
首个基于Transformer的目标检测模型上线,大目标检测超越Faster R-C...
新智元报道
编辑:元子
【新智元导读】Facebook AI Research的六名成员研究了近期非常流行的Transformer神经网络架构,创建了一个端到端的目标检测AI。研究员声称这种方法简化了目标检测模型的创建,并减少了对手工组件的需求。
Facebook AI Research的六名成员研究了近期非常流行的Transformer神经网络架构,创建了一个端到端的目标检测AI。研究员声称这种方法简化了目标检测模型的创建,并减少了对手工组件的需求。该模型被命名为 Detection Transformer(DETR),可以一次性识别图像中的全部物体。
重构目标检测任务
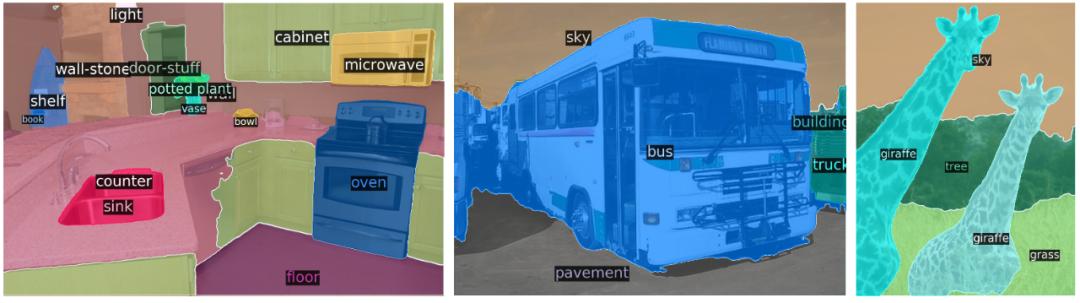
DETR将目标检测任务视为一个图像到集的问题。给定一个图像,模型必须预测出一个无序的集合(或列表),每个对象都由其类别表示,并在每个对象的周围有一个紧密的边界框。 这种表达方式特别适合于Transformer。研究人员将一个卷积神经网络(CNN)与一个Transformer编码器-解码器架构(Transformer encer-decoder)进行连锁,该架构从图像中提取局部信息,然后给出预测。传统的计算机视觉模型通常使用一个复杂的、半手动制作的流水线,依靠自定义层来对图像中的对象进行定位,然后提取特征。而DETR用更简单的神经网络取代了这一点,它提供了一个真正的端到端的深度学习解决方案。
这种表达方式特别适合于Transformer。研究人员将一个卷积神经网络(CNN)与一个Transformer编码器-解码器架构(Transformer encer-decoder)进行连锁,该架构从图像中提取局部信息,然后给出预测。传统的计算机视觉模型通常使用一个复杂的、半手动制作的流水线,依靠自定义层来对图像中的对象进行定位,然后提取特征。而DETR用更简单的神经网络取代了这一点,它提供了一个真正的端到端的深度学习解决方案。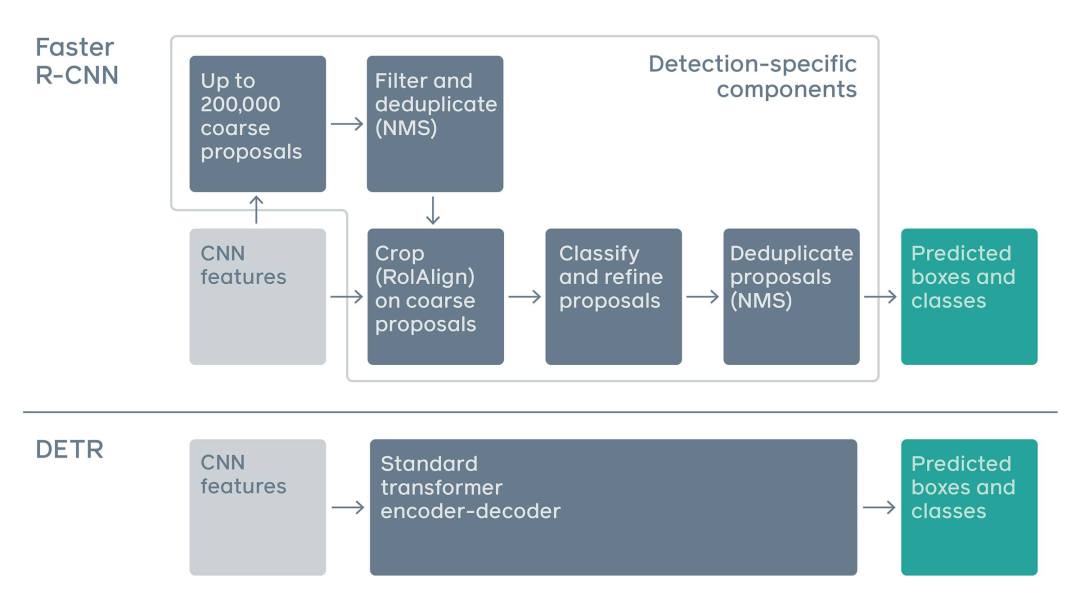 Transformer的自关注机制允许DETR对图像进行全局推理,也可以对预测的具体对象进行全局推理。例如,该模型可能会查看图像的其他区域,从而对边界框中的对象做出判断。另外,它还可以根据图像中的对象之间的关系或相关性进行预测。例如,如果DETR预测图像中包含一个站在沙滩上的人,那么它可以预测出部分遮挡的物体更有可能是冲浪板而非滑板。相比之下,其他检测模型则是孤立地预测每个物体。
Transformer的自关注机制允许DETR对图像进行全局推理,也可以对预测的具体对象进行全局推理。例如,该模型可能会查看图像的其他区域,从而对边界框中的对象做出判断。另外,它还可以根据图像中的对象之间的关系或相关性进行预测。例如,如果DETR预测图像中包含一个站在沙滩上的人,那么它可以预测出部分遮挡的物体更有可能是冲浪板而非滑板。相比之下,其他检测模型则是孤立地预测每个物体。向NLP和计算机视觉任务的统一方法推进
FAIR称,DETR是第一个成功地将Transformer架构,作为检测管道中的核心构件集成的目标检测框架。作者们还说,Transformer可以像近年来的自然语言处理一样,给计算机视觉带来革命性的变革,或者说是弥补了NLP和计算机视觉之间的差距。他们声称:「新的模型在概念上很简单,不需要专门的库,与许多其他现代检测器不同。」Transformer网络架构由谷歌的研究人员在2017年创建,最初是作为改进机器翻译的一种方式,但现在已经成长为机器学习的基石,用于制作一些最流行的预训练SOTA语言模型,如谷歌的BERT、Facebook的RoBERTa等。谷歌AI首席执行官Jeff Dean及其他AI大佬们都认为,基于Transformer的语言模型是2019年的一大趋势,而且会在2020年持续保持这个趋势。Transformer使用注意力函数代替递归神经网络来预测下一个序列中会出现什么。当应用于物体检测时,Transformer能够省去构建模型的步骤,比如需要创建空间锚和自定义层等。根据arXiv上论文结果显示,DETR所取得的结果可以与Faster R-CNN相媲美。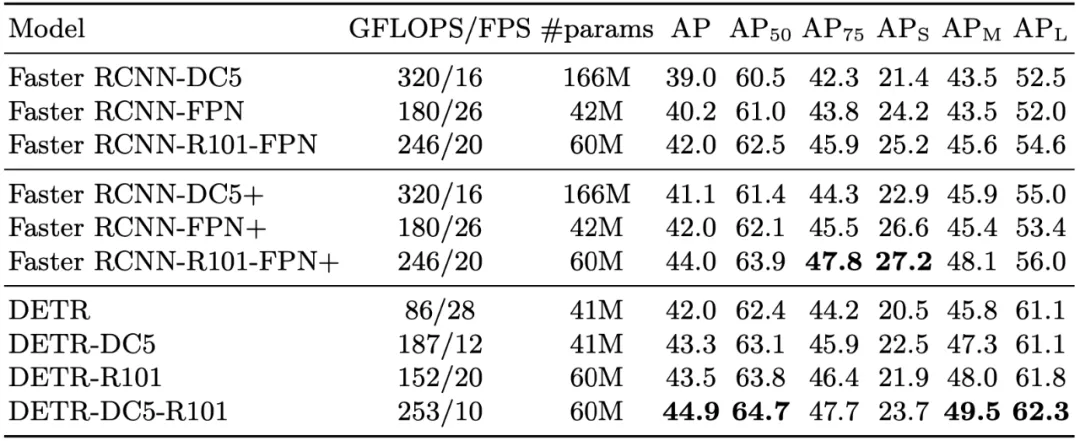 Faster R-CNN主要由微软研究公司创建的目标检测模型,自2015年推出以来,该模型已经获得了近1万次引用。DETR是Facebook最新的AI计划,它期待通过语言模型解决方案来解决计算机视觉的挑战,尤其擅长对材料分类,研究者推测,解码器注意力机制具有的全局推理特性是产生这一结果的关键因素。本月早些时候,Facebook推出了Hateful Meme数据集和挑战,倡导创建多模态人工智能,以便能够识别备忘录中的图片和附带文字何时违反Facebook政策。
Faster R-CNN主要由微软研究公司创建的目标检测模型,自2015年推出以来,该模型已经获得了近1万次引用。DETR是Facebook最新的AI计划,它期待通过语言模型解决方案来解决计算机视觉的挑战,尤其擅长对材料分类,研究者推测,解码器注意力机制具有的全局推理特性是产生这一结果的关键因素。本月早些时候,Facebook推出了Hateful Meme数据集和挑战,倡导创建多模态人工智能,以便能够识别备忘录中的图片和附带文字何时违反Facebook政策。评论