常用 Normalization 方法的总结与思考:BN、LN、IN、GN

作者:G-kdom 知乎链接:https://zhuanlan.zhihu.com/p/72589565 本文仅供学习参考,如有侵权,请联系删除!
常用的Normalization方法主要有:Batch Normalization(BN,2015年)、Layer Normalization(LN,2016年)、Instance Normalization(IN,2017年)、Group Normalization(GN,2018年)。它们都是从激活函数的输入来考虑、做文章的,以不同的方式对激活函数的输入进行 Norm 的。
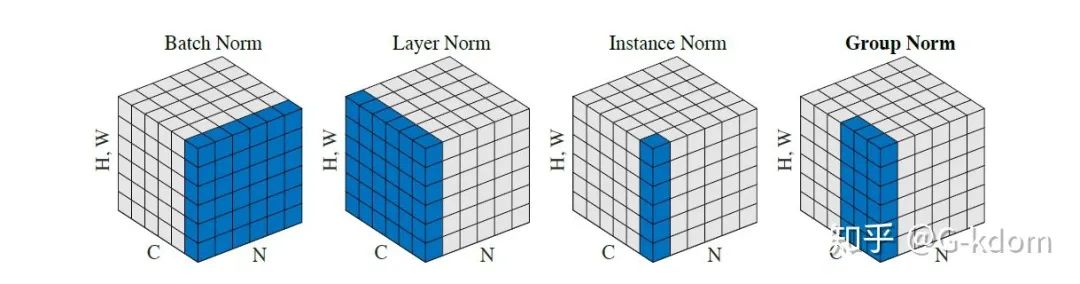
我们将输入的 feature map shape 记为[N, C, H, W],其中N表示batch size,即N个样本;C表示通道数;H、W分别表示特征图的高度、宽度。这几个方法主要的区别就是在:
1. BN是在batch上,对N、H、W做归一化,而保留通道 C 的维度。BN对较小的batch size效果不好。BN适用于固定深度的前向神经网络,如CNN,不适用于RNN;
2. LN在通道方向上,对C、H、W归一化,主要对RNN效果明显;
3. IN在图像像素上,对H、W做归一化,用在风格化迁移;
4. GN将channel分组,然后再做归一化。
如果把特征图比喻成一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 有W 个字符。
1. BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页......),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),求标准差时也是同理。
2. LN 求均值时,相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”,求标准差时也是同理。
3. IN 求均值时,相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每页书的“平均字”,求标准差时也是同理。
4. GN 相当于把一本 C 页的书平均分成 G 份,每份成为有 C/G 页的小册子,求每个小册子的“平均字”和字的“标准差”。
一、 Batch Normalization, BN
论文链接:https://arxiv.org/pdf/1502.03167.pdf
为什么要进行BN呢?
(1)在深度神经网络训练的过程中,通常以输入网络的每一个mini-batch进行训练,这样每个batch具有不同的分布,使模型训练起来特别困难。
(2)Internal Covariate Shift (ICS) 问题:在训练的过程中,激活函数会改变各层数据的分布,随着网络的加深,这种改变(差异)会越来越大,使模型训练起来特别困难,收敛速度很慢,会出现梯度消失的问题。
BN的主要思想:针对每个神经元,使数据在进入激活函数之前,沿着通道计算每个batch的均值、方差,‘强迫’数据保持均值为0,方差为1的正态分布,避免发生梯度消失。具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 ...... 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。
BN的使用位置:全连接层或卷积操作之后,激活函数之前。
BN算法过程:
沿着通道计算每个batch的均值 沿着通道计算每个batch的方差 做归一化 加入缩放和平移变量 和
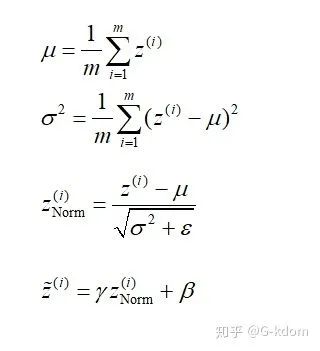
其中 是一个很小的正值,比如 。加入缩放和平移变量的原因是:保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。 这两个参数是用来学习的参数。
BN的作用:
(1)允许较大的学习率;
(2)减弱对初始化的强依赖性
(3)保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础;
(4)有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout)
BN存在的问题:
(1)每次是在一个batch上计算均值、方差,如果batch size太小,则计算的均值、方差不足以代表整个数据分布。
(2)batch size太大:会超过内存容量;需要跑更多的epoch,导致总训练时间变长;会直接固定梯度下降的方向,导致很难更新。
二、 Layer Normalization, LN
论文链接:https://arxiv.org/pdf/1607.06450v1.pdf
针对BN不适用于深度不固定的网络(sequence长度不一致,如RNN),LN对深度网络的某一层的所有神经元的输入按以下公式进行normalization操作。
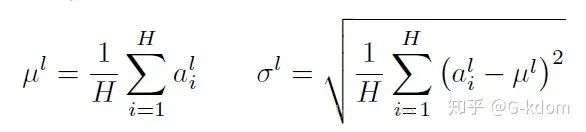
LN中同层神经元的输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差。
对于特征图 ,LN 对每个样本的 C、H、W 维度上的数据求均值和标准差,保留 N 维度。其均值和标准差公式为:
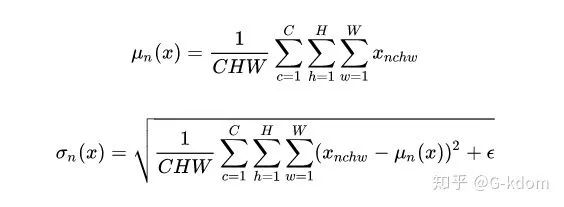
Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化。LN不依赖于batch size和输入sequence的长度,因此可以用于batch size为1和RNN中。LN用于RNN效果比较明显,但是在CNN上,效果不如BN。
三、 Instance Normalization, IN
论文链接:https://arxiv.org/pdf/1607.08022.pdf
IN针对图像像素做normalization,最初用于图像的风格化迁移。在图像风格化中,生成结果主要依赖于某个图像实例,feature map 的各个 channel 的均值和方差会影响到最终生成图像的风格。所以对整个batch归一化不适合图像风格化中,因而对H、W做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
对于,IN 对每个样本的 H、W 维度的数据求均值和标准差,保留 N 、C 维度,也就是说,它只在 channel 内部求均值和标准差,其公式如下:
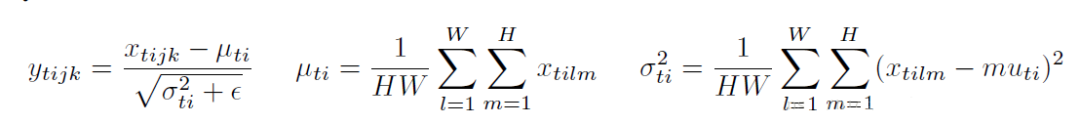
四、 Group Normalization, GN
论文链接:https://arxiv.org/pdf/1803.08494.pdf
GN是为了解决BN对较小的mini-batch size效果差的问题。GN适用于占用显存比较大的任务,例如图像分割。对这类任务,可能 batch size 只能是个位数,再大显存就不够用了。而当 batch size 是个位数时,BN 的表现很差,因为没办法通过几个样本的数据量,来近似总体的均值和标准差。GN 也是独立于 batch 的,它是 LN 和 IN 的折中。
GN的主要思想:在 channel 方向 group,然后每个 group 内做 Norm,计算 的均值和方差,这样就与batch size无关,不受其约束。
具体方法:GN 计算均值和标准差时,把每一个样本 feature map 的 channel 分成 G 组,每组将有 C/G 个 channel,然后将这些 channel 中的元素求均值和标准差。各组 channel 用其对应的归一化参数独立地归一化。
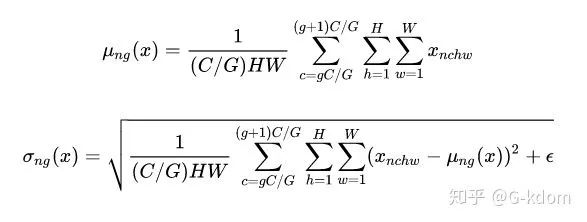
伪代码如下:

代码如下:
def GroupNorm(x, gamma, beta, G=16):
# x_shape:[N, C, H, W]
results = 0.
eps = 1e-5
x = np.reshape(x, (x.shape[0], G, x.shape[1]/16, x.shape[2], x.shape[3]))
x_mean = np.mean(x, axis=(2, 3, 4), keepdims=True)
x_var = np.var(x, axis=(2, 3, 4), keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
return results
总结
我们将feature map shape 记为[N, C, H, W]。如果把特征图比喻成一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 有W 个字符。
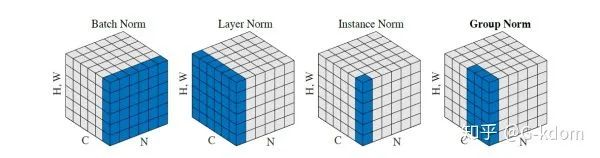
1. BN是在batch上,对N、H、W做归一化,而保留通道 C 的维度。BN 相当于把这些书按页码一一对应地加起来,再除以每个页码下的字符总数:N×H×W。
2. LN在通道方向上,对C、H、W归一化。LN 相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W。
3. IN在图像像素上,对H、W做归一化。IN 相当于把一页书中所有字加起来,再除以该页的总字数:H×W。
4. GN将channel分组,然后再做归一化。GN 相当于把一本 C 页的书平均分成 G 份,每份成为有 C/G 页的小册子,对每个小册子做Norm。
另外,还需要注意它们的映射参数和的区别:对于 BN,IN,GN, 其和都是维度等于通道数 C 的向量。而对于 LN,其和都是维度等于 normalized_shape 的矩阵。
最后,BN 和 IN 可以设置参数:momentum和track_running_stats来获得在整体数据上更准确的均值和标准差。LN 和 GN 只能计算当前 batch 内数据的真实均值和标准差。