在科幻小说中,面部识别技术是威权社会的标志。关于它是如何被创造出来的,以及今天它是如何被使用的,真相都令人惊奇。Mozilla的Deborah Raji和AI Now的Genevieve Fried在arXiv上发表了一篇论文About Face: A Survey of Facial Recognition Evaluation,在这篇论文中,作者对1976-2019年间收集的100多个用于训练面部识别系统的数据集进行了调查。
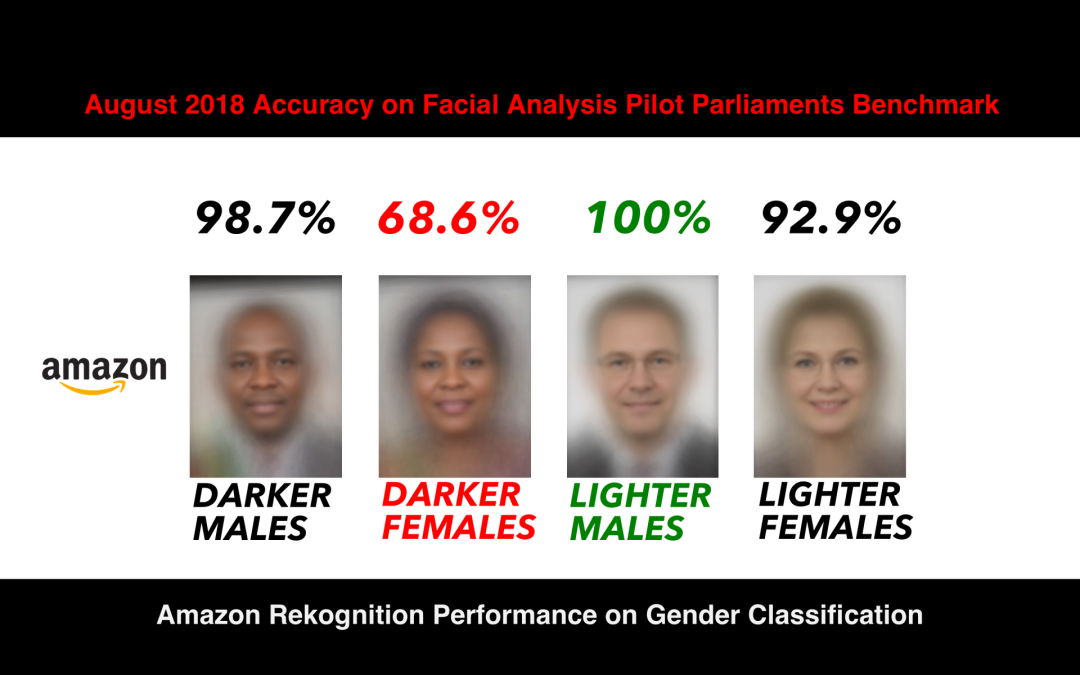
从中得出的最广泛的启示是,随着对更多数据(即照片)需求的增加,研究人员不再费心去征求用作数据的照片本人的同意。《麻省理工学院技术评论》发文This is how we lost control of our faces,称该论文是「有史以来最大的面部识别数据研究,显示了深度学习的兴起在何种程度上助长了隐私的丧失」。在这项关于面部识别数据集进化的追踪调查中,有一些历史时刻和揭示这项技术发展的事实,它们展示了面部识别的本质:当应用于现实世界时,它是一项有缺陷的技术,创建的明确目的是扩大监控状态,结果是侵犯我们的隐私。以下是43年面部识别研究得出的9个令人惊讶又可怕的结果。1 面部识别在学术环境与现实世界应用之间存在巨大的鸿沟作者进行这项研究的原因之一就是想要了解为什么在测试中准确率接近100%的面部识别系统,在现实世界中应用时却有很大的缺陷。例如,纽约市的大都会运输署在面部识别的错误率达到100%后,停止试点项目。 面部识别在识别黑人和棕色人种时的准确率较低,最近,三名黑人男子被面部识别技术错误识别并被捕。










 下载APP
下载APP