
计算机视觉——YOLO算法原理
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
YOLO:You only look once.

YOLO算法基本原理
将一张图片等分为S*S个区域 每一个区域负责检测,目标对象的中心落在本区域内的物体 每个预测到的物体会产生多个可能的边界框 每个单元格会产生一个[有无对象Pc,x,y,w,h,class1,class2,classN]向量
初次看到这个算法的过程,会很疑惑,因为这个过程缺少了一些细节。
例如:如何检测物体的中心?如何产生可能的边界框?如何判断边预测的界框是否正确?让我们看后面的内容。
交并比(IoU)
交并比是一个评估边界预测好坏的评估算法。
通常,当IoU>=0.5,视为预测正确。
0.5的取值完全认为,可以设置其他的,根据具体精度要求来决定。
如果预测结果和真实结果完全重合,IoU=1.
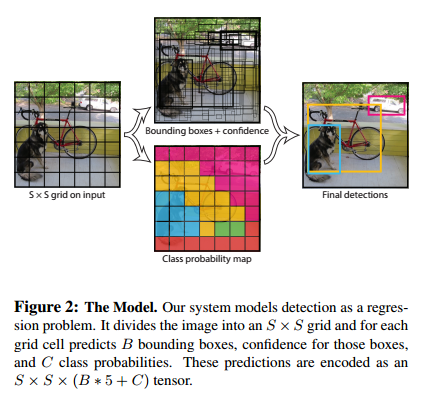
训练方法
首先让我们来看这个网络结构,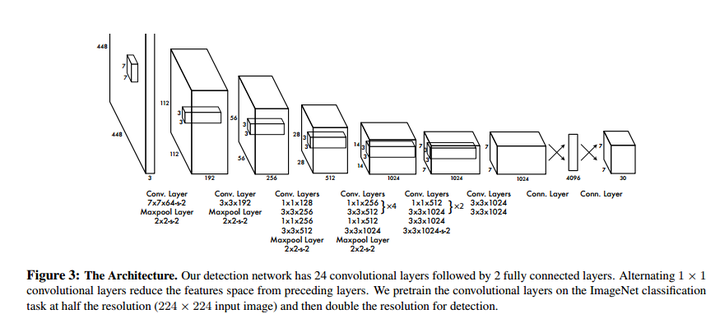 该结构是一个常规的卷积网络结构。从网络中可以得到,适用卷积核,按照卷积核大小的步长进行卷积,这样就实现了把一个图片分成多一个区域。大大减少了图片的卷积次数,但是也降低了精准度(相比滑动窗口检测方法)。
该结构是一个常规的卷积网络结构。从网络中可以得到,适用卷积核,按照卷积核大小的步长进行卷积,这样就实现了把一个图片分成多一个区域。大大减少了图片的卷积次数,但是也降低了精准度(相比滑动窗口检测方法)。
然后再来看Loss函数,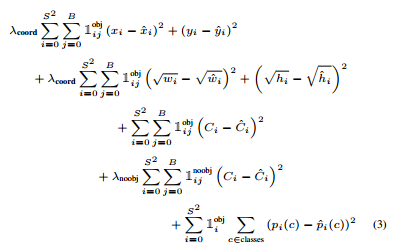 Loss函数由四部分组成:
Loss函数由四部分组成:
对象存在误差 位置误差 边框大小误差 类别分类误差
的意思指,当没有对象时(no object)为1,否则为0.
非最大值抑制
如何检测到物体的中心?
当很多方框中都有要检测的目标的时候,
这些方框会说,嘿!我的区域里面有你要的对象!
那么这个时候,到底哪个方框才是物体的中心呢?
也确实没办法知道,所以就让这些方框都进行检测这个物体。
那么就会得到一个物体,被多个方框所框住。
通过非最大值抑制算法可以实现,确保图片中的每一个物体,只被一个方框给框住,而不会出现同一个物体上出现多个方框。
具体的过程:
有无对象(Pc),在"算法原理"中提到
通过YOLO算法进行预测 将有无对象(Pc)<0.6(或者其他值)的结果去除 对剩下的结果进行以下循环: 找到Pc最大的一个数据,这个就是最终要的结果 通过计算其他产生的边界框与Pc最大的数据的边界框进行IoU计算,去除IoU>=0.5的其他边界框。 直到没有新的最终结果的产生
通过这个循环,我们最终就会得到,确保每一个物体只有一个边界框,且这个边界框是可能性最大的。
在实际操作中,对于多个类型的物体,例如汽车,人,自行车等
应该对这三种类型进行三次的独立非最大值抑制
因为如果一起进行非最大值抑制的话,当人遮挡汽车的时候,人和车的结果就会不准确。两者的IoU比较大。
锚点框(Anchor Boxes)
为什么会产生这个算法呢?
在以下条件下:
YOLO的区域数量比较小,每个区域比较大 人遮挡车
导致,人和车的中心点不巧刚好落到同一个区域内,
而每个区域只能输出一个[有无对象Pc,x,y,w,h,class1,class2,classN]向量,那么CNN就会随机输出人或者车。
那么如何解决这个问题呢?
人是竖着的,车是横着的,那么我们可以让每一个区域负责去识别两次(由锚点框的数量决定)。
产生这样的一个向量:
[有无对象Pc,x,y,w,h,class1,class2,classN,有无对象Pc,x,y,w,h,class1,class2,classN],即[2*n],你也可以把,这个拆成[2,n]。
将结果分成两个区域,第一个是竖着的锚点框,第二个是横着的锚点框。
存放的时候,计算w/h(宽高比),和锚点的宽高比进行比较,相近即属于该锚点框。如此就可以解决这个问题了。
但是其实这个并不能解决3个物体重叠的情况, 也不能解决锚点框相似的情况的重叠,
不过值得庆幸的是,当YOLO的区域足够多的时候,发生重叠的概率比较小,如果不幸发生了,那就需要写一个选择算法,选择其中一个。
YOLO算法实现
借助YOLO算法,实现对水表的表盘目标检测。去Github下载
本文仅做学术分享,如有侵权,请联系删文。