
常用 Normalization 方法的总结与思考:BN、LN、IN、GN
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|深度学习这件小事
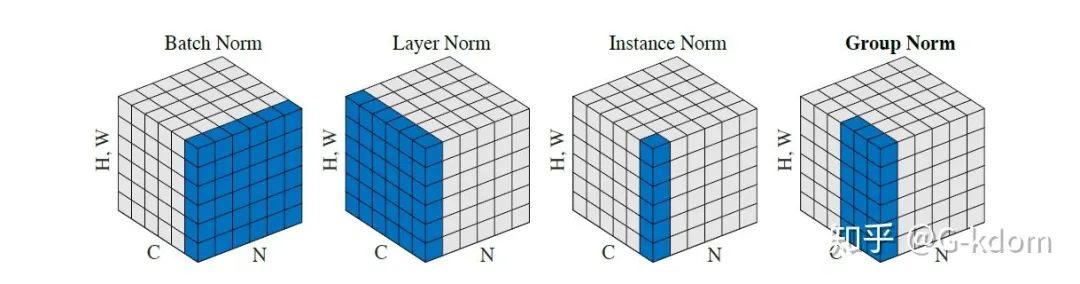
我们将输入的 feature map shape 记为[N, C, H, W],其中N表示batch size,即N个样本;C表示通道数;H、W分别表示特征图的高度、宽度。这几个方法主要的区别就是在:
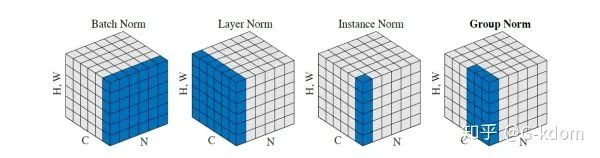
1. BN是在batch上,对N、H、W做归一化,而保留通道 C 的维度。BN对较小的batch size效果不好。BN适用于固定深度的前向神经网络,如CNN,不适用于RNN;
2. LN在通道方向上,对C、H、W归一化,主要对RNN效果明显;
3. IN在图像像素上,对H、W做归一化,用在风格化迁移;
4. GN将channel分组,然后再做归一化。
1. BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页......),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),求标准差时也是同理。
2. LN 求均值时,相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”,求标准差时也是同理。
3. IN 求均值时,相当于把一页书中所有字加起来,再除以该页的总字数:H×W,即求每页书的“平均字”,求标准差时也是同理。
4. GN 相当于把一本 C 页的书平均分成 G 份,每份成为有 C/G 页的小册子,求每个小册子的“平均字”和字的“标准差”。
一、 Batch Normalization, BN
(1)在深度神经网络训练的过程中,通常以输入网络的每一个mini-batch进行训练,这样每个batch具有不同的分布,使模型训练起来特别困难。
BN算法过程:
沿着通道计算每个batch的均值 沿着通道计算每个batch的方差 做归一化 加入缩放和平移变量 和
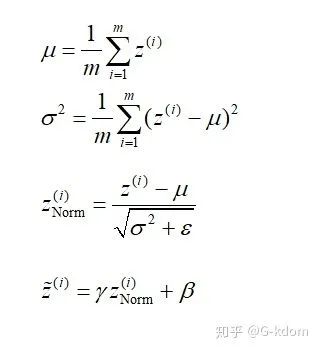
(1)允许较大的学习率;
(2)减弱对初始化的强依赖性
(3)保持隐藏层中数值的均值、方差不变,让数值更稳定,为后面网络提供坚实的基础;
(4)有轻微的正则化作用(相当于给隐藏层加入噪声,类似Dropout)
BN存在的问题:
(1)每次是在一个batch上计算均值、方差,如果batch size太小,则计算的均值、方差不足以代表整个数据分布。
(2)batch size太大:会超过内存容量;需要跑更多的epoch,导致总训练时间变长;会直接固定梯度下降的方向,导致很难更新。
二、 Layer Normalization, LN
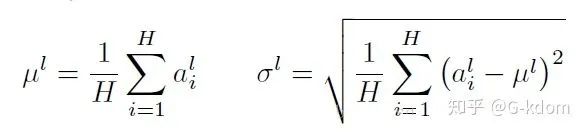
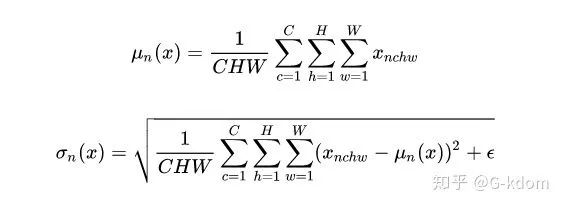
三、 Instance Normalization, IN
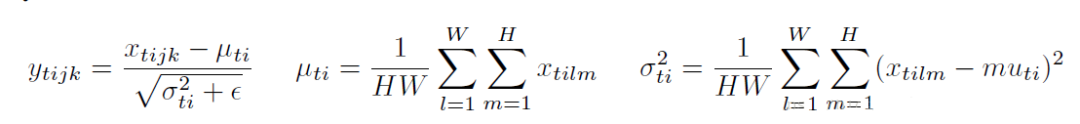
四、 Group Normalization, GN
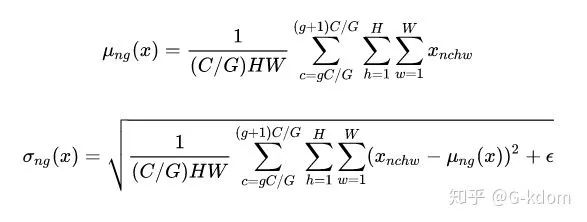

def GroupNorm(x, gamma, beta, G=16):
# x_shape:[N, C, H, W]
results = 0.
eps = 1e-5
x = np.reshape(x, (x.shape[0], G, x.shape[1]/16, x.shape[2], x.shape[3]))
x_mean = np.mean(x, axis=(2, 3, 4), keepdims=True)
x_var = np.var(x, axis=(2, 3, 4), keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
return results
总结
momentum和track_running_stats来获得在整体数据上更准确的均值和标准差。LN 和 GN 只能计算当前 batch 内数据的真实均值和标准差。—完—
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~