
实战案例:使用机器学习算法预测用户贷款是否违约!
大家好,最近一张"因疫情希望延缓房贷"的截图在网上流传,随即引起网友们的热议!
当借款人从贷款机构借钱而不能如期还贷款时,就可能会发生贷款违约。拖欠贷款不仅会上报征信,还可能有被起诉的风险。
为更好的管控风险,贷款机构通常会基于用户信息来预测用户贷款是否违约,今天我将使用示例数据集来给大家讲解预测贷款违约的工作原理,完整版数据和代码文末获取。
数据
数据中包含每个客户的人口统计特征和显示他们是否会拖欠贷款的目标变量。
首先,我们导入库并加载数据集。
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
sns.set_theme(style = "darkgrid")
data = pd.read_csv("/kaggle/input/loan-prediction-based-on-customer-behavior/Training Data.csv")
data.head()
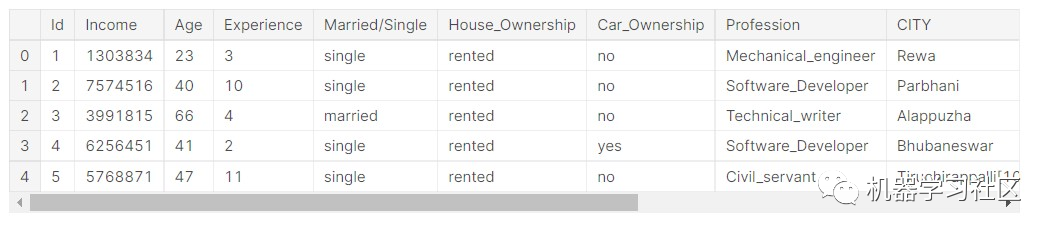
探索数据集
首先,我们从了解数据及数据分布开始
rows, columns = data.shape
print('Rows:', rows)
print('Columns:', columns)
输出
Rows: 252000
Columns: 13
我们看到数据有252000行和 13 个特征,其中 12 个是输入特征,1 个是输出特征。
现在我们检查数据类型和其他信息。
data.info()
输出
RangeIndex: 252000 entries, 0 to 251999
Data columns (total 13 columns)
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 252000 non-null int64
1 Income 252000 non-null int64
2 Age 252000 non-null int64
3 Experience 252000 non-null int64
4 Married/Single 252000 non-null object
5 House_Ownership 252000 non-null object
6 Car_Ownership 252000 non-null object
7 Profession 252000 non-null object
8 CITY 252000 non-null object
9 STATE 252000 non-null object
10 CURRENT_JOB_YRS 252000 non-null int64
11 CURRENT_HOUSE_YRS 252000 non-null int64
12 Risk_Flag 252000 non-null int64
dtypes: int64(7), object(6)
memory usage: 25.0+ MB
我们看到一半特征是数值型,一半是字符串,所以它们可能是类别特征。
在数据科学中将数值数据称为"定量数据",类别数据被称为"定性数据"
让我们检查数据中是否存在任何缺失值。
data.isnull().sum()
输出
Id 0
Income 0
Age 0
Experience 0
Married/Single 0
House_Ownership 0
Car_Ownership 0
Profession 0
CITY 0
STATE 0
CURRENT_JOB_YRS 0
CURRENT_HOUSE_YRS 0
Risk_Flag 0
dtype: int64
让我们检查数据列名称。
data.columns
输出
Index(['Id', 'Income', 'Age', 'Experience', 'Married/Single',
'House_Ownership', 'Car_Ownership', 'Profession', 'CITY', 'STATE',
'CURRENT_JOB_YRS', 'CURRENT_HOUSE_YRS', 'Risk_Flag'],
dtype='object')
我们得到了数据特征的名称。
分析数值列
首先,我们从数值数据开始分析。
data.describe()
输出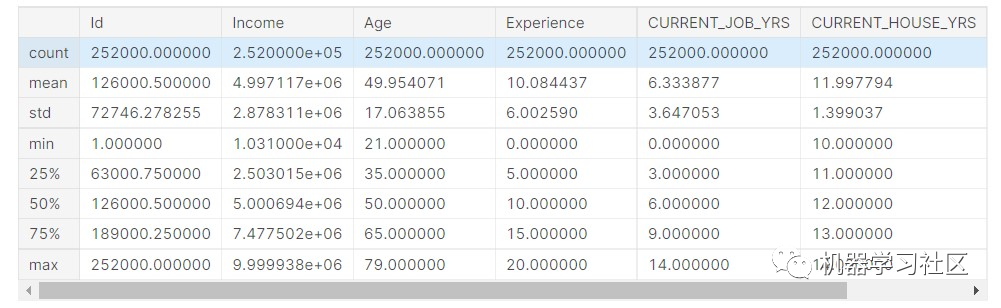
现在,我们检查数据分布。
data.hist( figsize = (22, 20) )
plt.show()
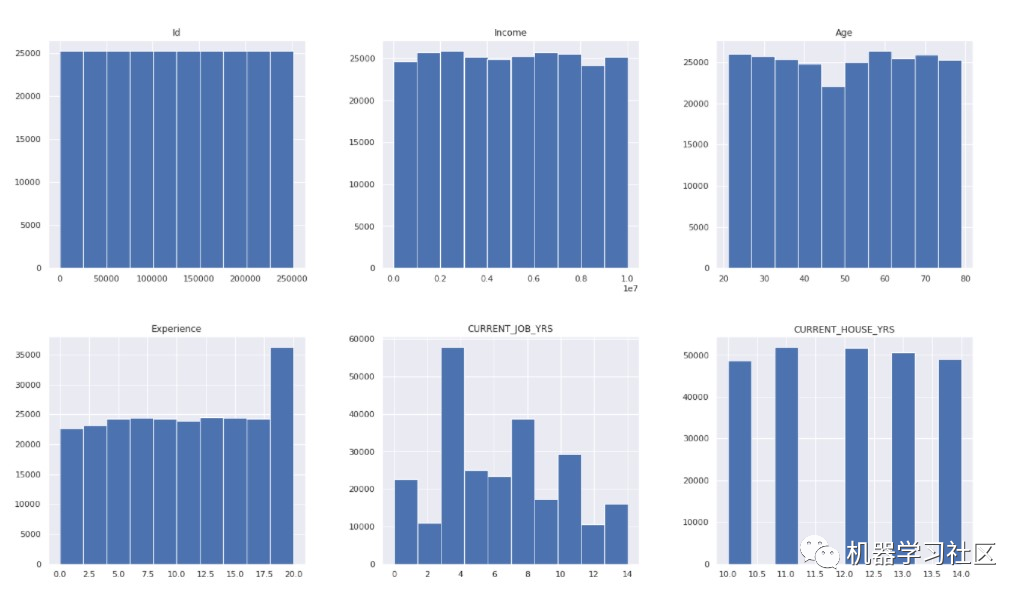
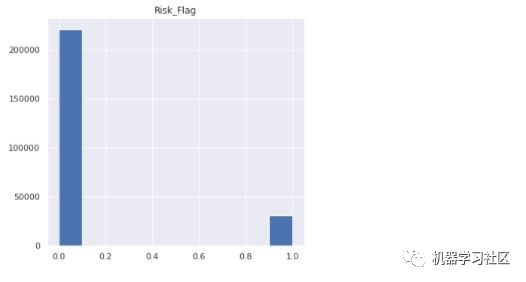 现在,我们检查目标变量的计数。
现在,我们检查目标变量的计数。
data["Risk_Flag"].value_counts()
输出
0 221004
1 30996
Name: Risk_Flag, dtype: int64
只有一小部分目标变量由拖欠贷款的人组成。
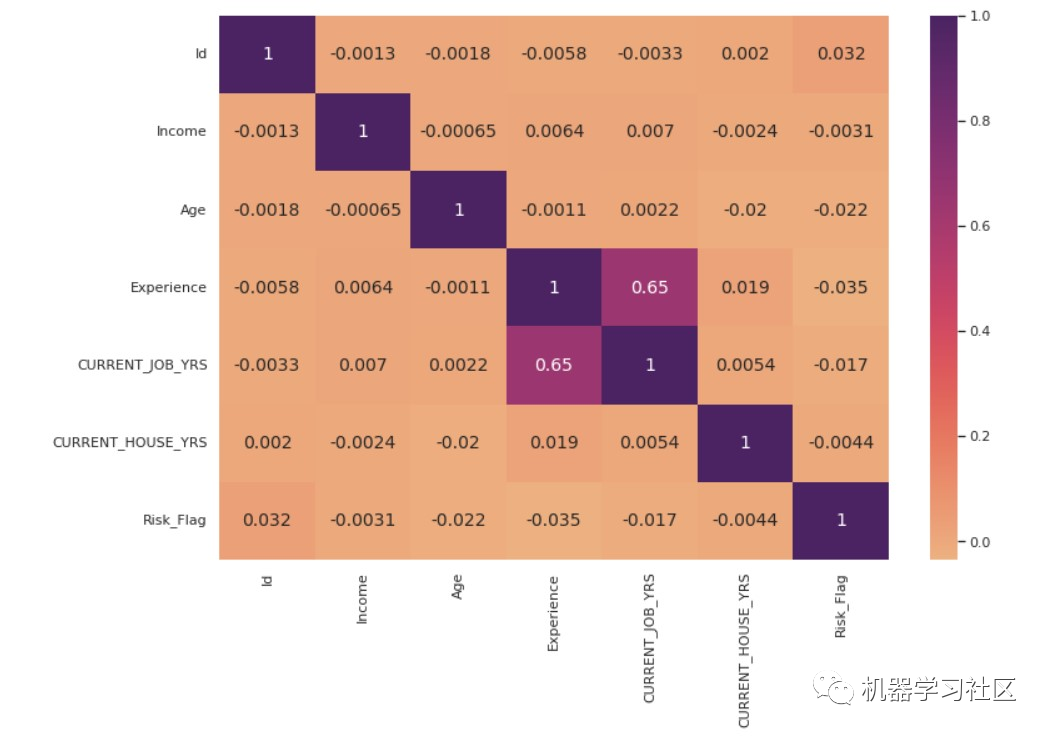
现在,我们绘制相关图。
fig, ax = plt.subplots( figsize = (12,8) )
corr_matrix = data.corr()
corr_heatmap = sns.heatmap( corr_matrix, cmap = "flare", annot=True, ax=ax, annot_kws={"size": 14})
plt.show()
分析类别特征
现在,我们继续分析类别特征。
首先,我们定义一个函数来创建绘图。
def categorical_valcount_hist(feature):
print(data[feature].value_counts())
fig, ax = plt.subplots( figsize = (6,6) )
sns.countplot(x=feature, ax=ax, data=data)
plt.show()
首先,我们检查已婚人数与单身人数。
categorical_valcount_hist("Married/Single")
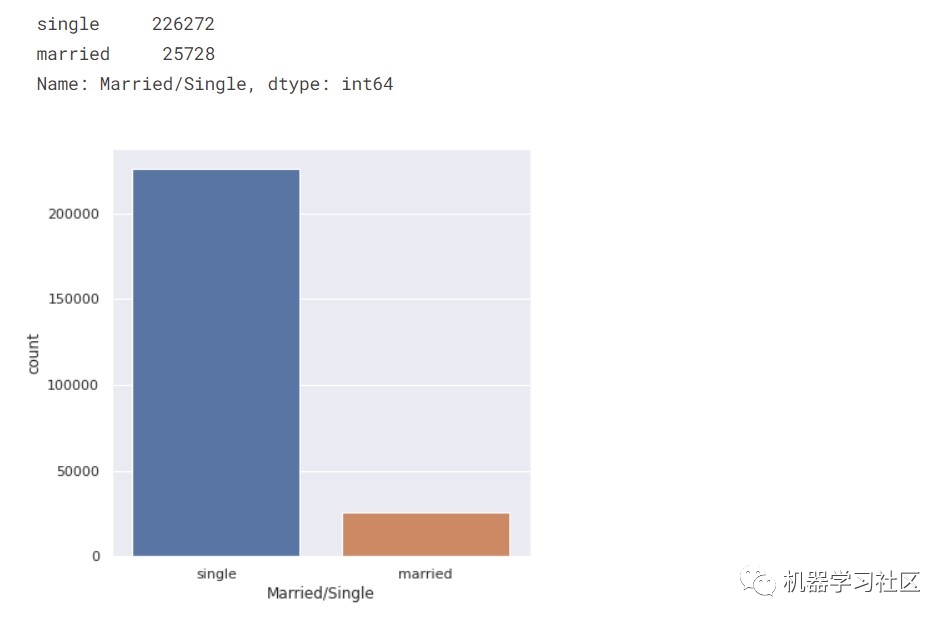
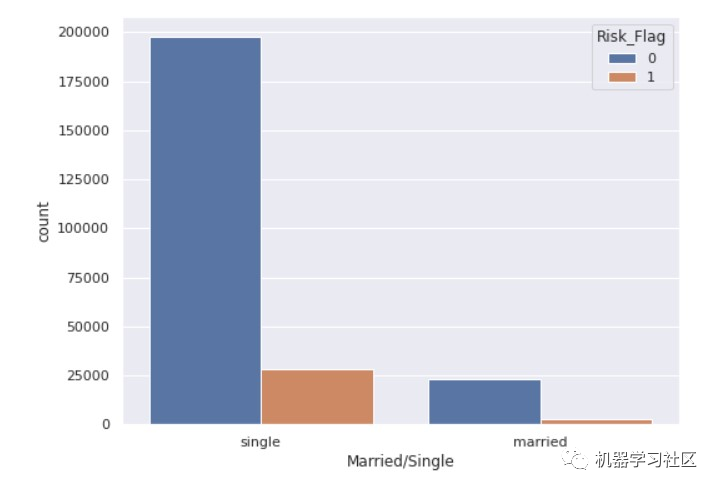
所以,大部分人都是单身。
现在,我们检查房屋所有权的数量。
categorical_valcount_hist("House_Ownership")
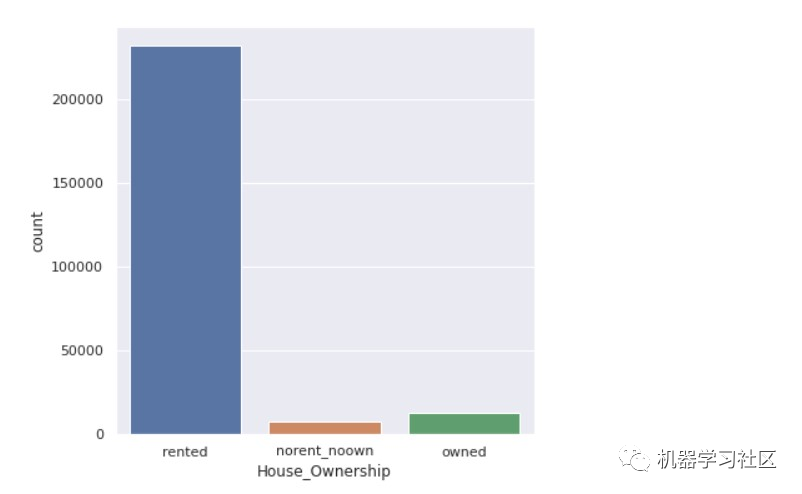
现在,让我们检查 states 数。
print( "Total categories in STATE:", len( data["STATE"].unique() ) )
print()
print( data["STATE"].value_counts() )
输出
Total categories in STATE: 29
Uttar_Pradesh 28400
Maharashtra 25562
Andhra_Pradesh 25297
West_Bengal 23483
Bihar 19780
Tamil_Nadu 16537
Madhya_Pradesh 14122
Karnataka 11855
Gujarat 11408
Rajasthan 9174
Jharkhand 8965
Haryana 7890
Telangana 7524
Assam 7062
Kerala 5805
Delhi 5490
Punjab 4720
Odisha 4658
Chhattisgarh 3834
Uttarakhand 1874
Jammu_and_Kashmir 1780
Puducherry 1433
Mizoram 849
Manipur 849
Himachal_Pradesh 833
Tripura 809
Uttar_Pradesh[5] 743
Chandigarh 656
Sikkim 608
Name: STATE
dtype: int64
现在,我们检查职业(Profession)的数量。
print( "Total categories in Profession:", len( data["Profession"].unique() ) )
print()
data["Profession"].value_counts()
输出
Total categories in Profession: 51
Physician 5957
Statistician 5806
Web_designer 5397
Psychologist 5390
Computer_hardware_engineer 5372
Drafter 5359
Magistrate 5357
Fashion_Designer 5304
Air_traffic_controller 5281
Comedian 5259
Industrial_Engineer 5250
Mechanical_engineer 5217
Chemical_engineer 5205
Technical_writer 5195
Hotel_Manager 5178
Financial_Analyst 5167
Graphic_Designer 5166
Flight_attendant 5128
Biomedical_Engineer 5127
Secretary 5061
Software_Developer 5053
Petroleum_Engineer 5041
Police_officer 5035
Computer_operator 4990
Politician 4944
Microbiologist 4881
Technician 4864
Artist 4861
Lawyer 4818
Consultant 4808
Dentist 4782
Scientist 4781
Surgeon 4772
Aviator 4758
Technology_specialist 4737
Design_Engineer 4729
Surveyor 4714
Geologist 4672
Analyst 4668
Army_officer 4661
Architect 4657
Chef 4635
Librarian 4628
Civil_engineer 4616
Designer 4598
Economist 4573
Firefighter 4507
Chartered_Accountant 4493
Civil_servant 4413
Official 4087
Engineer 4048
Name: Profession
dtype: int64
数据分析
现在,我们从了解不同数据特征之间的关系开始。
sns.boxplot(x ="Risk_Flag",y="Income" ,data = data)
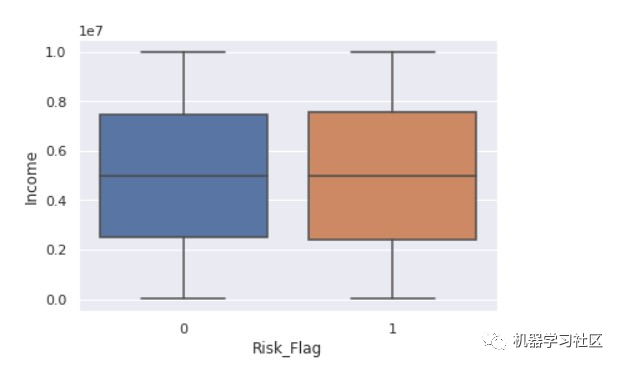 现在,我们看到了标志变量和年龄之间的关系。
现在,我们看到了标志变量和年龄之间的关系。
sns.boxplot(x ="Risk_Flag",y="Age" ,data = data)
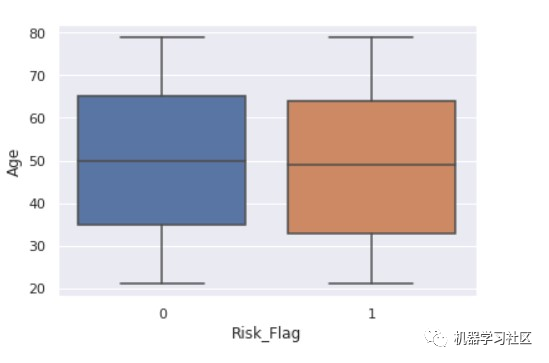
sns.boxplot(x ="Risk_Flag",y="Experience" ,data = data)
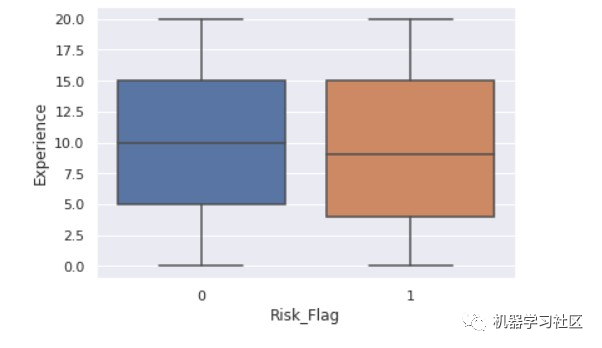
sns.boxplot(x ="Risk_Flag",y="CURRENT_JOB_YRS" ,data = data)
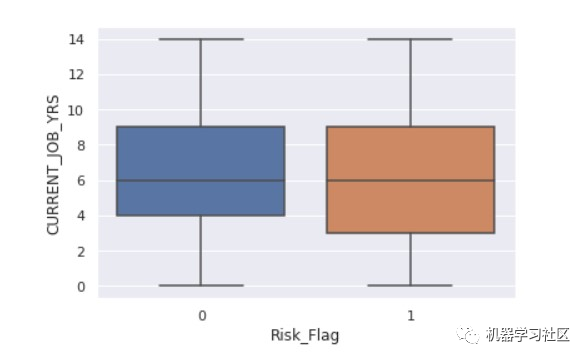
sns.boxplot(x ="Risk_Flag",y="CURRENT_HOUSE_YRS" ,data = data)
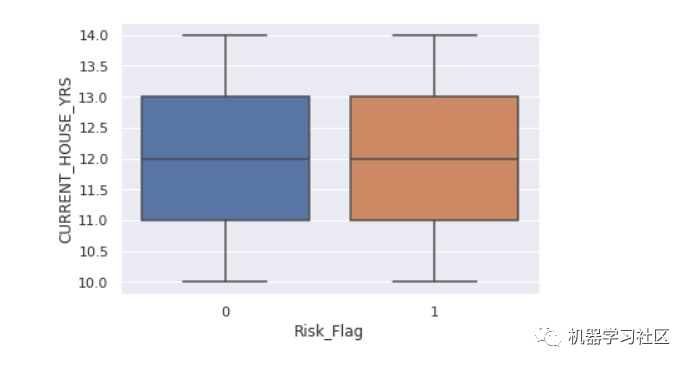
fig, ax = plt.subplots( figsize = (8,6) )
sns.countplot(x='Car_Ownership', hue='Risk_Flag', ax=ax, data=data)
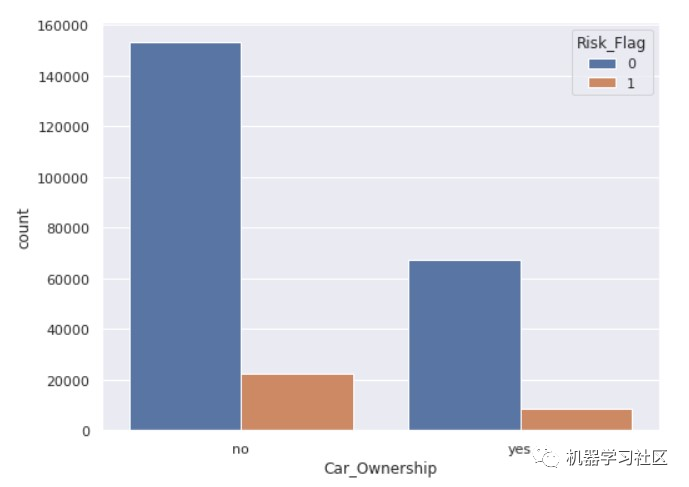
fig, ax = plt.subplots( figsize = (8,6) )
sns.countplot( x='Married/Single', hue='Risk_Flag', data=data )
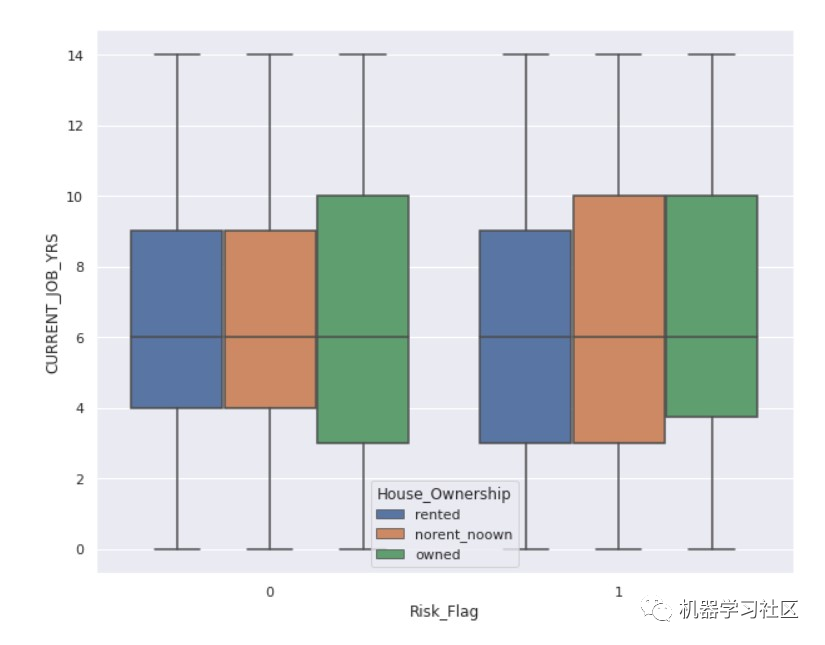
fig, ax = plt.subplots( figsize = (10,8) )
sns.boxplot(x = "Risk_Flag", y = "CURRENT_JOB_YRS", hue='House_Ownership', data = data)
特征工程
在进行建模之前,数据准备是数据科学领域的必需过程。在数据准备过程中,我们必须完成多项任务,这些关键职责之一是类别数据的编码。
众所周知,在日常工作中的大多数数据都有分类字符串值,而大多数机器学习模型只处理数值类别。
编码类别数据是将分类数据转换为整数格式的过程,以便将数据输入模型以提高预测准确性。
我们将对类别特征应用编码。
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
import category_encoders as ce
label_encoder = LabelEncoder()
for col in ['Married/Single','Car_Ownership']:
data[col] = label_encoder.fit_transform( data[col] )
onehot_encoder = OneHotEncoder(sparse = False)
data['House_Ownership'] = onehot_encoder.fit_transform(data['House_Ownership'].values.reshape(-1, 1) )
high_card_features = ['Profession', 'CITY', 'STATE']
count_encoder = ce.CountEncoder()
# Transform the features, rename the columns with the _count suffix, and join to dataframe
count_encoded = count_encoder.fit_transform( data[high_card_features] )
data = data.join(count_encoded.add_suffix("_count"))
data= data.drop(labels=['Profession', 'CITY', 'STATE'], axis=1)
data.head()
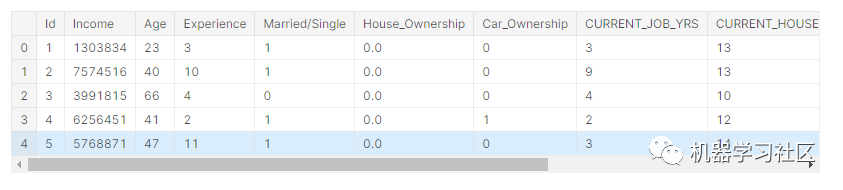 特征工程部分完成后,我们将数据拆分为训练集和测试集。
特征工程部分完成后,我们将数据拆分为训练集和测试集。
将数据拆分为训练和测试集
为了评估我们的机器学习模型的工作效率,我们必须将数据集划分为训练集和测试集。训练集用于训练机器学习模型,其统计数据是已知的,测试数据集用于预测。
x = data.drop("Risk_Flag", axis=1)
y = data["Risk_Flag"]
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, stratify = y, random_state = 7)
我们将测试集规模设为整个数据的 20%。
随机森林分类器
基于树的算法在机器学习中被广泛用于处理监督学习挑战。这些算法适应性强,几乎可以解决任何问题(分类或回归)。
此外它们具有高度准确性、稳定性和可解释性的预测。
随机森林是一种常见的基于树的有监督学习技术,该方法可用于解决分类和回归问题。随机森林通常结合数百个决策树,然后在不同的数据样本上训练每个决策树。
在本文中我采用随机森林算法,有兴趣的小伙伴可以选取其他算法进行尝试。
现在,我们训练模型并执行预测。
from sklearn.ensemble import RandomForestClassifier
from imblearn.over_sampling import SMOTE
from imblearn.pipeline import Pipeline
rf_clf = RandomForestClassifier(criterion='gini', bootstrap=True, random_state=100)
smote_sampler = SMOTE(random_state=9)
pipeline = Pipeline(steps = [['smote', smote_sampler],['classifier', rf_clf]])
pipeline.fit(x_train, y_train)
y_pred = pipeline.predict(x_test)
现在,我们检查准确性分数。
from sklearn.metrics import confusion_matrix, precision_score, recall_score, f1_score, accuracy_score, roc_auc_score
print("-------------------------TEST SCORES-----------------------")
print(f"Recall: { round(recall_score(y_test, y_pred)*100, 4) }")
print(f"Precision: { round(precision_score(y_test, y_pred)*100, 4) }")
print(f"F1-Score: { round(f1_score(y_test, y_pred)*100, 4) }")
print(f"Accuracy score: { round(accuracy_score(y_test, y_pred)*100, 4) }")
print(f"AUC Score: { round(roc_auc_score(y_test, y_pred)*100, 4) }")
输出
-------------------------TEST SCORES-----------------------
Recall: 54.1378
Precision: 54.3306
F1-Score: 54.234
Accuracy score: 88.7619
AUC Score: 73.8778
结论
今天我将预测用户贷款是否违约整个流程都讲解了一遍,有几点值得关注:
当我们需要高准确同时避免过拟合时,随机森林方法适用于具有许多条目和特征的数据集上的分类和回归任务,这些条目和特征可能具有缺失值 随机森林提供特征重要性,能够选择最重要的特征。它比神经网络模型更易解释,但比决策树更难解释 在分类特征的情况下,我们需要执行编码,以便算法可以处理它们
1. 长按下方公众号,点击右上角;
2. 在下方后台回复关键词:信贷违约,即可快速下载