
一小时开发数据分析和机器学习平台(手把手,附Python代码)
设计一个网页版的用户界面,支持交互
支持从本地选取数据集
支持自动化可视化分析
支持回归分析和分类分析,机器学习算法多样
支持查看训练记录
支持查看所有训练模型的参数,结果,甚至绘图
支持预测新数据集
支持其他机器学习任务(比如异常检测,规则关联,自然语言处理)
其他细节
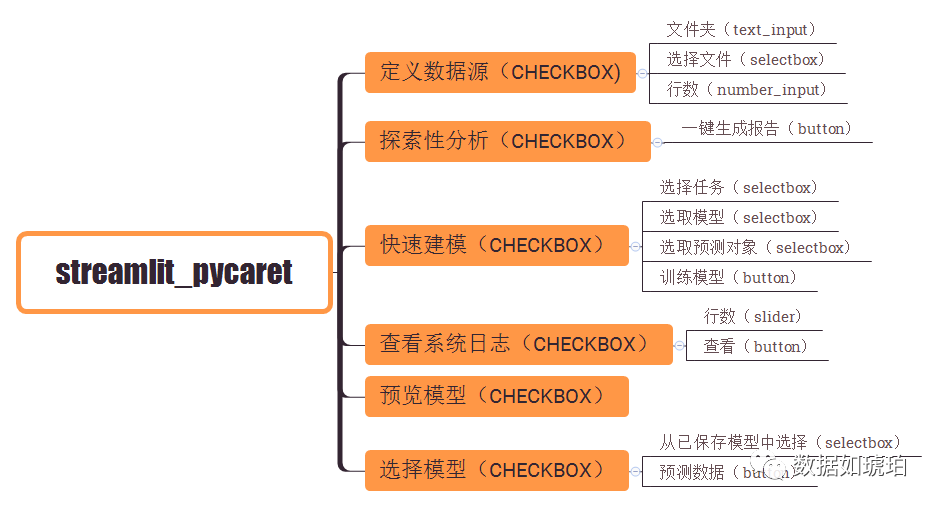
既有的组件方便快速设计网页:
该库已经内置很多组件,比如文本输入,侧边栏,按钮,滑块,图画显示等组件。
调用方式也很简单,就是单个函数即可。
部署和运行方便:只需要一个命令即可--> streamlit run main.py
pip install streamlitpip install streamlit_pandas_profilingpip install pycaret
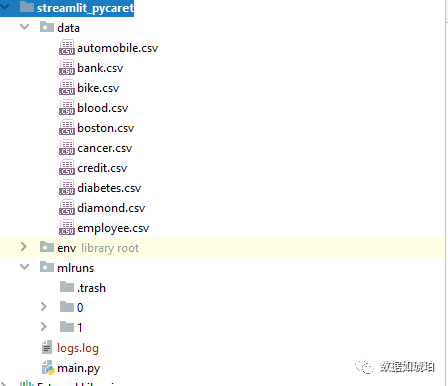
main.py 我们的代码
data 文件夹用于放置示例数据集,可不用
mlruns 文件夹 ,用于管理训练的机器学习模块记录,系统会自动生成
logs.log 用于记录系统日志
import streamlit as st # 用于设计网页import pandas as pdfrom pandas_profiling import ProfileReport # 用于生成报表from streamlit_pandas_profiling import st_profile_report # 用于在streamlit中显示报表import osimport pycaret.classification as pc_cl # 自动机器学习分类import pycaret.regression as pc_rg # 自动机器学习回归import mlflow # 模型管理
接下来我们需要准备几个辅助函数,这些函数主要是用于处理一些用户交互的细节。
逐行读取logs.log,显示最末选定行数,用户可以设定行数。
def get_model_training_logs(n_lines = 10):file = open('logs.log', 'r')lines = file.read().splitlines()file.close()return lines[-n_lines:]
获取当前路径下特定类型的文件列表,比如data文件夹的所有csv文件
def list_files(directory, extension):
# list certain extension files in the folder
return [f for f in os.listdir(directory) if f.endswith('.' + extension)]
获取文件的完整路径,用于读取数据集
def concat_file_path(file_folder, file_selected):# handle the folder path with '/' or 'without './'# and concat folder path and file pathif str(file_folder)[-1] != '/':file_selected_path = file_folder + '/' + file_selectedelse:file_selected_path = file_folder + file_selectedreturn file_selected_path
加载数据集,注意这里为了软件的性能,会将数据集放入缓存,重复加载同一数据集不会重复占用系统资源。
@st.cache(suppress_st_warning=True)def load_csv(file_selected_path, nrows):# load certain rowstry:if nrows == -1:df = pd.read_csv(file_selected_path)else:df = pd.read_csv(file_selected_path, nrows=nrows)except Exception as ex:df = pd.DataFrame([])st.exception(ex)return df
主程序包含了网页相关的界面设计以及用户操作响应,主要是选取合适的streamlit组件以及触发相应的函数。
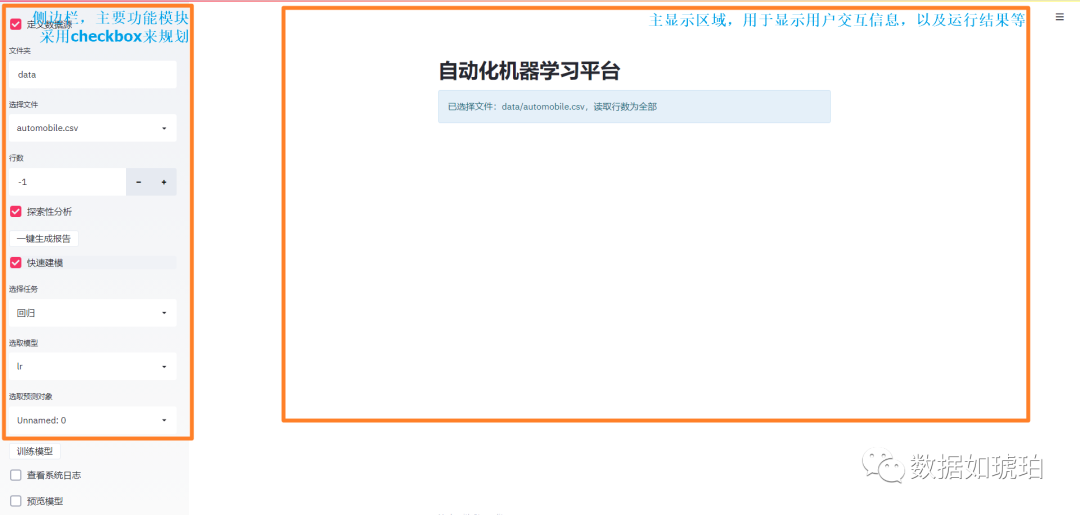
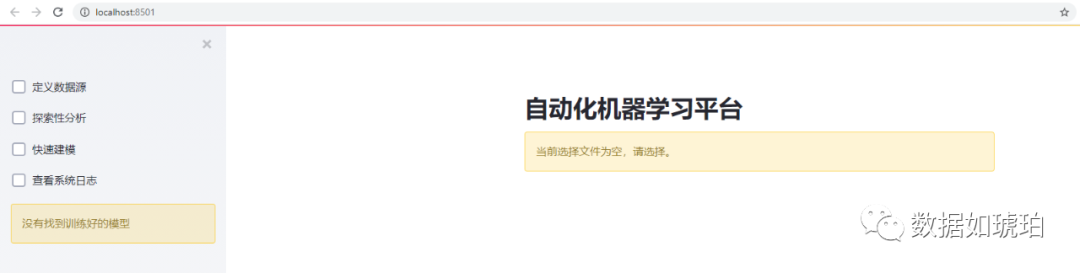
下图是网页侧边栏(功能栏)设计的组件选择,侧边栏的设计是重中之重,因为它涉及主要功能模块,需要根据用户的操作来执行相应的函数。
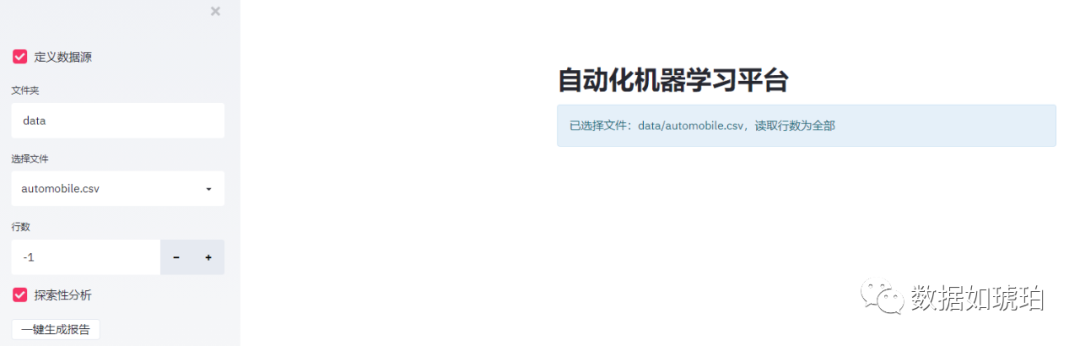
当“定义数据源”的checkbox被勾选后,相应的功能才被激活,用户才可以执行后续动作:
输入文件夹路径,这里支持相对路径,比如输入data,表示读取当前路径下的data文件夹
文件夹路径输入后(回车键),系统会自动读取所选文件夹的csv文件,并且将文件名列出到下拉列表。
在输入行数中可以选择需要读取的行数。
if st.sidebar.checkbox('定义数据源'):file_folder = st.sidebar.text_input('文件夹', value="data")data_file_list = list_files(file_folder, 'csv')if len(data_file_list) ==0:st.warning(f'当路径无可用数据集')else:file_selected = st.sidebar.selectbox('选择文件', data_file_list)file_selected_path = concat_file_path(file_folder, file_selected)nrows = st.sidebar.number_input('行数', value=-1)n_rows_str = '全部' if nrows == -1 else str(nrows)st.info(f'已选择文件:{file_selected_path},读取行数为{n_rows_str}')else:file_selected_path = Nonenrows = 100st.warning(f'当前选择文件为空,请选择。')
探索性分析相对简单,只需要一个按钮即可。之后会调用pandas-profiling 来生成EDA的分析结果。pandas-profiling 的介绍可以看之前的文章:
if st.sidebar.checkbox('探索性分析'):if file_selected_path is not None:if st.sidebar.button('一键生成报告'):df = load_csv(file_selected_path, nrows)pr = ProfileReport(df, explorative=True)st_profile_report(pr)else:st.info(f'没有选择文件,无法进行分析。')
快速建模部分核心是基于pycaret库,之前我们介绍过pycaret 库,它是很强大的自动化机器学习工具,不仅支持回归分析和分类预测,而且支持自然语言处理,规则关联,聚类,异常检测等学习任务,后面这几个模块本demo中并没有实现,但是实施起来不是很难。
代码部分相对容易,没有什么技巧可言,主要是一些细节处理,比如需要从读取的数据集Dataframe中获取所有的列名,让用户选择需要的目标列。还有,回归和分类算法支持的算法列表并不相同,需要根据所选的任务来动态获取算法列表。
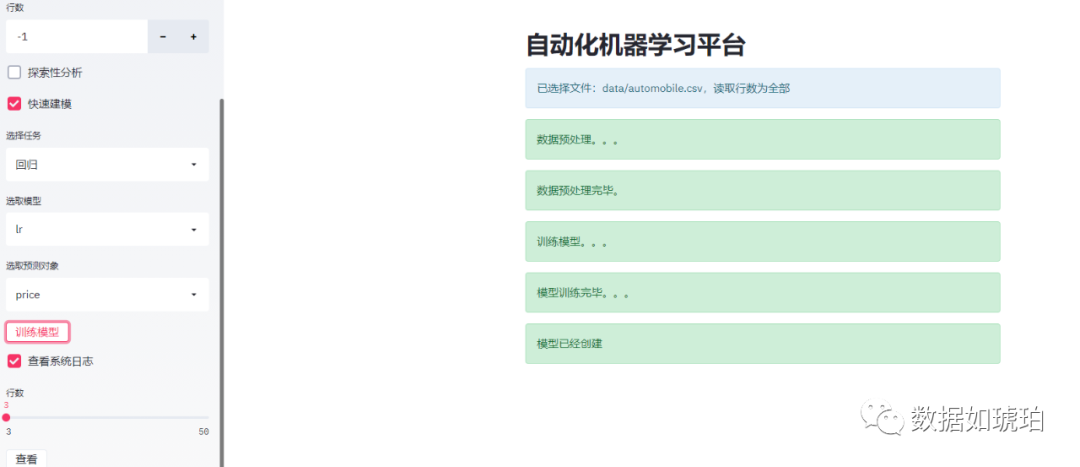
最后就是用户信息提醒,这里采用info,success,warning等组件提供给用户系统的状态信息。
我们通过配置pycaret,可以使过程日志保存在log中。
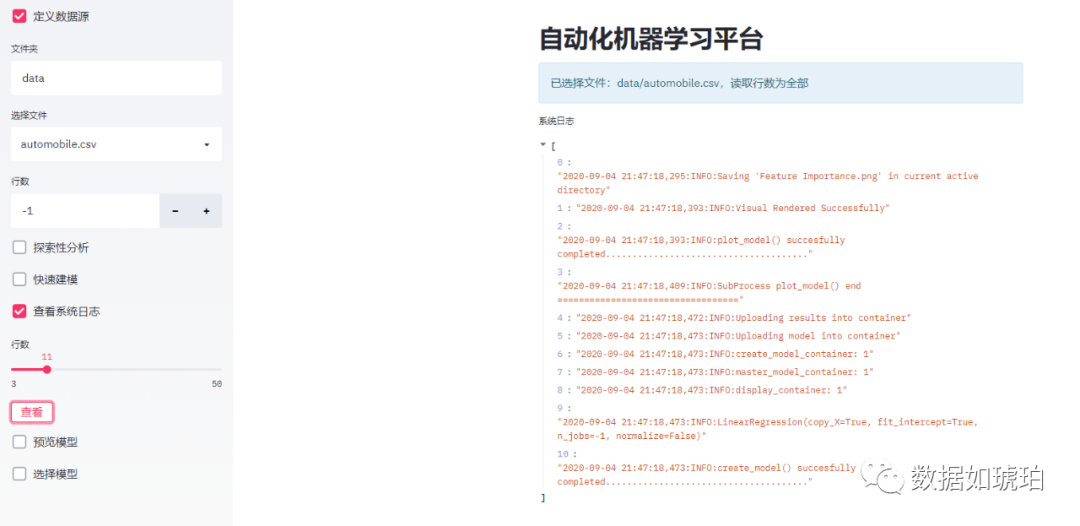
为节省文章篇幅,代码见文末源码mlflow是一款独立的,成熟的模型生命周期管理软件。其中tracking 模块可以记录每一次运行的参数,运行的结果,metrics,模型的保存,绘图的保存等(当然记录哪些内容都是需要配置的)。
pycaret中集成了mlflow 模块,所以我们只需要在调用pycaret 创建模型时,允许系统调用mlflow来管理我们的运行记录。
这里我们将mlflow的运行日志通过dataframe显示出来,当然更多的细节我们可以通过mlflow的网页来查看,比如模型信息,绘图等。
如果需要查看mlflow 服务器网页,需要在命令行中输入以下代码来启动:
mlflow ui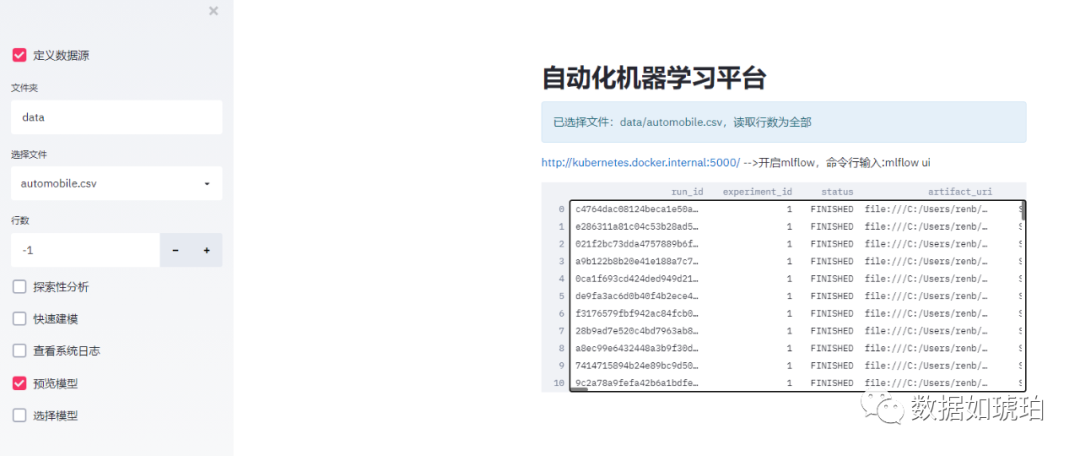
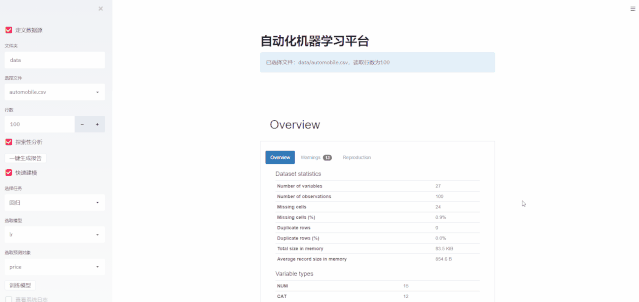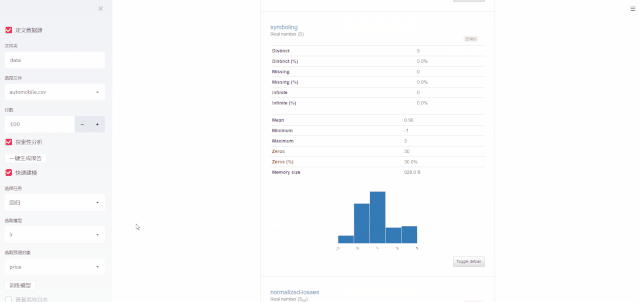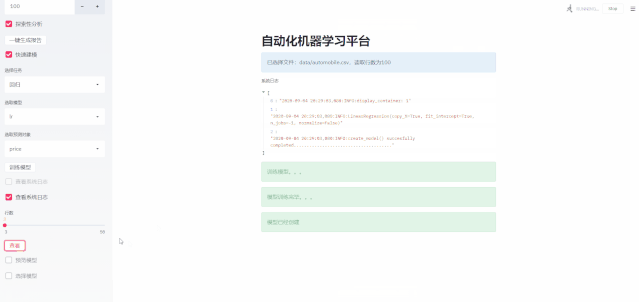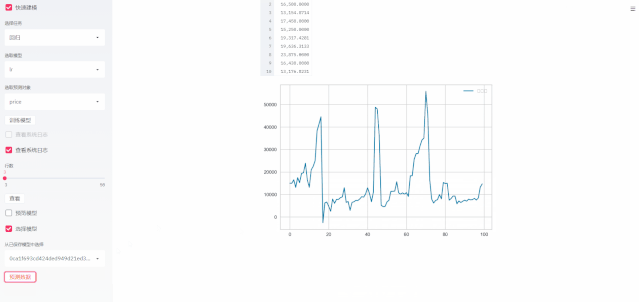
模型在mlflow中保存为pkl格式,我们需要调用mlflow中的load_model函数来获取模型的信息。pycaret的模型相比于一般的sklearn的模型,多了pipeline的(管道模型)信息,这个pipeline可以用于对数据集进行预处理。
加载的模型支持predict 方法,因此我们只需要输入数据集即可预测。这里为了节省布局控件,我们继续采用“定义数据源”的数据集来进行预测。
为节省文章篇幅,代码见文末源码我们把上面的所有涉及网页设计的代码,放置在一个函数下,比如:
def app_main():#上面的所有涉及网页的代码
然后设置程序的入口代码:
if __name__ == '__main__':app_main()
以上就是所有的代码。
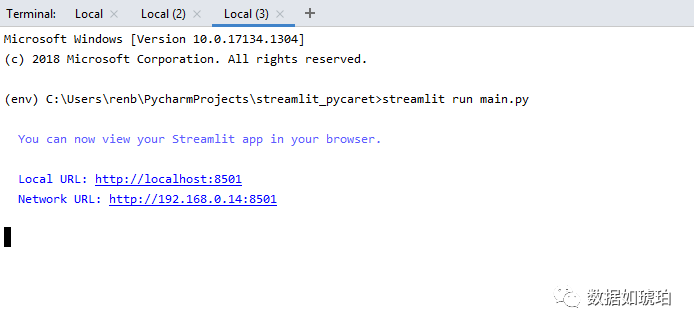
运行程序我们只需要在当前路径下,在命令行输入:
streamlit run main.py系统会在8501 端口下,运行app,在浏览器中输入网址即可运行。
本文的代码难度属于入门级别,但是达成的效果却是很实用。因为这样的数据分析平台在日常中绝对可用,而且很顺手。如果需要扩展自动机器学习的任务,比如自然语言处理,也很简单。只需要参考回归或者分类的代码即可,相信工作量不会超过10行代码(多是复制粘贴),有兴趣的朋友可以尝试。
上述的源代码都放在github上:bingblackbean/streamlit_pycaret
三连在看,月入百万👇