
【机器学习特征工程基础】提取新特征提高模型准确性
↓↓↓点击关注,回复资料,10个G的惊喜
来源: DeepHub IMBA 本文约2300字,建议阅读8分钟
在本文中,通过一个实际示例讨论如何从 DateTime 变量中提取新特征以提高机器学习模型的准确性。
从日期中提取特征
一年中的一天或一个月中的一天或一周中的一天
一年中的月份
季节
年
import numpy as np
current_date = "2022-01-25 17:21:22"
cdate = datetime.strptime(current_date, '%Y-%m-%d %H:%M:%S')
day_sin = np.sin(2 * np.pi * cdate.timetuple().tm_yday/365.0)
day_cos = np.cos(2 * np.pi * cdate.timetuple().tm_yday/365.0)
df['month_sin'] = np.sin(2 * np.pi * df['date_time'].dt.month/12.0)
df['month_cos'] = np.cos(2 * np.pi * df['date_time'].dt.month/12.0)
df['year'] = df['date_time'].dt.year
从时间中提取特征
hour_sin = np.sin(2 * np.pi * cdate.hour/24.0)
hour_cos = np.cos(2 * np.pi * cdate.hour/24.0)
一个实际的例子
import pandas as pd
df = pd.read_csv('../input/weather-dataset/weatherHistory.csv')
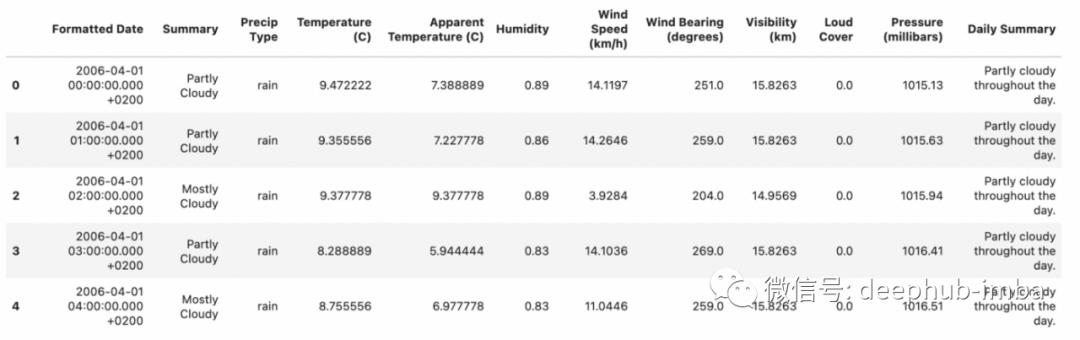
df['Loud Cover'].value_counts()
0.0 96453
Name: Loud Cover, dtype: int64
df.drop(['Daily Summary','Loud Cover'],axis=1,inplace=True)
df.isnull().sum()
Formatted Date 0
Summary 0
Precip Type 517
Temperature (C) 0
Apparent Temperature (C) 0
Humidity 0
Wind Speed (km/h) 0
Wind Bearing (degrees) 0
Visibility (km) 0
Pressure (millibars) 0
df.dropna(inplace=True)
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['Precip Type']=le.fit_transform(df['Precip Type'])
df['Summary']=le.fit_transform(df['Summary'])
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[df.columns[2:]] = scaler.fit_transform(df[df.columns[2:]])
import numpy as np
from datetime import datetime
def discretize_date(current_date, t):
current_date = current_date[:-10]
cdate = datetime.strptime(current_date, '%Y-%m-%d %H:%M:%S')
if t == 'hour_sin':
return np.sin(2 * np.pi * cdate.hour/24.0)
if t == 'hour_cos':
return np.cos(2 * np.pi * cdate.hour/24.0)
if t == 'day_sin':
return np.sin(2 * np.pi * cdate.timetuple().tm_yday/365.0)
if t == 'day_cos':
return np.cos(2 * np.pi * cdate.timetuple().tm_yday/365.0)
date_types = ['hour_sin', 'hour_cos', 'day_sin', 'day_cos']
for dt in date_types:
df[dt] = df['Formatted Date'].apply(lambda x : discretize_date(x, dt))
df.drop(['Formatted Date'],axis=1,inplace=True)
df.corr()
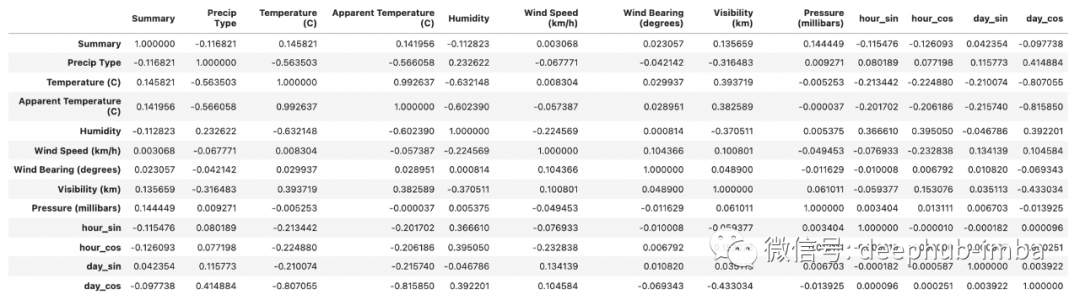
df.drop(['Apparent Temperature (C)'],axis=1,inplace=True)
from sklearn.model_selection import train_test_split
X = df.iloc[:,1:]
y=df.iloc[:,0]
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=1)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(max_depth=32,n_estimators=120,random_state=1)
model.fit(X_train,y_train)
y_pred = model.predict(X_test)
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_pred)
0.6695389319342622
model = RandomForestClassifier(max_depth=32,n_estimators=120,random_state=1)
model.fit(X_train[X_train.columns[:-4]],y_train)
y_pred = model.predict(X_test[X_test.columns[:-4]])
accuracy_score(y_test, y_pred)
0.5827108161634411
总结
三连在看,月入百万👇
评论