
阿里计算机视觉算法工程师岗面试题分享

问题1:BN过程,为什么测试和训练不一样?
对于BN,在训练时,是对每一批的训练数据进行归一化,也即用每一批数据的均值和方差。
而在测试时,比如进行一个样本的预测,就并没有batch的概念,因此,这个时候用的均值和方差是全量训练数据的均值和方差,这个可以通过移动平均法求得。
对于BN,当一个模型训练完成之后,它的所有参数都确定了,包括均值和方差,gamma和bata。

问题1:手写交叉熵损失函数
二分类交叉熵

多分类交叉熵
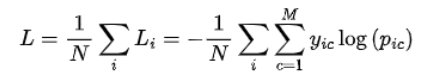
其中

问题2:结构风险和经验风险怎么理解
期望风险:机器学习模型关于真实分布(所有样本)的平均损失称为期望风险
经验风险:机器学习模型关于训练集的平均损失称为经验风险,当样本数无穷大∞的时候趋近于期望风险(大数定律)
结构风险:结构风险 = 经验风险 + 正则化项
经验风险是局部的,基于训练集所有样本点损失函数最小化的。
期望风险是全局的,是基于所有样本点的损失函数最小化的。
经验风险函数是现实的,可求的。
期望风险函数是理想化的,不可求的。
问题3:l1和l2正则化的区别是什么,是什么原因导致的
L1是模型各个参数的绝对值之和。
L2是模型各个参数的平方和的开方值。
L1会趋向于产生少量的特征,而其他的特征都是0。
因为最优的参数值很大概率出现在坐标轴上,这样就会导致某一维的权重为0 ,产生稀疏权重矩阵
L2会选择更多的特征,这些特征都会接近于0。
最优的参数值很小概率出现在坐标轴上,因此每一维的参数都不会是0。当最小化||w||时,就会使每一项趋近于0。
L1的作用是为了矩阵稀疏化。假设的是模型的参数取值满足拉普拉斯分布。
L2的作用是为了使模型更平滑,得到更好的泛化能力。假设的是参数是满足高斯分布。
问题4:BN的计算流程和优点
BN大致的计算流程?
1)计算样本均值。
2)计算样本方差。
3)样本数据标准化处理。
4)进行平移和缩放处理。引入了γ和β两个参数。来训练γ和β两个参数。引入了这个可学习重构参数γ、β,让我们的网络可以学习恢复出原始网络所要学习的特征分布。
BN的优点?
1)加快训练速度,这样我们就可以使用较大的学习率来训练网络。
2)提高网络的泛化能力。
3)BN层本质上是一个归一化网络层,可以替代局部响应归一化层(LRN层)。
4)可以打乱样本训练顺序(这样就不可能出现同一张照片被多次选择用来训练)论文中提到可以提高1%的精度。
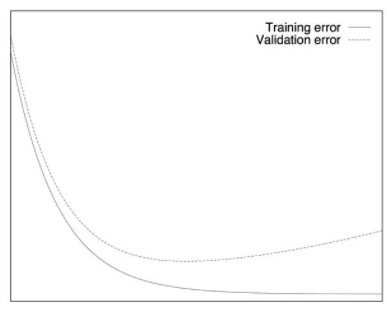
问题5:模型过拟合解决方法,为什么提前停止可以解决过拟合问题?
当模型在训练集上表现很好,在验证集上表现很差的时候,则出现了过拟合情况。
降低模型复杂度
增加更多的训练数据:使用更大的数据集训练模型
数据增强
正则化:L1、L2、添加BN层
添加Dropout策略
Early Stopping
早停:在训练中计算模型在验证集上的表现,当模型在验证集上的表现开始下降的时候,停止训练,这样就能避免继续训练导致过拟合的问题。
当模型在训练集上表现很好,在验证集上表现很差的时候,则出现了过拟合情况。

— 推荐阅读 —
最新大厂面试题
学员最新面经分享
七月内推岗位
AI开源项目论文
NLP ( 自然语言处理 )
CV(计算机视觉)
推荐