
清华团队将Transformer用到3D点云分割
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

当Transformer遇上3D点云,效果会怎么样?
一个是当下最热门的模型(NLP、图像领域表现都不错),另一个是自动驾驶领域、机器人抓取等领域的关键技术。
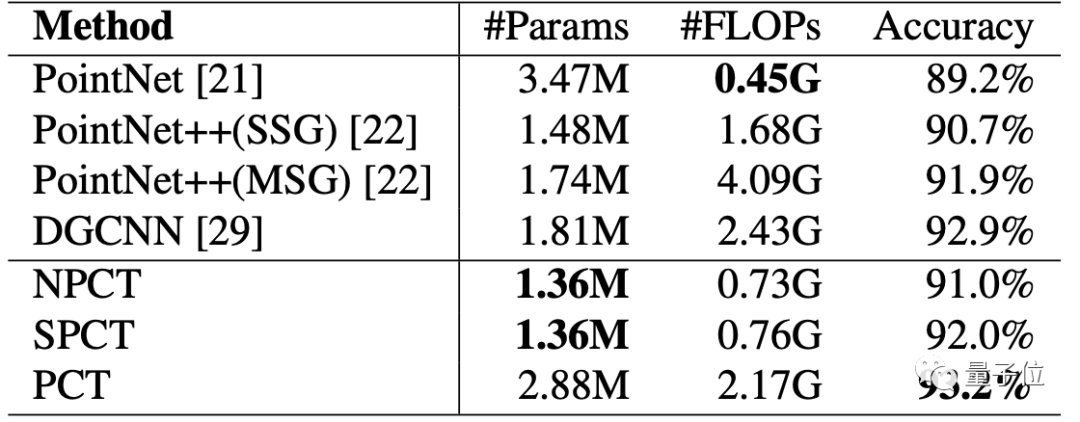
来自清华计算机系的团队,开发出了一个全新的PCT网络,相比于目前主流的点云分割模型PointNet,不仅参数量减少,准确度还从89.2%提升到了93.2%。
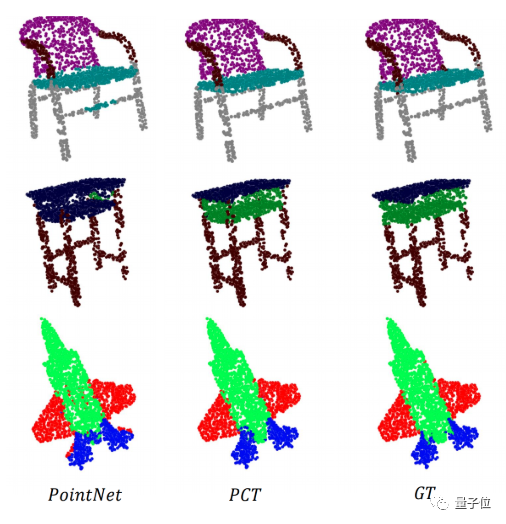
而且,相比于主流的点云分割网络PointNet,分割的边缘明显更清晰:
但将Transformer推广到3D点云,相关研究还非常少。
为此,团队自己做出了一种Transformer模型,并创新了其中的一些结构,将之适配到了点云上
点云是一个坐标系下点的数据集,包括坐标、颜色、强度等多种信息。

而3D点云,则是用点云表示三维世界的一种方法,可以想象成将三维物体进行原子化,用多个点来表示一种物体。
之所以3D建模采用点云这种方法,是因为它不仅建模速度快,而且精度高、细节更准确。
点云的生成方法,也符合激光雷达收集数据的特性,目前已经被用于自动驾驶技术中。

那么,为什么要用Transformer生成点云呢?
由于点云数据自身的不规则性和无序性,此前无法直接用卷积神经网络对点云进行处理。
如果想用深度学习处理点云相关的任务,就会非常不方便。
但当研究者们将目光放到Transformer上时,发现它的核心注意力机制,本身其实非常适合处理点云。
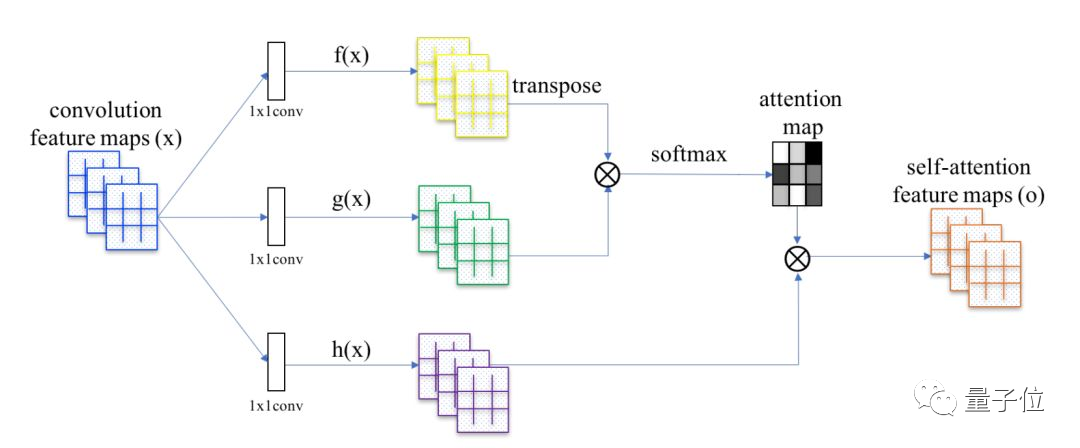
点云处理,需要设计一种排列不变、且不依赖于点之间连接关系的算子;注意力机制本身,就是这种算子。
加之Transformer在之前的图像任务上,都已经取得了非常不错的性能,用来做点云的话,说不定效果也不错。
因此,团队开发了一个名叫PCT(Point Cloud Transformer)的点云Transformer,成功实践了这一点。
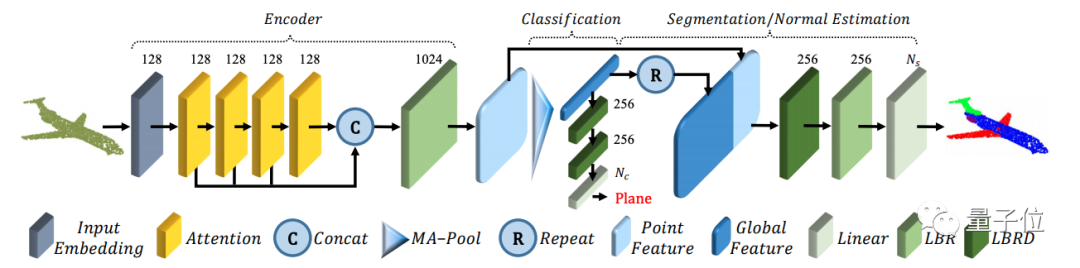
网络结构整体分为三部分:输入嵌入、注意力层和分类分割。
输入嵌入部分的目的,是将点云从欧式空间xyz映射到128维空间。这里分为两种嵌入的方式,点嵌入和邻域嵌入,点嵌入负责单点信息,邻域嵌入则负责单点和邻域信息。
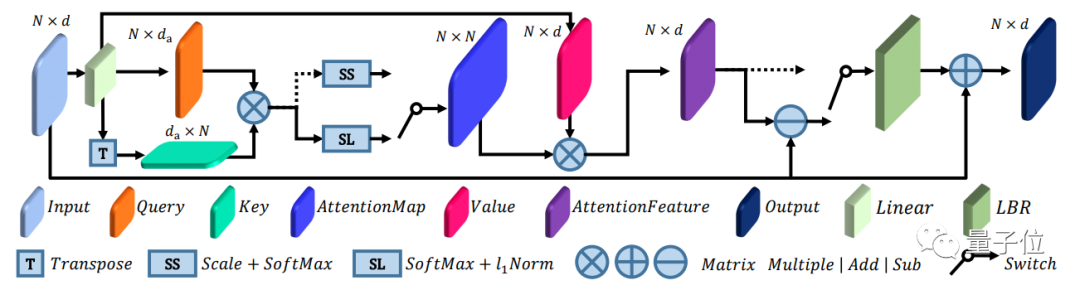
在注意力层中,作者采用了自注意力(self-attention)机制和偏置注意力(offset-attention)机制。
其中,offset-attention也是这篇论文的创新之处,作者为了让Transformer的注意力机制能更好地作用于点云,提出了这种注意力机制,性能要比自注意力机制更好。
而在分类分割操作上,作者选择对经过注意力层后的特征直接进行池化(采样),再分别进行分类和分割的下一步操作。
那么,这样的网络结构,是否效果真如想象中那么好?
事实上,从分类和分割的效果上来看,图像做得都还不错。
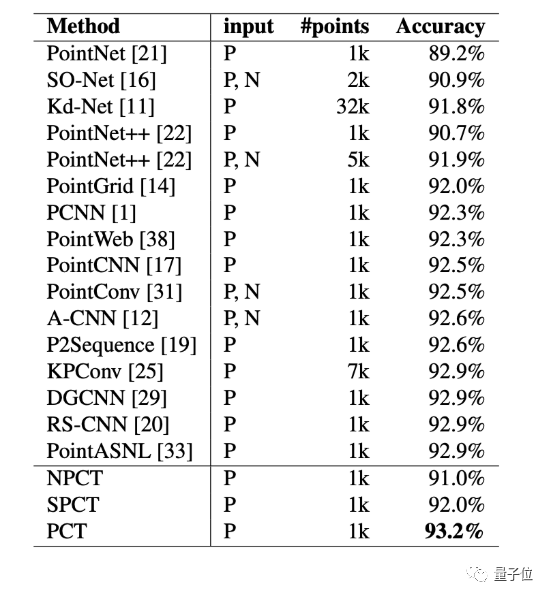
先看分类的效果,在ModelNet40数据集上的分类结果表明,PCT的分类精度可以达到93.2%,超越了目前所有点云的分类模型。
而在3D点云分割的效果上,模型做得也不错。
从注意力图(attention map,标量矩阵,查看层的重要性)的可视化来看,模型分割的边缘和形状也很清晰。
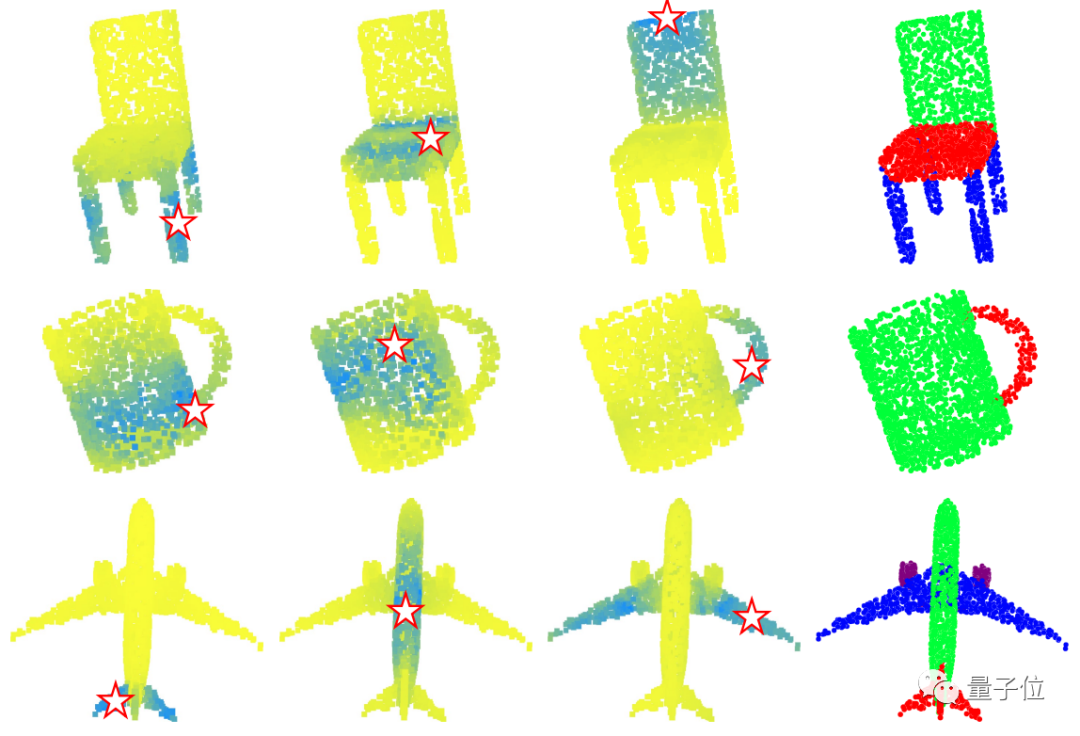
那么,与其他网络对比的分割效果如何呢?
下图是PCT与其他网络对比的效果。
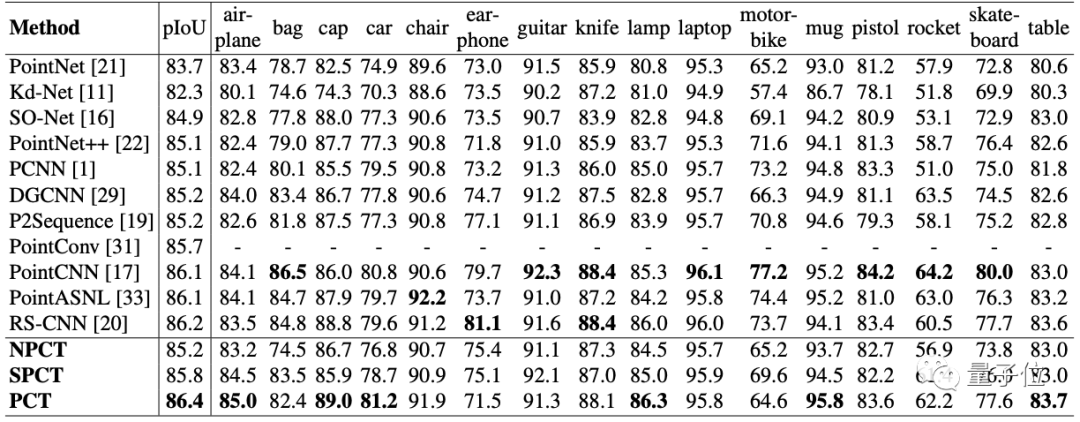
从16类列出的物体检测精确度来看,PCT的效果达到了86.4%的水平,超过了目前所有3D点云分割的最新模型,同样达到了SOTA。
至于模型参数,最终的结果也非常不错。

其中参数最大的PCT,精度也达到了最高的93.2%,如果更侧重于小型参数量,那么NPCT和SPCT则在1.36M参数的情况下,精确度分别达到了91%和92%。
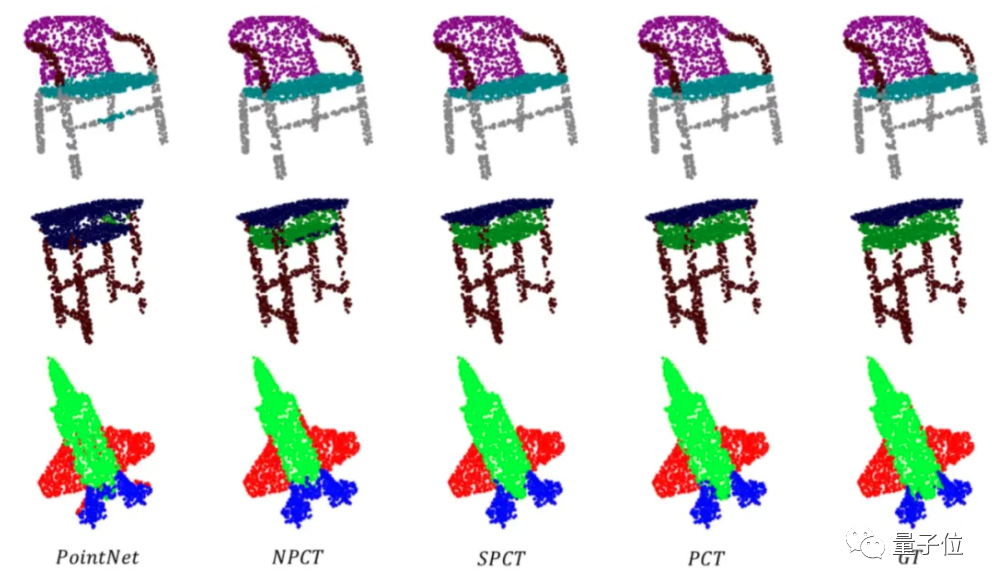
从实际对比情况来看,三种PCT网络结构的分割效果,都要比PointNet的效果好得多(最右边为初始模型)。
6名作者来自清华大学胡事民团队,卡迪夫大学。
清华大学计算机系的图形学实验室成立于1998年3月,相关论文曾多次在ACM SIGGRAPH、IEEE CVPR等重要国际刊物上发表。
实验室目前的主要研究方向为计算机图形学、计算机视觉、智能信息处理、智能机器人、系统软件等。

一作国孟昊,清华大学CS博士在读,来自胡事民团队。
国孟昊曾经是西安电子科技大学软件工程2016级本科生,大二曾获ACM金牌,数学建模美赛一等奖,在腾讯、商汤实习过。
目前,这一模型的相关代码已经开源,感兴趣的小伙伴可以戳文末地址查看~
PCT论文地址:
https://arxiv.org/abs/2012.09688
PCT项目地址:
https://github.com/MenghaoGuo/PCT
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~