
丢,我讲的是监控,不是QPS
大家好,我是3y
 今天austin项目来给大家整点不一样的:花点时间跟着文章做完,屏幕壁纸就可以有了,我来上个图,大家就懂了。
今天austin项目来给大家整点不一样的:花点时间跟着文章做完,屏幕壁纸就可以有了,我来上个图,大家就懂了。
每当同事一瞄你的电脑,发现都是图形化的、黑色的看起来就比较高端的界面:“嗯,这逼又在找Bug了吧”
没错,要聊的话题就是监控
01、为什么监控
过去在面试的时候,我记得曾经被问过:“线上出了问题,你们是怎么排查的?排查的思路是怎么样的?”
我以前的部门老大很看重稳定性,经常让我们梳理系统的上下链路和接口信息。我想:想要提高系统的稳定性就需要有完备的监控和及时告警。

有了监控,出了问题可以快速定位(而不是出了问题还在那里打印日志查找,很多问题都可以通过监控的数据就直接看出来了)。有了监控,我们可以把指标都配置在监控内,无论是技术上的还是业务上的(只不过业务的数据叫做看板,而系统的数据叫做监控)。有了监控我们看待系统的角度都会不一样(全方位理解系统的性能指标和业务指标)
如果你线上的系统还没有监控,那着实是不太行的了
02、监控开源组件
监控告警这种想都不用想,直接依赖开源组件就完事了,应该只有大公司才有人力去自研监控告警的组件了。
我选择的是Prometheus(普罗米修斯),这个在业内还是很出名的,有很多公司都是用它来做监控和告警。
从prometheus的官网我们可以从文档中找到一张架构图:
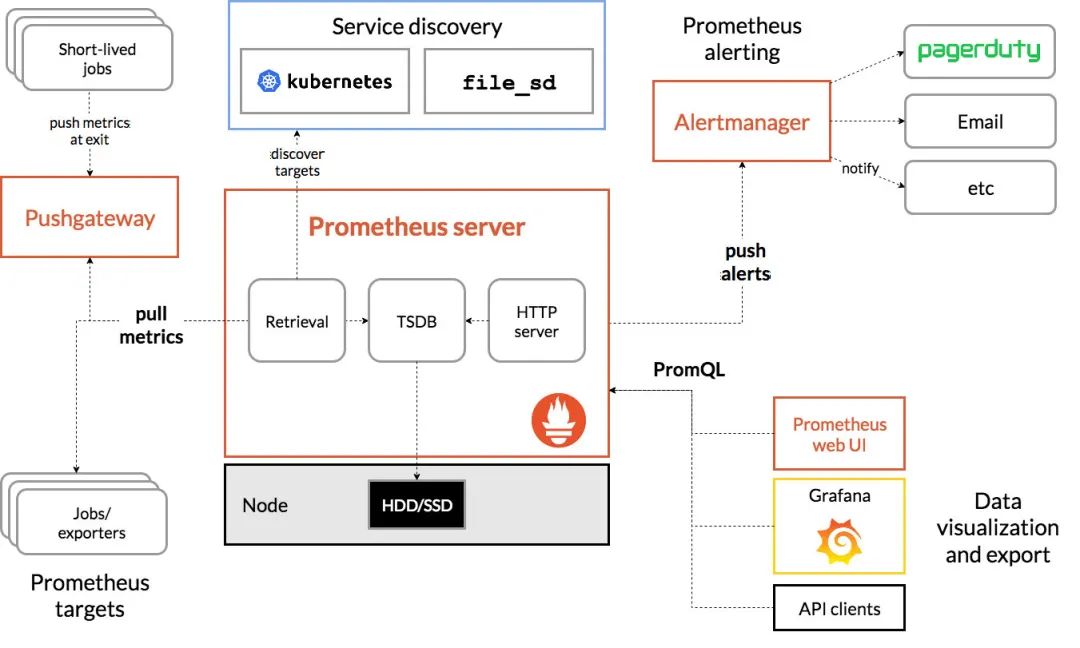
我把上面图以我的理解“不适当地”简化下
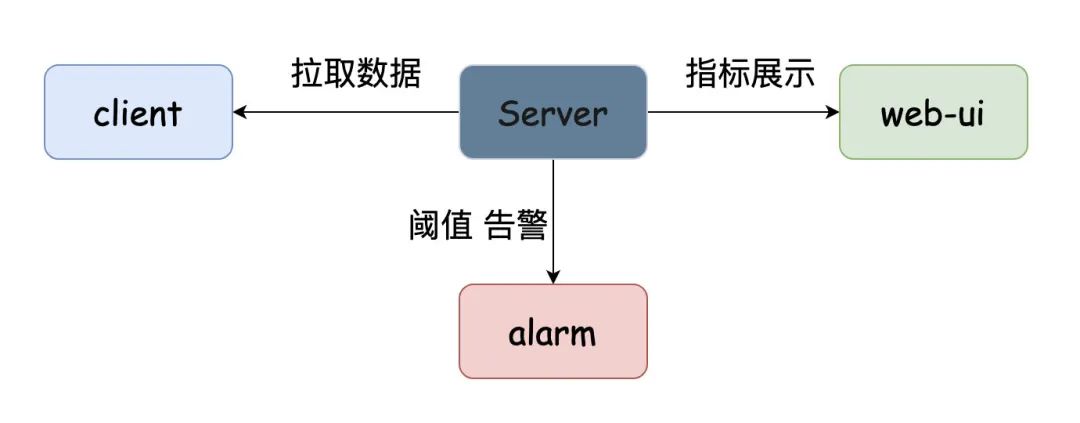
简化完了之后,发现:还是他娘的人家的图画得好看
总体而言,prometheus的核心是在于Server,我们要接入prometheus的话,实际上就是开放接口给prometheus拉取数据,然后在web-ui下配置图形化界面进而实现监控的功能。
03、prometheus环境搭建
对于prometheus的环境搭建,我这次也是直接用docker来弄了,毕竟Redis和Kafka都上了docker了。新建一个prometheus的文件夹,存放docker-compose.yml的信息:
version: '2'
networks:
monitor:
driver: bridge
services:
prometheus:
image: prom/prometheus
container_name: prometheus
hostname: prometheus
restart: always
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
# - ./node_down.yml:/usr/local/etc/node_down.yml:rw
ports:
- "9090:9090"
networks:
- monitor
alertmanager:
image: prom/alertmanager
container_name: alertmanager
hostname: alertmanager
restart: always
# volumes:
# - ./alertmanager.yml:/usr/local/etc/alertmanager.yml
ports:
- "9093:9093"
networks:
- monitor
grafana:
image: grafana/grafana
container_name: grafana
hostname: grafana
restart: always
ports:
- "3000:3000"
networks:
- monitor
node-exporter:
image: quay.io/prometheus/node-exporter
container_name: node-exporter
hostname: node-exporter
restart: always
ports:
- "9100:9100"
networks:
- monitor
cadvisor:
image: google/cadvisor:latest
container_name: cadvisor
hostname: cadvisor
restart: always
volumes:
- /:/rootfs:ro
- /var/run:/var/run:rw
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
ports:
- "8899:8080"
networks:
- monitor
这里拉取的镜像分别有:
cadvisor用于获取docker容器的指标node-exporter用户获取服务器的指标grafana监控的web-ui好用的可视化组件alertmanager告警组件(目前暂未用到)prometheus核心监控组件
新建prometheus的配置文件prometheus.yml(这份配置其实就是告诉prometheus要去哪个端口中拉取对应的监控数据)
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['ip:9090'] // TODO ip自己写
- job_name: 'cadvisor'
static_configs:
- targets: ['ip:8899'] // TODO ip自己写
- job_name: 'node'
static_configs:
- targets: ['ip:9100'] // TODO ip自己写
(这里要注意端口,按自己配置的来)
把这份prometheus.yml的配置往/etc/prometheus/prometheus.yml 路径下复制一份(有很多配置的信息我都忽略没写了,prometheus的功能还是蛮强大的,对监控想深入了解的可以官网看看文档)
随后在目录下docker-compose up -d启动,于是我们就可以分别访问:
http://ip:9100/metrics( 查看服务器的指标)http://ip:8899/metrics(查看docker容器的指标)http://ip:9090/(prometheus的原生web-ui)http://ip:3000/(Grafana开源的监控可视化组件页面)

一个docker-compose起了5个服务器,真好使!
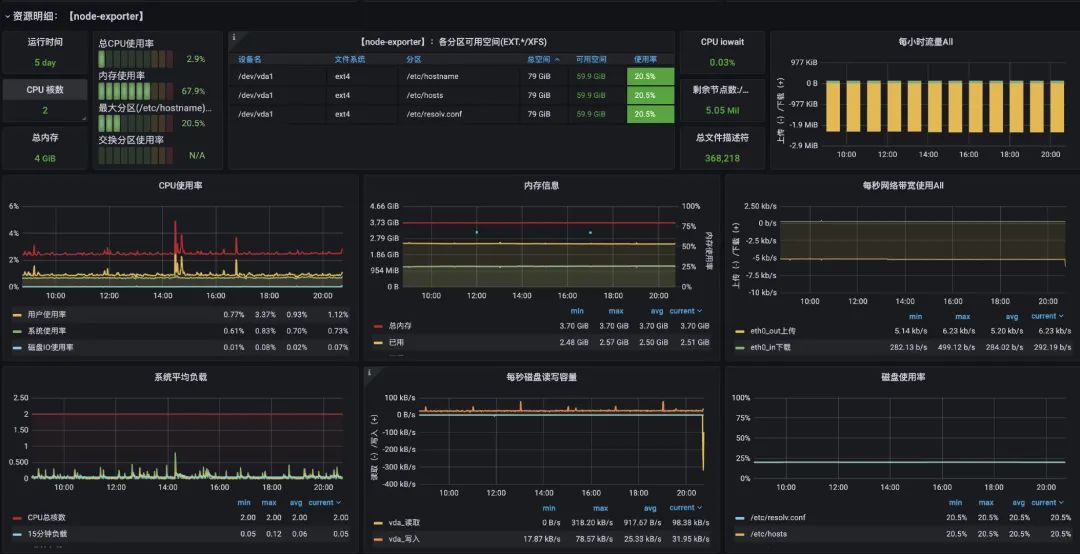
04、Grafana配置监控
既然我们已经起了Grafana了,就直接用Grafana作为监控的可视化工具啦(prometheus有自带的可视化界面,但我们就不用啦)。进到Grafana首页,我们首先要配置prometheus作为我们的数据源
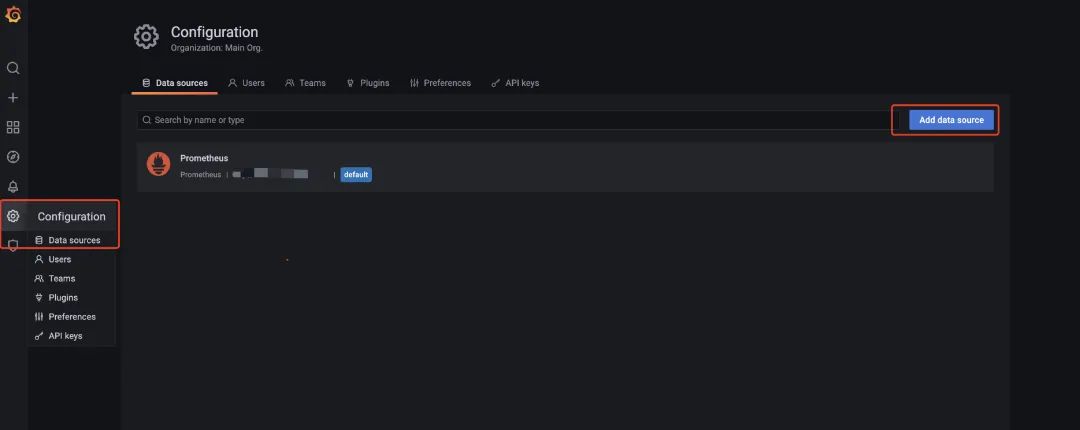
进到配置页面,写下对应的URL,然后保存就好了。
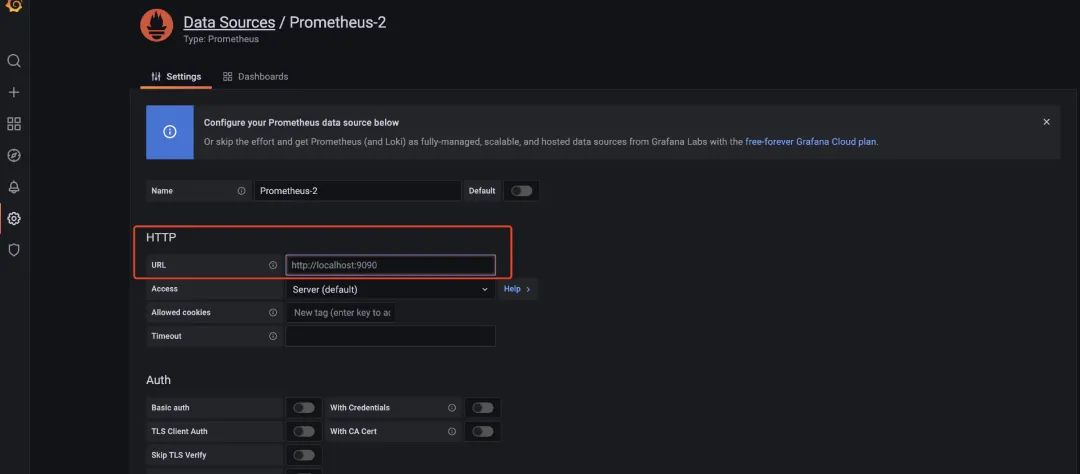
配置好数据源之后,我们就可以配置对应的监控信息了,常见的配置监控已经有对应的模板了,就不需要我们一个一个地去配置了。(如果不满足的话,那还是得自己去配)

在这里,我就演示如何使用现有的模板吧,直接import对应的模板,相关的模板可以在 https://grafana.com/grafana/dashboards/ 这里查到。
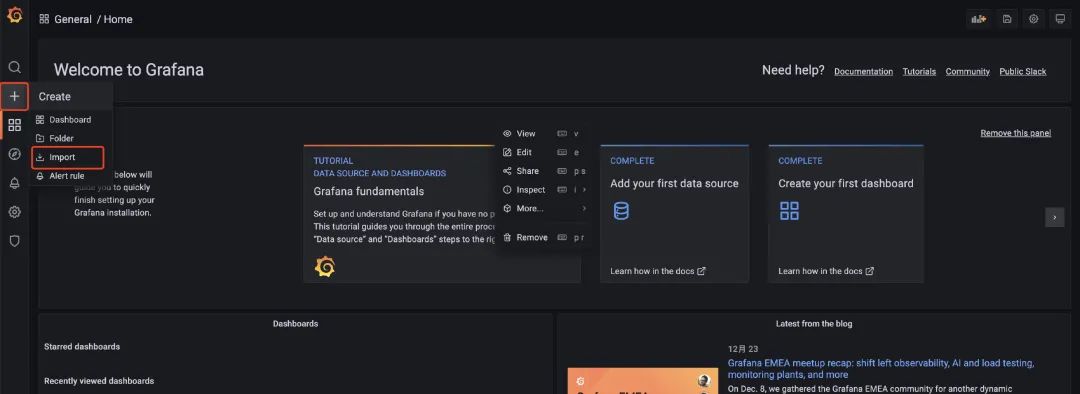
我们直接服务器的监控直接选用8913的就好了
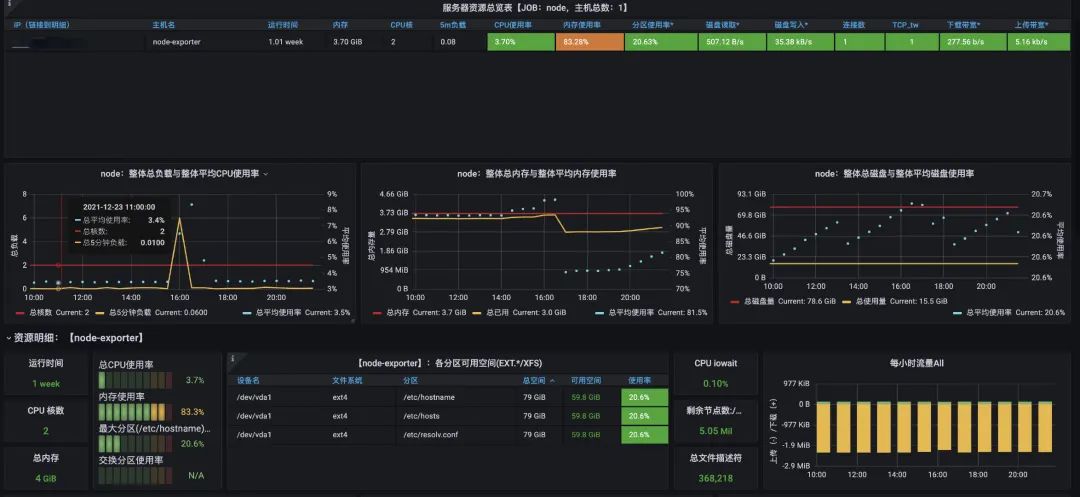
import后就能直接看到高大上的监控页面了:
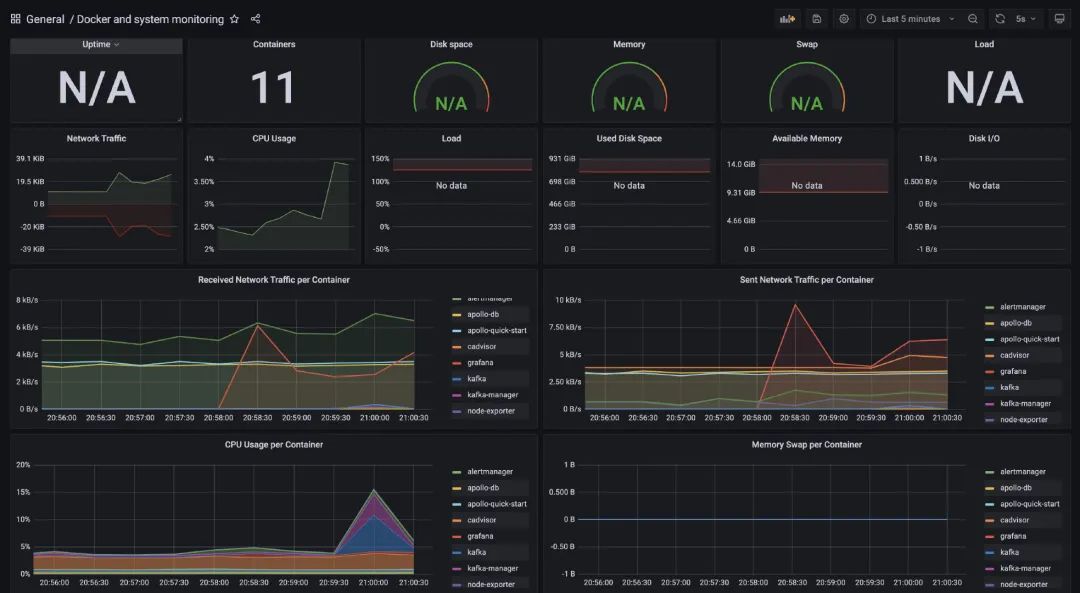
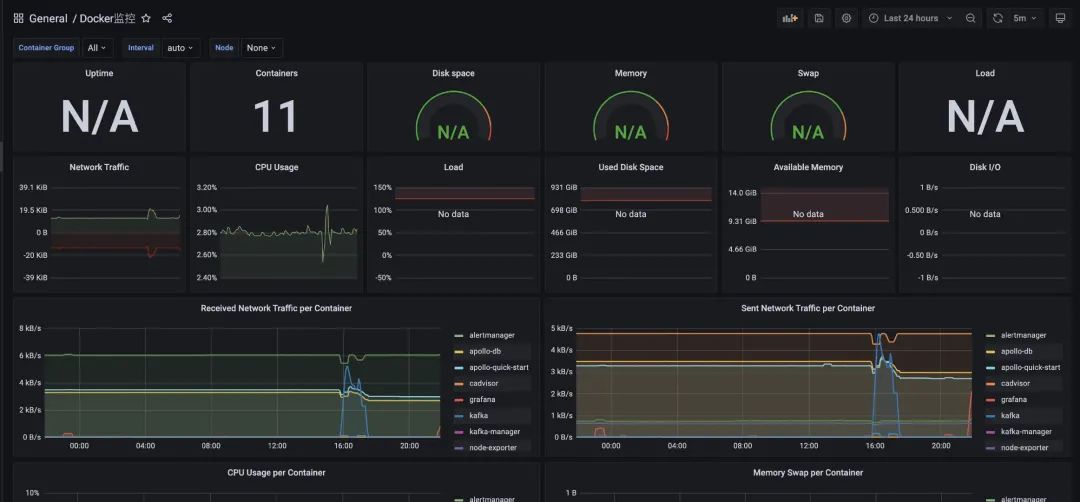
因为我们用docker启动的服务还是蛮多的,也可以看看Docker的监控(上面启动的cadvisor服务就采集了Docker的信息),我们使用模板893来配置监控docker的信息:
05、Java系统指标
没想到,通过上面短短的内容已经配置好了服务器和Docker服务的监控,但还是缺了什么对吧?我们写Java程序的,JVM相关的监控都没搞起来?这怎么能行啊。
所以,得支棱起来
配置Java的监控也特别简单,只要我们在项目中多引入两个pom依赖(SpringBoot自带的监控组件actuator)
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-actuatorartifactId>
dependency>
<dependency>
<groupId>io.micrometergroupId>
<artifactId>micrometer-registry-prometheusartifactId>
dependency>
然后在配置文件上加上对应的配置(开启监控并可以让prometheus拉取配置)
# 监控配置 TODO
management:
endpoint:
health:
show-details: always
metrics:
enabled: true
prometheus:
enabled: true
endpoints:
web:
exposure:
include: '*'
metrics:
export:
prometheus:
enabled: true
当我们启动服务后,访问/actuator路径就能看到一大堆输出的指标了,包括prometheus的
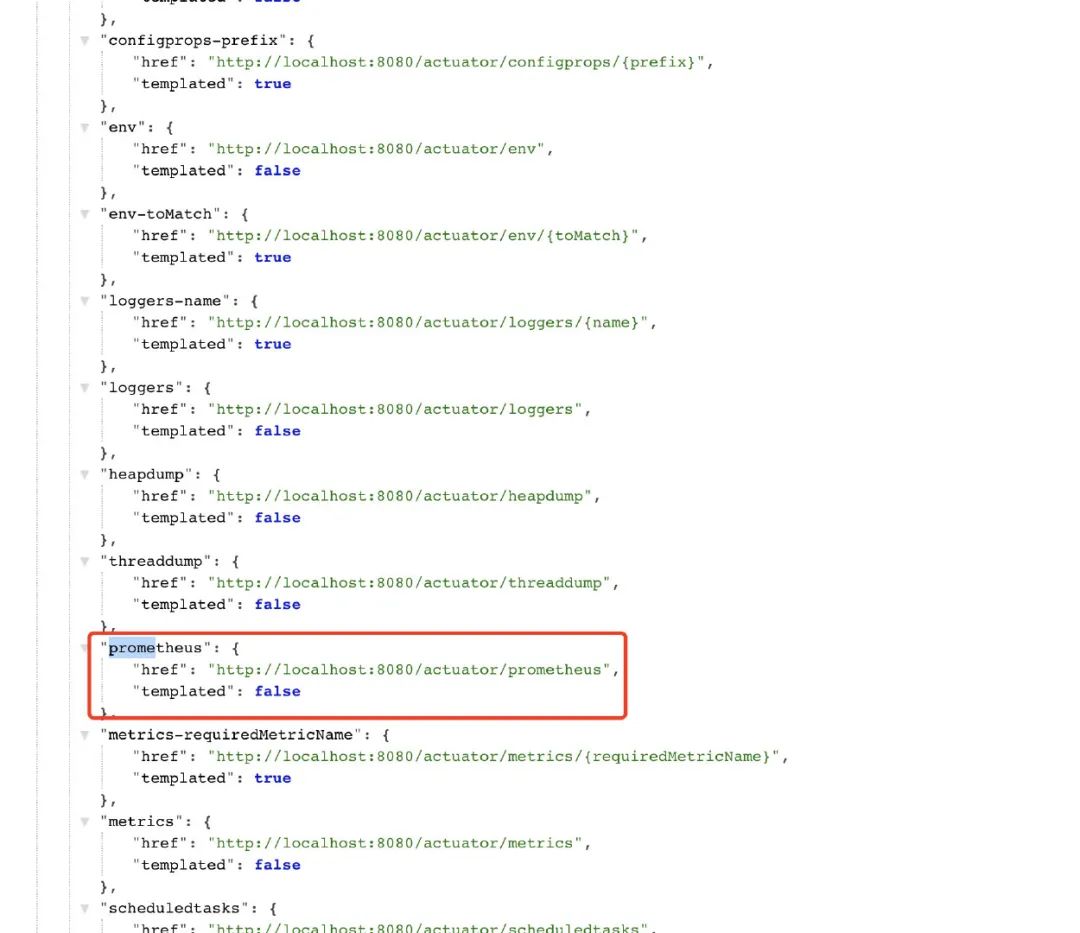
能看到这些指标被打印了,说明我们程序接入已经完成了,剩下的就是通过prometheus来采集应用的指标了。
要让prometheus采集到Java应用的数据,其实就是改下对应的配置文件就完事了。在前面写好的的prometheus.yml文件下添加相关的配置信息:
- job_name: 'austin'
metrics_path: '/actuator/prometheus' # 采集的路径
static_configs:
- targets: ['ip:port'] # todo 这里的ip和端口写自己的应用下的
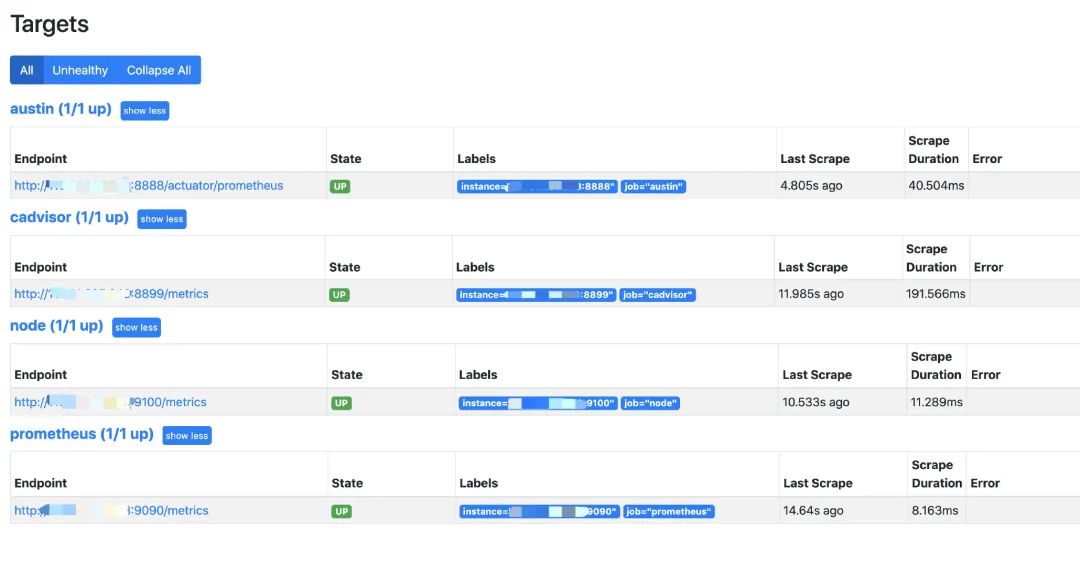
我们访问:ip:9090/targets这个路径下,能看到现在prometheus能采集到的端点有哪些,看到都是自己所配置的状态为up,那就说明正常了。
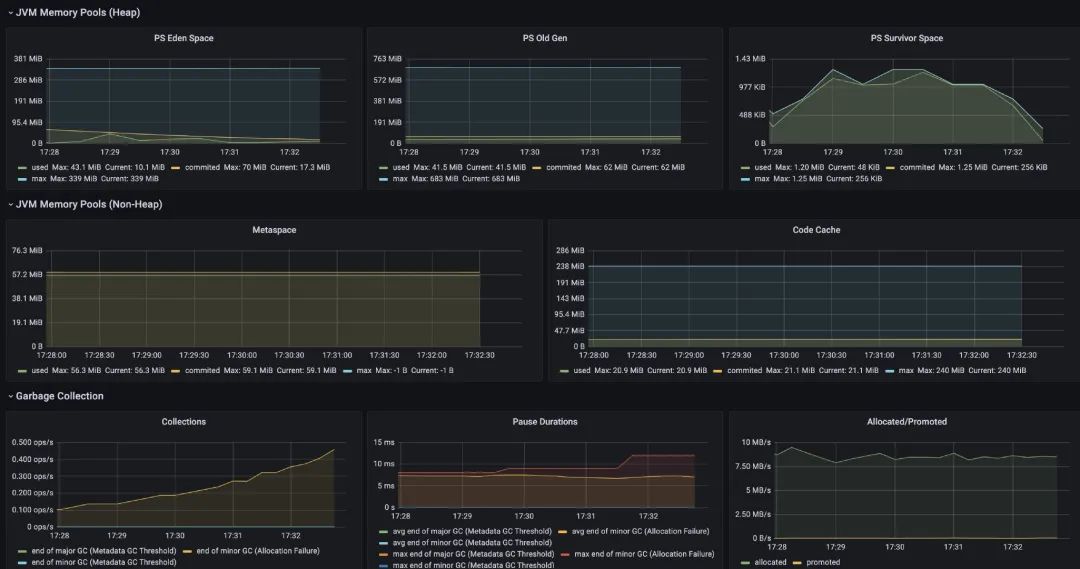
那我们继续在Grafana配置对应的监控就好啦。这里我选用了4701模板的JVM监控和12900SpringBoot监控,可以简单看下他们的效果:
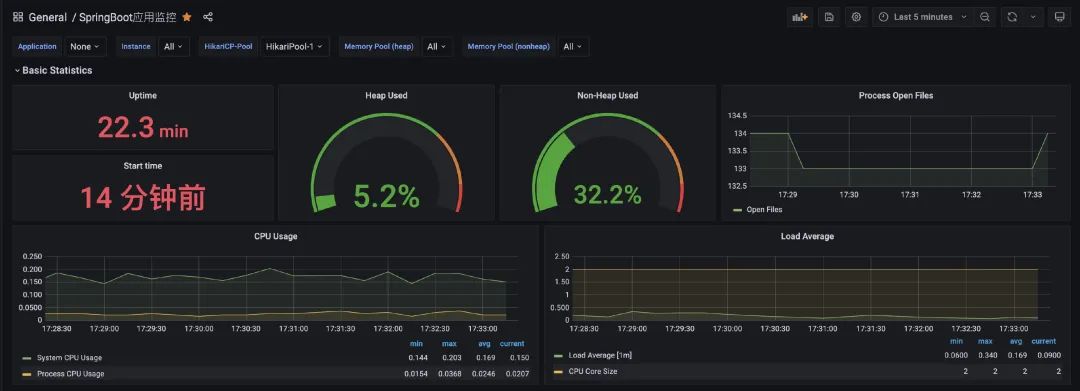
06、压测
到目前为止,我们想要发消息,都是通过HTTP接口进行调用的,而恰好的是,Spring actuator是能监控到HTTP的数据的。那我们就压测一把看看监控平台的指标会不会变?
这里我使用wrk这个压测工具来(它足够简单易用)所以,首先安装他(环境Centos 7.6):
sudo yum groupinstall 'Development Tools'
sudo yum install -y openssl-devel git
git clone https://github.com/wg/wrk.git wrk
cd wrk
make
# 将可执行文件移动到 /usr/local/bin 位置
sudo cp wrk /usr/local/bin
# 验证安装是否成功
wrk -v
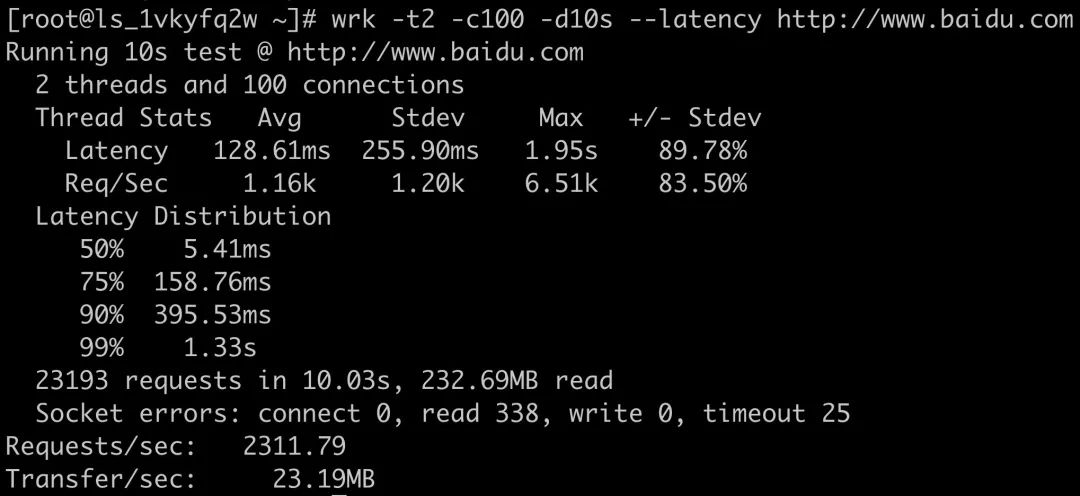
压测下百度来玩玩:wrk -t2 -c100 -d10s --latency http://www.baidu.com (开两个线程 并发100 持续10s 请求百度)
压测下我们的接口,完了之后看数据:wrk -t4 -c100 -d10s --latency 'http://localhost:8888/sendSmsTest?phone=13888888888&templateId=1'
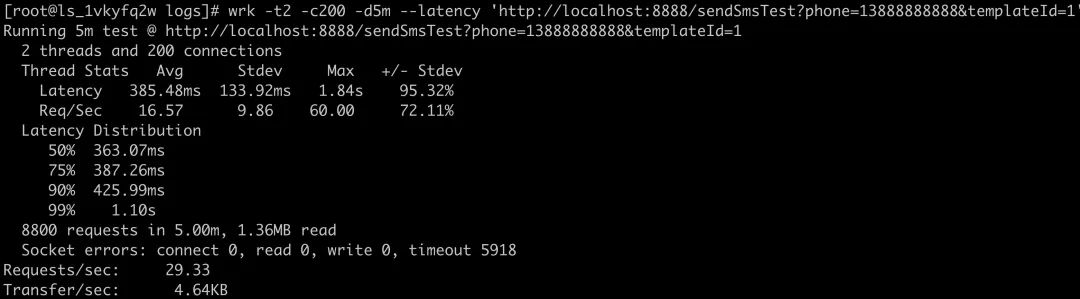
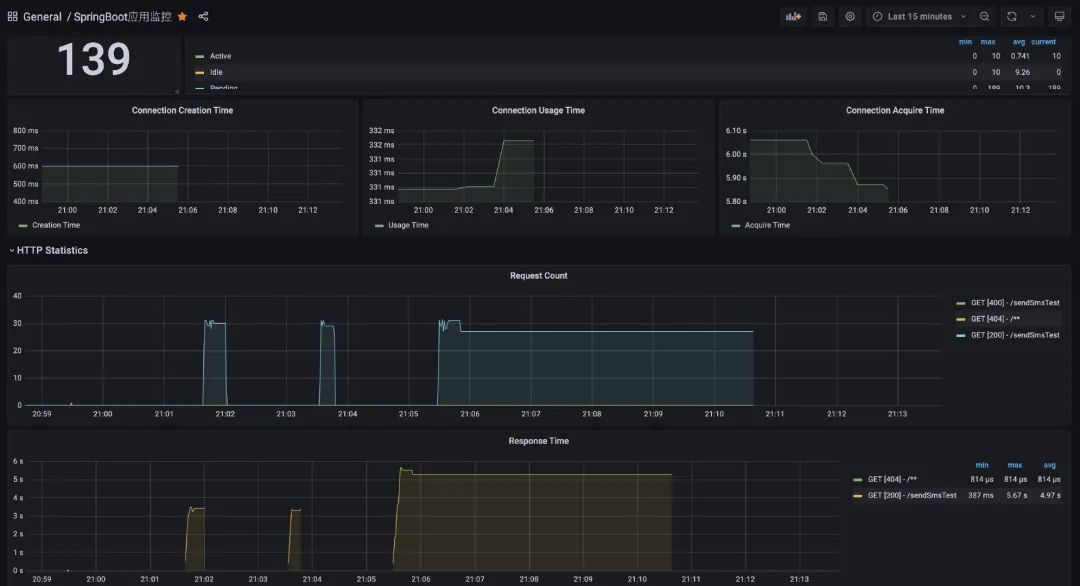
显然数据是有明显的波动的,而数据貌似跟我们压测的对不太上?
在我个人的理解下:prometheus是每隔N秒(可配置)去拉取暴露的数据,而在界面上配置的可视化也是按N秒(可配置)去执行一次Query。基于这种架构下,我们是很难得出某一时刻(秒)对应的数值。
所以在prometheus体系下,它只能看到一个时间段内的值,这对于QPS和RT这些指标并不太友好。
07、部署项目到Linux
从上面的命令来看,我是将austin项目放在Linux下跑了,虽然这是比较基础的事了。但为了新人,我还是贴下具体的流程吧,点个赞不过分吧?
首先,我们需要下载JDK
下载JDK:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
账号:liwei@xiaostudy.com
密码:OracleTest1234
完了之后,我们需要把下载的包上传到Linux上,我用的是Mac(用Windows的同学可以百度下,估计都挺简单的),IP自己切换成对应的地址
scp -P22 /Users/3y/Downloads/下载的dmg/jdk-8u311-linux-i586.tar.gz root@ip:/root/austin
解压java包
tar -zxvf jdk-8u231-linux-x64.tar.gz
配置对应的环境变量:
vim /etc/profile
# 在配置文件后添加下面的内容
export JAVA_HOME="/root/java/jdk1.8.0_311"
export PATH="$JAVA_HOME/bin:$PATH"
#刷新配置文件
source /etc/profile
# 检查版本看是否安装成功
java -version
# 如果出现以下错误,则安装下面的环境 -- 未出现则忽略
-bash: /root/java/jdk1.8.0_311/bin/java: /lib/ld-linux.so.2: bad ELF interpreter: 没有那个文件或目录
# 安装环境
yum install glibc.i686
在本地打好对应的jar包:
mvn package -Dmaven.test.skip=true
上传到Linux服务器(跟上面的操作一致),然后使用后台的方式启动:
nohup java -jar austin-web-0.0.1-SNAPSHOT.jar --server.port=8888 &
08、业务指标
从上面我配置了docker的监控、服务器的监控、SpringBoot应用程序的监控。但可以发现的是,这大多数都是系统的指标监控。有的小伙伴可能就会问了:”呀?你不是说有业务监控吗?咋不见你弄?“
我们也是可以实现自定义指标监控给到prometheus进行采集的,但如果系统本身如果接入了类ELK的系统,那我们更偏向于把业务指标数据在ELK上做掉。毕竟ELK面向的是日志数据,只要我们记录下了日志就可以把日志数据清洗出来做业务指标面板监控。
对于austin项目而言,后期是会接ELK相关的组件的。所以,这里就不用prometheus来采集业务指标的信息了,我更偏向于把prometheus作为采集系统指标的组件。

09、总结
这篇文章主要讲的是监控的基本入门(一般这块是由运维团队去做的,但作为开发最好懂点吧)。如果你公司内的系统还没监控,那可以规划规划下,用开源的组件入门下还是比较容易搭建出来的。
一个系统真不能少了监控,有监控排查的问题会快很多。
最后还是来回答下之前面试被问到的问题吧:“线上出了问题,你们是怎么排查的?排查的思路是怎么样的?”
我是这样理解的:首先,如果线上出了问题。那要想想最近有没有曾经发布过系统,很多时候线上出现的问题都是由系统的发布更改所导致的。如果最近发布过系统,并且对线上的问题是造成比较大的影响,那首先先回滚,而不是先排查问题。
如果最近没有发布系统,那看下系统的监控是否正常(流量监控、业务监控等等),一般情况下我们能从监控上就发现问题了(毕竟系统我们是最了解的,有异常很快就能定位出问题了)
如果系统监控也没问题,那得看下线上有没有比较特殊的错误日志了,通过错误日志去排查问题。一般对系统比较了解的话,那还是容易能看出来的,再不行就拿着请求参数去dev环境上debug看执行过程吧。
所以:我们这有回滚的机制、有监控机制、一般的错误我们会及时告警到短信、邮件以及IM工具上,如果这些都没有,那可能就得翻错误日志复现问题,这是我的一般排查思路。

这篇文章到这里就结束了,预告下:分布式配置中心我在代码里已经接入了
不知不觉已经写了这么长了,点个赞一点都不过分吧

《对线面试官》公众号还在持续分享面试题,没关注的同学可以关注一波!这是austin项目的上一个系列,质量杆杆的
austin项目Gitee链接:https://gitee.com/zhongfucheng/austin
austin项目GitHub链接:https://github.com/ZhongFuCheng3y/austin