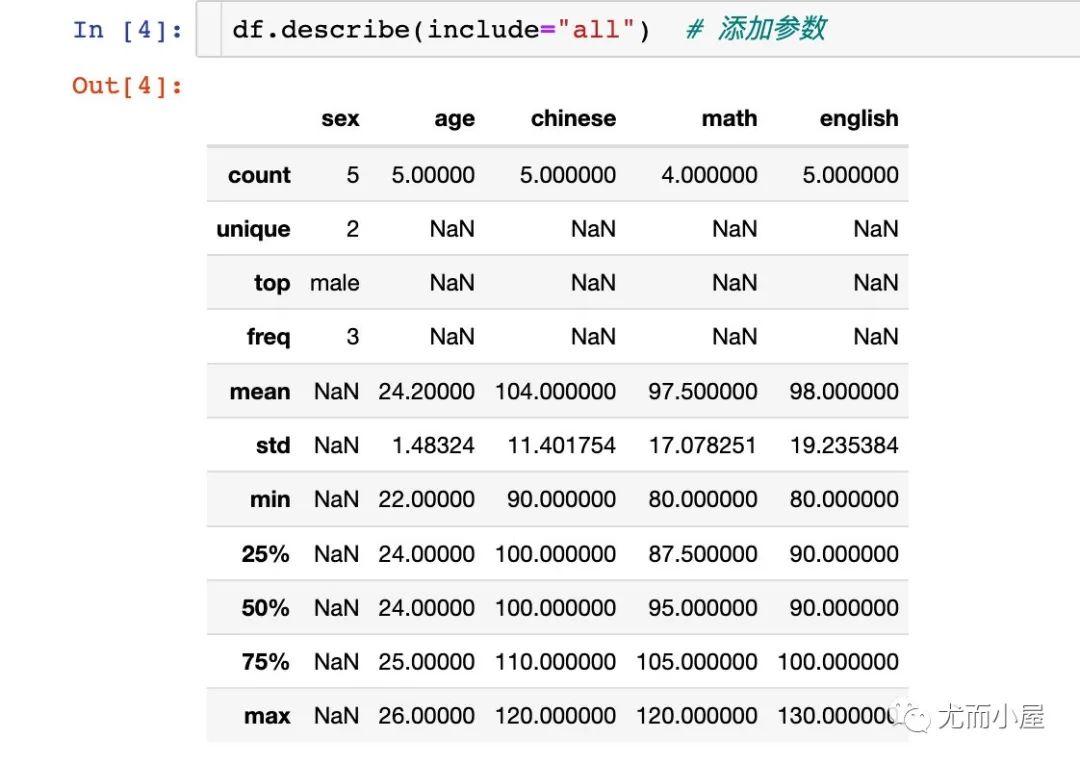
添加了参数后的情况,我们发现:
sex字段的相关信息也被显示出来 显示的信息更丰富,多了unique、top、freq等等
非空值数量count
返回的是每个字段中非空值的数量
In [5]:
df.count()
Out[5]:
sex 5
age 5
chinese 5
math 4 # 包含一个空值
english 5
dtype: int64
求和sum
In [6]:
df.sum()
在这里我们发现:如果字段是object类型的,sum函数的结果就是直接将全部取值拼接起来
Out[6]:
sex malemalefemalefemalemale # 拼接
age 121 # 相加求和
chinese 520
math 390.0
english 490
dtype: object
最大值max
In [7]:
df.max()
针对字符串的最值(最大值或者最小值),是根据字母的ASCII码大小来进行比较的:
先比较首字母的大小 首字母相同的话,再比较第二个字母
Out[7]:
sex male
age 26
chinese 120
math 120.0
english 130
dtype: object
最小值min
和max函数的求解是类似的:
In [8]:
df.min()
Out[8]:
sex female
age 22
chinese 90
math 80.0
english 80
dtype: object
分位数quantile
返回指定位置的分位数
In [9]:
df.quantile(0.2)
Out[9]:
age 23.6
chinese 98.0
math 86.0
english 88.0
Name: 0.2, dtype: float64
In [10]:
df.quantile(0.25)
Out[10]:
age 24.0
chinese 100.0
math 87.5
english 90.0
Name: 0.25, dtype: float64
In [11]:
df.quantile(0.75)
Out[11]:
age 25.0
chinese 110.0
math 105.0
english 100.0
Name: 0.75, dtype: float64
通过箱型图可以展示一组数据的25%、50%、75%的中位数:
In [12]:
plt.figure(figsize=(12,6))#设置画布的尺寸
plt.boxplot([df["age"],df["chinese"],df["english"]],
labels = ["age","chinese","english"],
# vert=False,
showmeans=True,
patch_artist = True,
boxprops = {'color':'orangered','facecolor':'pink'}
# showgrid=True
)
plt.show()
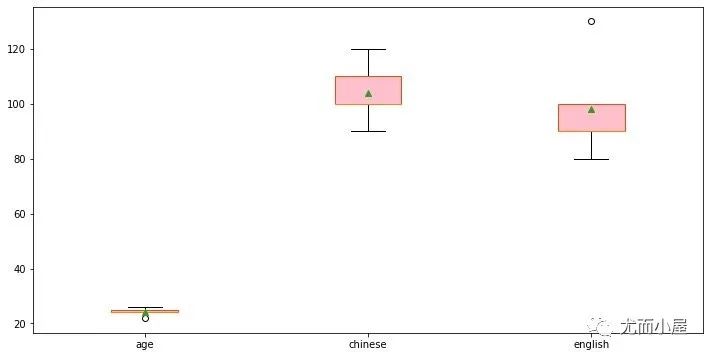
箱型图的具体展示信息:
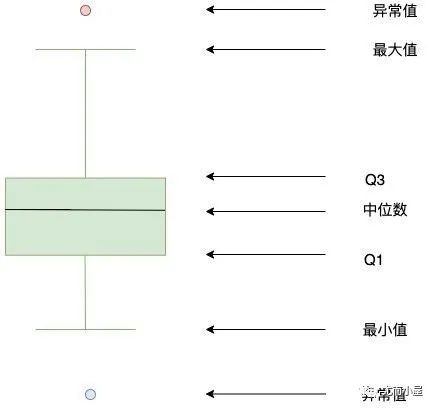
均值mean
一组数据的平均值
In [13]:
df.mean()
Out[13]:
age 24.2
chinese 104.0
math 97.5
english 98.0
dtype: float64
通过下面的例子我们发现:如果字段中存在缺失值(math存在缺失值),此时样本的个数会自动忽略缺失值的总数
In [14]:
390/4 # 个数不含空值
Out[14]:
97.5
中值/中位数median
比如:1,2,3,4,5 的中位数就是3
再比如:1,2,3,4,5,6 的中位数就是 3+4 = 3.5
In [15]:
df.median()
Out[15]:
age 24.0
chinese 100.0
math 95.0
english 90.0
dtype: float64
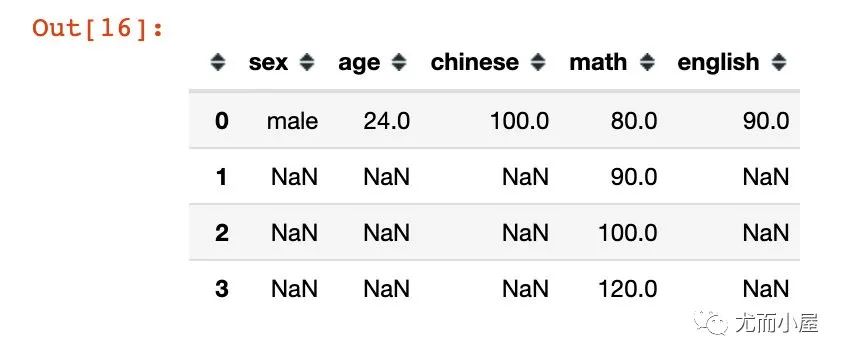
众数mode
一组数据中出现次数最多的数
In [16]:
df.mode()
Out[16]:
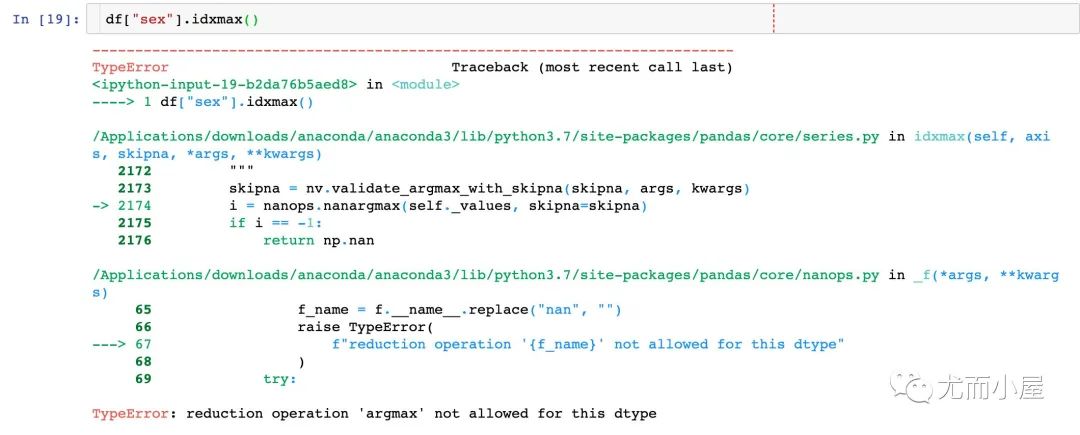
最大值索引idmax
idxmax() 返回的是最大值的索引
In [17]:
df["age"].idxmax()
Out[17]:
3
In [18]:
df["chinese"].idxmin()
Out[18]:
4
不能字符类型的字段使用该函数,Pandas不支持:
In [19]:
df["sex"].idxmax()
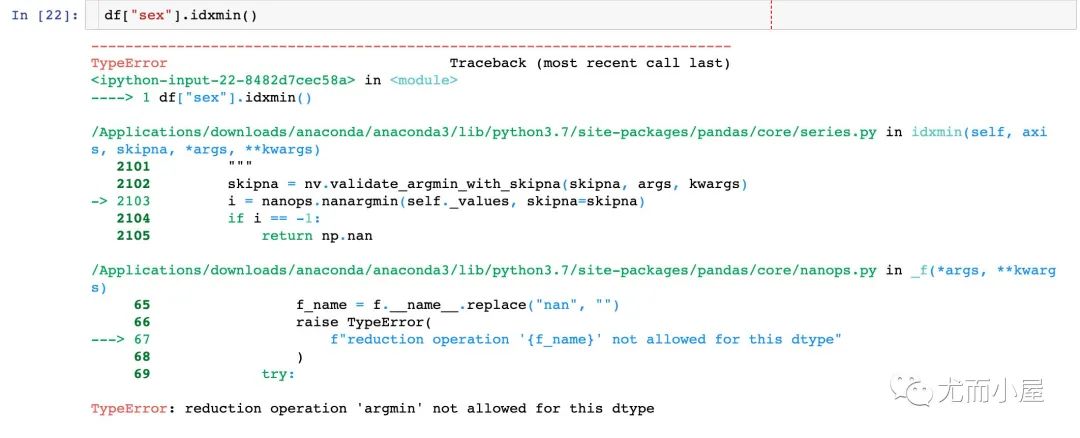
最小值索引idxmin
返回最小值所在的索引
In [20]:
df["age"].idxmin()
Out[20]:
0
In [21]:
df["math"].idxmin()
Out[21]:
3
In [22]:
df["sex"].idxmin()
不能字符类型的字段使用该函数,Pandas不支持:
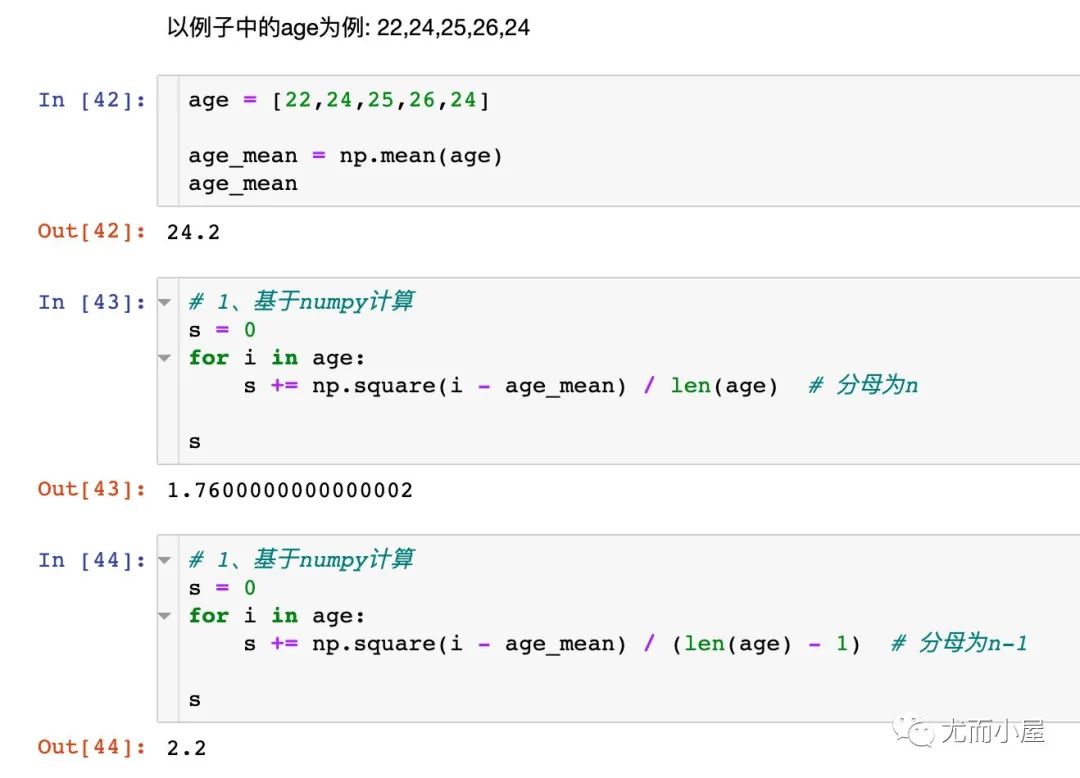
方差var
计算一组数据的方差,需要注意的是:numpy中的方差叫总体方差,pandas中的方差叫样本方差
标准差(或方差)分为 总体标准差(方差)和 样本标准差(方差)
前者分母为n,右偏的;后者分母为n-1,是无偏的 pandas里是算无偏的;numpy里是有偏的
In [23]:
df.var()
Out[23]:
age 2.200000
chinese 130.000000
math 291.666667 # pandas计算结果
english 370.000000
dtype: float64
In [24]:
df["math"].var()
Out[24]:
291.6666666666667
In [25]:
np.var(df["math"]) # numpy计算结果
Out[25]:
218.75
In [26]:
np.var(df["age"])
Out[26]:
1.7600000000000002
In [27]:
np.var(df["english"])
Out[27]:
296.0
标准差std
返回的是一组数据的标准差
In [28]:
df.std()
Out[28]:
age 1.483240
chinese 11.401754
math 17.078251
english 19.235384
dtype: float64
In [29]:
np.std(df["math"])
Out[29]:
14.79019945774904
In [30]:
np.std(df["english"])
Out[30]:
17.204650534085253
In [31]:
np.std(df["age"])
Out[31]:
1.32664991614216
如何理解pandas和numpy两种方法对方差的求解不同:
平均绝对偏差mad

In [32]:
df.mad()
Out[32]:
age 1.04
chinese 8.80
math 12.50
english 13.60
dtype: float64
以字段age为例:
In [33]:
df["age"].mad()
Out[33]:
1.0399999999999998
In [34]:
df["age"].tolist()
Out[34]:
[22, 24, 25, 26, 24]
In [35]:
age_mean = df["age"].mean()
age_mean
Out[35]:
24.2
In [36]:
(abs(22-age_mean) + abs(24-age_mean) + abs(25-age_mean)
+ abs(26-age_mean) + abs(24-age_mean)) / 5
Out[36]:
1.0399999999999998
偏度-skew
介绍峰度和偏度的好文章:https://www.cnblogs.com/wyy1480/p/10474046.html
偏度(skewness),是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。
偏度(Skewness)亦称偏态、偏态系数,表征概率分布密度曲线相对于平均值不对称程度的特征数。
直观看来就是密度函数曲线尾部的相对长度。定义上偏度是样本的三阶标准化矩:
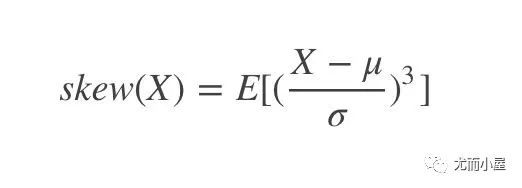
In [37]:
df.skew()
Out[37]:
age -0.551618
chinese 0.404796
math 0.752837
english 1.517474
dtype: float64
In [38]:
df["age"].skew()
Out[38]:
-0.5516180692881046
峰度-kurt
返回的是峰度值
In [39]:
df.kurt()
Out[39]:
age 0.867769
chinese -0.177515
math 0.342857
english 2.607743
dtype: float64
In [40]:
df["age"].kurt()
Out[40]:
0.8677685950413174
In [41]:
df["math"].kurt()
Out[41]:
0.3428571428571434
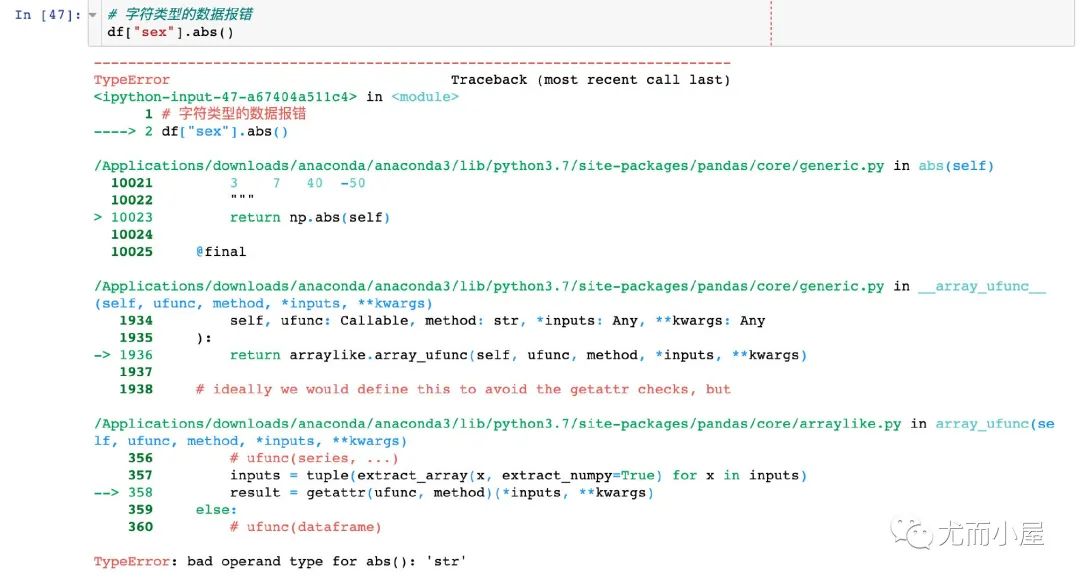
绝对值abs
返回数据的绝对值:
In [45]:
df["age"].abs()
Out[45]:
0 22
1 24
2 25
3 26
4 24
Name: age, dtype: int64
如果存在缺失值,绝对值函数求解后仍是NaN:
In [46]:
df["math"].abs()
Out[46]:
0 90.0
1 NaN
2 100.0
3 80.0
4 120.0
Name: math, dtype: float64
绝对值函数是针对数值型的字段,不能对字符类型的字段求绝对值:
In [47]:
# 字符类型的数据报错
df["sex"].abs()
元素乘积prod
In [48]:
df.prod()
Out[48]:
age 8.236800e+06
chinese 1.188000e+10
math 8.640000e+07
english 8.424000e+09
dtype: float64
In [49]:
df["age"].tolist()
Out[49]:
[22, 24, 25, 26, 24]
In [50]:
22 * 24 * 25 * 26 * 24
Out[50]:
8236800
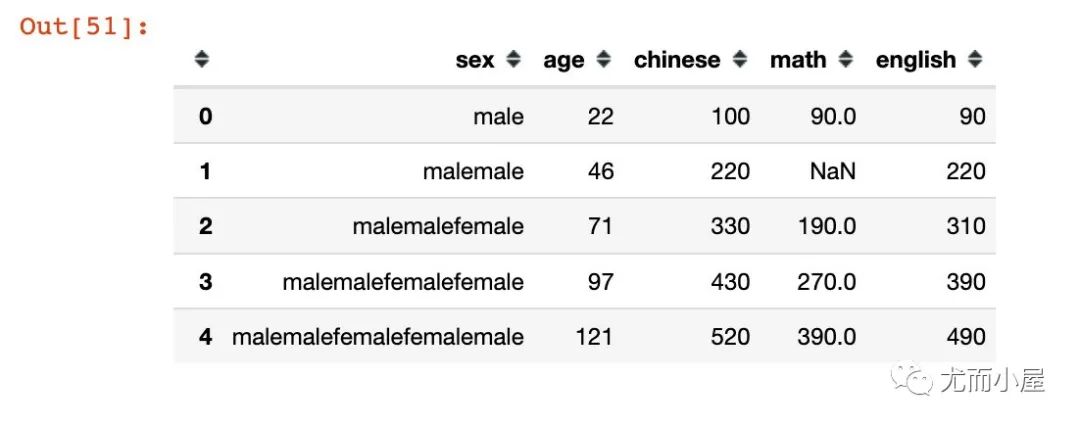
累计求和cumsum
In [51]:
df.cumsum()
累计乘积cumprod
In [52]:
df["age"].cumprod()
Out[52]:
0 22
1 528
2 13200
3 343200
4 8236800
Name: age, dtype: int64
In [53]:
df["math"].cumprod()
Out[53]:
0 90.0
1 NaN
2 9000.0
3 720000.0
4 86400000.0
Name: math, dtype: float64
In [54]:
# 字符类型字段报错
df["sex"].cumprod()

20个统计函数
最后再总结下Pandas中常用来描述统计信息的函数:

往期精彩回顾
适合初学者入门人工智能的路线及资料下载 (图文+视频)机器学习入门系列下载 中国大学慕课《机器学习》(黄海广主讲) 机器学习及深度学习笔记等资料打印 《统计学习方法》的代码复现专辑 AI基础下载 机器学习交流qq群955171419,加入微信群请扫码: