
【机器学习】特征工程:编码、创造和筛选特征
在机器学习和数据科学领域中,特征工程是提取、转换和选择原始数据以创建更具信息价值的特征的过程。假设拿到一份数据集之后,如何逐步完成特征工程呢?
步骤1:特性类型分析
不同类型的特征包含的信息不同的,首先需要按照赛题字段的说明去对每个字段的类型进行区分。
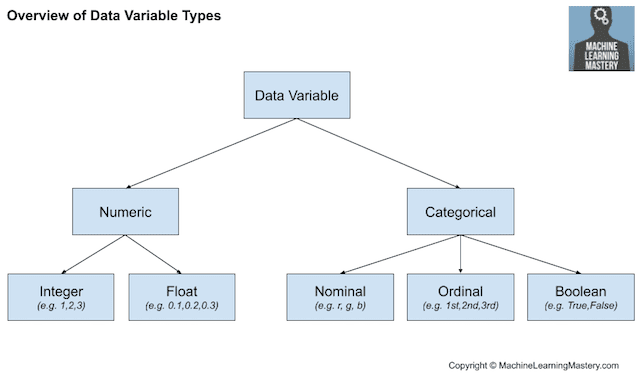
下面是对不同类型的特征进行编码和操作的方法,其中取值特征本身包含的信息较多,因此可以直接考虑进行缩放:
-
数值型特征:
-
缩放:将数值特征缩放到一个范围,通常使用Min-Max缩放或标准化(z-score)。
-
离散化:将连续数值转换为离散类别,例如分箱操作。
-
平滑化:应用平滑算法(如指数平滑)来减少噪声和波动。
-
派生新特征:通过组合或数学运算创建新的数值型特征。
-
类别型特征:
-
标签编码:将类别映射为整数,常用于树模型。
-
独热编码:将类别转换成二进制向量,适用于线性模型和神经网络。
-
有序编码:根据类别的有序关系,将其转换成整数编码。
-
统计特征:基于类别特征进行统计计算,如均值、频率等。
-
时间型特征:
-
提取时间信息:从时间戳中提取年、月、日、小时等信息作为新特征。
-
周期性处理:对于循环时间特征,可以使用正弦余弦变换将其转换为线性空间。
-
文本型特征:
-
词袋模型:将文本转换为向量表示,如TF-IDF、词频等。
-
词嵌入:使用词向量将单词映射到连续向量空间,如Word2Vec、GloVe。
-
文本长度:记录文本的长度作为一个特征。
-
图像型特征:
-
预训练网络特征提取:使用预训练的卷积神经网络(如VGG、ResNet)提取图像特征。
-
图像直方图:提取图像的颜色直方图作为特征。
-
组合特征:
-
特征交叉:将不同特征进行交叉组合,创造新的特征。
-
特征合并:将多个特征合并为一个更有意义的特征。
步骤2:找到关键特征
数据往往具有大量的特征,而并非所有特征都对目标变量有同等重要的影响。为了建立高性能的机器学习模型,我们需要找到关键特征,即对预测目标具有显著贡献的特征。

相关性分析
相关性是衡量两个变量之间线性关系强度的指标,可以用来发现特征与目标变量之间的关联程度。常用的相关性计算方法包括皮尔逊相关系数和斯皮尔曼等级相关系数。通过计算各个特征与目标变量之间的相关性,我们可以找到与目标变量强相关的特征。
树模型重要性
决策树和随机森林等树模型可以通过测量特征在树中分裂中的贡献度来评估特征的重要性。树模型重要性的计算方法通常包括特征在树中分裂的次数、特征带来的信息增益或基尼系数的变化等。
步骤3:对特征进行编码
在将数据纳入模型之前,还需要对特征进行编码,将原有的特征转换成数值形式,或者抽取出特征中的信息。
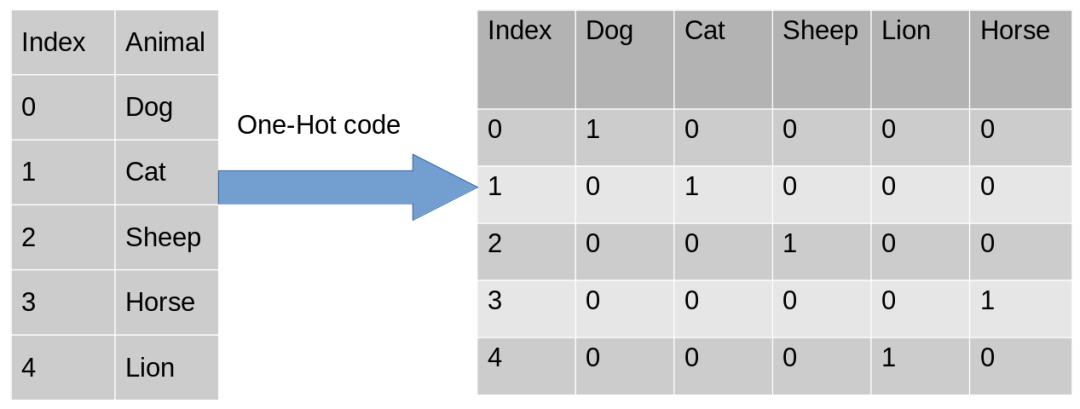
-
特征抽取:某些特征可能含有大量信息,但以原始形式难以表达,特征编码有助于从中抽取出有用的信息,提高模型的表现。
-
处理类别型数据:类别型特征常常需要进行编码,以便模型能够理解并学习它们之间的关系。
类别特征编码有多种方法可供选择,常见的包括标签编码、独热编码、二进制编码等。每种方法都有其优势和限制,因此需要综合考虑特征的属性和模型的要求,选择最适合的编码方式。在实际应用中,我们需要根据具体情况选择适合的编码方法,这需要考虑以下因素:
-
类别特征的性质:
-
若类别特征存在顺序关系,标签编码可能更合适,以保留类别之间的相对大小关系。
-
若类别特征之间没有顺序关系,独热编码或二进制编码可能更为合适,以避免引入错误的信息。
-
数据集的规模:
-
当数据集规模较大时,独热编码可能导致高维度问题,增加计算开销,可以考虑使用二进制编码或其他降维方法。
-
机器学习算法的要求:
-
不同的机器学习算法对特征编码的要求不同,需要根据使用的模型类型来选择合适的编码方式。
步骤4:构建基础模型
在进行特征工程后,下一步是构建Baseline(基础模型),这是机器学习任务中的重要步骤。Baseline是一个简单而基础的模型,用来作为后续模型优化和改进的起点。
Baseline模型不用过于复杂,也不需要调参。只需要能反应加入和删除特征精度有变化即可。
步骤5:构造新的特征
在特征工程的过程中,创造性地构造新的特征是一个关键步骤。通过构造新特征,我们可以进一步提取数据中的有用信息,增强模型的表达能力和泛化能力。

在特征构造时,我们可以优先从已确定的重要特征入手,因为这些特征对目标变量有显著贡献,可能携带着更多有用的信息。
-
分组统计特征:
-
对数据进行分组,例如按照类别特征、时间窗口等分组。
-
在每个组内,计算各种统计量,如平均值、标准差、最大值、最小值等,作为新特征。
-
排序特征:
-
对数据进行排序,例如按照时间顺序、数值大小等排序。
-
可以计算位置特征,如第一个出现、最后一个出现,或者计算排序之间的差值等。
-
时间序列特征:
-
如果数据具有时间性质,可以提取时间序列特征。
-
如计算滚动平均、滚动标准差、时间差分等。
-
统计特征:
-
利用历史信息计算统计特征,如过去一段时间内的均值、方差等。
-
这些统计特征可以反映数据的动态变化和趋势。
-
组合特征:
-
将不同特征进行组合,创建新的特征。
-
可以通过加、减、乘、除等数学运算进行组合。
在创造新特征时,需要注意新特征的含义和对问题的贡献。新特征应该能够更好地表达数据的特点和模式,同时避免引入噪声或不必要的信息。理解新特征的意义,有助于我们更好地解释模型的预测结果,并为特征选择提供指导。
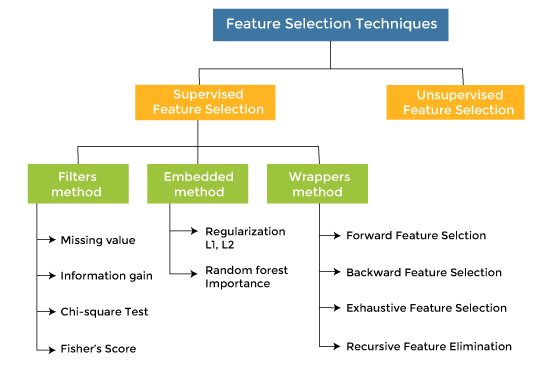
步骤6:特征筛选与验证
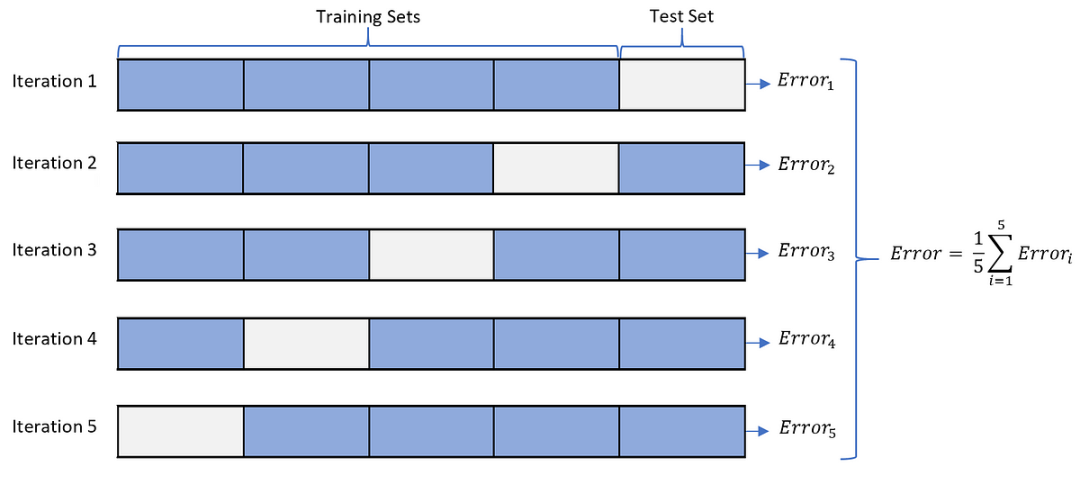
特征筛选是特征工程中的关键步骤之一,它有助于优化模型的复杂度和性能,同时保留对目标有意义的有效特征。在特征筛选过程中,我们需要添加新特征并验证Baseline模型的精度变化,同时注意精度变化是否是随机波动引起的。
在特征筛选过程中,我们需要注意精度变化是否只是由于随机波动导致的。为了排除随机性的影响,可以采用以下方法:
-
交叉验证(Cross-Validation):使用交叉验证可以降低随机性带来的影响,通过多次实验取平均值来评估特征的性能变化。
-
统计显著性检验:使用统计显著性检验(如t-test)来判断特征的添加是否显著提升了模型性能。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载
(图文+视频)机器学习入门系列下载
机器学习及深度学习笔记等资料打印
《统计学习方法》的代码复现专辑
交流群
欢迎加入机器学习爱好者微信群一起和同行交流,目前有机器学习交流群、博士群、博士申报交流、CV、NLP等微信群,请扫描下面的微信号加群,备注:”昵称-学校/公司-研究方向“,例如:”张小明-浙大-CV“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~(也可以加入机器学习交流qq群772479961)