
手把手学机器学习算法中数据预处理(附代码)
子曰: “工欲善其事, 必先利其器。
本文主要从以下几个方面介绍数据预处理的方法:
数据准备 浏览数据 数据透析 数据抽样
数据准备
当你想了解机器学习,最好的方式就是用真实的数据入手做实验。网络上有很多优秀的开源资料。这里我们选择了加利福尼亚的房价数据集(数据的获得后面会给出),它的统计图如下所示,横纵坐标分别代表经纬度,图上有很多圈圈,而圈圈的大小代表着人口数,颜色图则表示房均价,那么一堆数据到手了,但是我们到底要做什么呢?
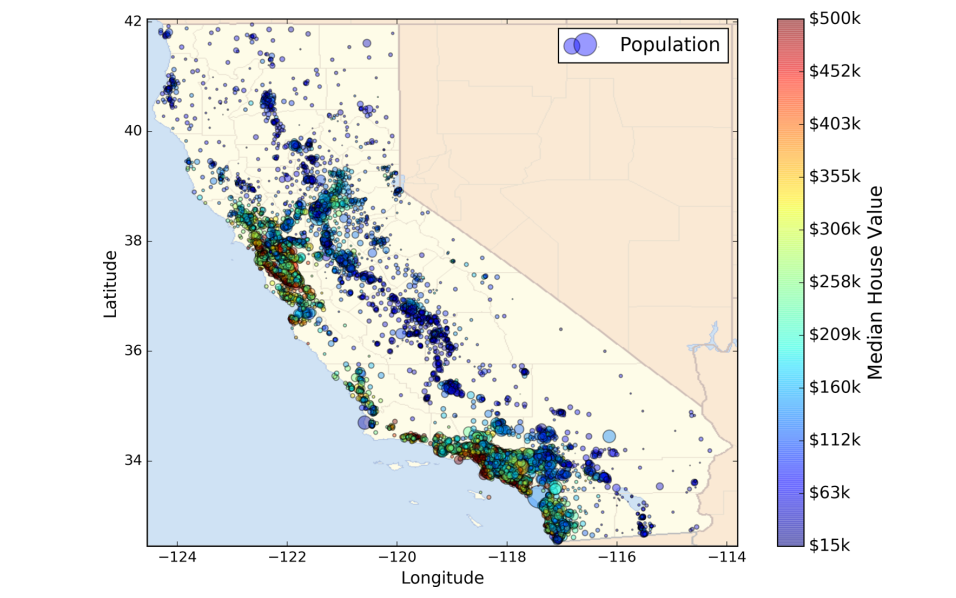
确定任务
就像炒菜一样,当你拿到你的数据后,首先需要知道你的食材都有什么,也就是了解你的数据都有哪些属性,例如像这篇文章中的数据的一些属性:population、median income、median housing price等等。那顾客是需要我们用这些材料炒个什么菜呢?这里我们是利用这些数据得到一个能够预测房价的模型。好了,大致已经知道需要做些什么了,那接下来还需要知道些什么信息呢?
既然我们知道要建立一个模型进行房价的预测,那么选择什么样的算法呢?这是一个监督学习、无监督学习还是强化学习呢?它是一个分类任务、回归任务还是其他任务?你是要用离线学习还是在线学习呢?读者读到这里的时候可以自己心理想一下答案。
这很明显是一个监督学习任务,因为给定了训练数据的标签。而且它还是一个典型的回归任务,最终需要预测一个数据值。由于它有多个特征数据,所以这还是一个多变量的回归任务。最后,因为没有需求要快速适应新数据,而且数据量小存储方面完全没问题,因此这里用离线学习即可。具体机器学习的常见方法有哪些种类,请参见文章机器学习入门。
查看数据
开始动手的阶段了。开启你的电脑跟着本文一起敲代码吧。这里假设你已经装好了Jupyter notebook了,如果读者对Jupyter notebook不了解,可以参考本公众号之前的另一篇文章Jupyter notebook使用指南。
下载数据
在本篇文章中,下载数据十分简单,你只要下载一个单一的压缩文件housing.tgz即可,它包含了housing.csv文件,里面有所有的本次实践需要的数据。
当然,你可以通过本公众号直接下载它,回复"housing"即可下载,然后解压CSV文件到你的电脑中。但是这里还是推荐使用python写一个小脚本去自动得到这些数据。这里是得到这些数据的函数:
import os
import tarfile
from six.moves import urllib
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml/master/"
HOUSING_PATH = "datasets/housing"
HOUSING_URL = DOWNLOAD_ROOT + HOUSING_PATH + "/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL, housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path):
os.makedirs(housing_path)
tgz_path = os.path.join(housing_path, "housing.tgz")
urllib.request.urlretrieve(housing_url, tgz_path)
housing_tgz = tarfile.open(tgz_path)
housing_tgz.extractall(path=housing_path)
housing_tgz.close()
当你调用fetch_housing_data()函数的时候就会创建一个datasets/housing目录在你的电脑里,下载housing.tgz文件,提取housing.csv文件。现在我们用Pandas来加载数据,同样写一个小函数用于加载数据:
import pandas as pd
def load_housing_data(housing_path=HOUSING_PATH):
csv_path = os.path.join(housing_path, "housing.csv")
return pd.read_csv(csv_path)
这个函数返回Pandas DataFrame的数据结构。
浏览数据
head方法
数据load进来了,但是里面有些什么呢?我们可以用DataFrame的head()方法来看数据集的前5个数据,如下图所示: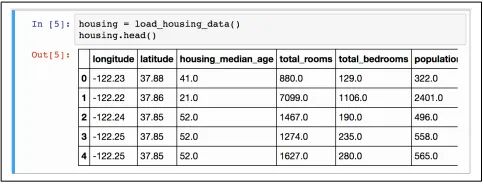
每一行表示一个地区,有
10个属性,这里包括:longitude,latitude,housing_median_age,total_rooms,total_bed_rooms,population,households,median_income,median_house_value和cean_proximity。info方法
另外DataFrame中的info()方法可用于快速浏览数据的描述,特别有用的地方就是数据的数量,每个属性的类型以及non-null值的数量,如下图所示: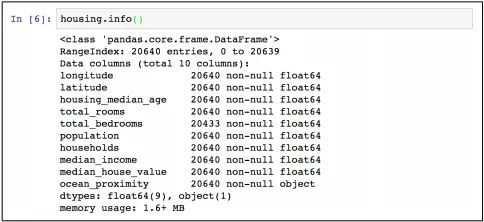
一共有
20640个数据量。从上面的数据可以看到total_bedrooms这个数据的属性只有20433个non-null值,意味着有207个地区丢失了这个属性。后面我们会特殊处理这些丢失的值。除了
ocean_proximity以外,其余都是float64的数据类型。而ocean_proximity的类型是object,这里可以调用value_counts()方法来看下其中的值:>>> housing["ocean_proximity"].value_counts()
<1H OCEAN 9136
INLAND 6551
NEAR OCEAN 2658
NEAR BAY 2290
ISLAND 5
Name: ocean_proximity, dtype: int64describe方法
除了上面这些,还能用describe()方法来了解数值型数据的一些其他特性: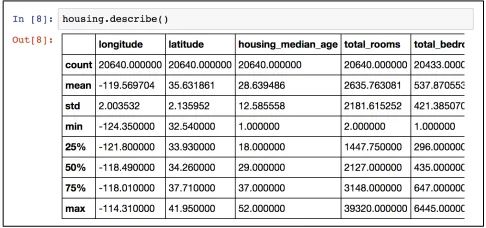
count、mean、min和max这里不用说明,读者就能从字面意思上了解。这里值得注意的是null值是会被忽略的(例如,total_bedrooms只有20433个值,其中有207个null值)。std表示的是标准差(表示数据的离散程度)。25%、50%、75%表示低于观测值以下的数据的百分比。hist方法
例外一种快速观察数据的方式就是画出它们的直方统计图。使用hist()方法一次性画出所有属性的直方图。如下图所示:%matplotlib inline # only in a Jupyter notebook
import matplotlib.pyplot as plt
housing.hist(bins=50, figsize=(20,15))
plt.show()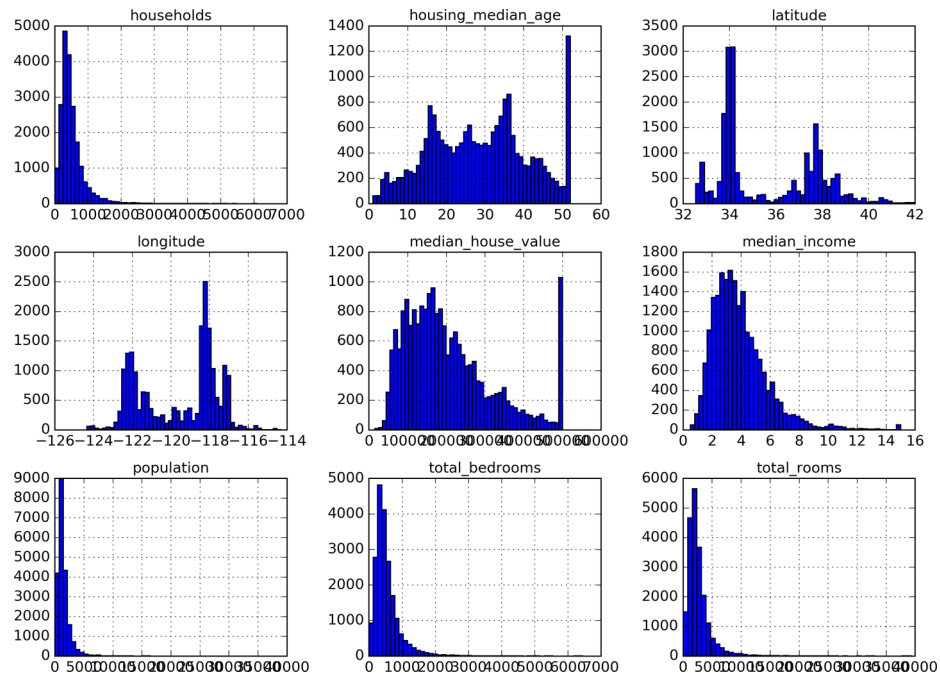
从上面的直方图上,我们可以很清楚的看到不同属性的数据分布情况。
数据透析
到目前为止只是简单的了解了一下数据。接下来更深一步的透析数据。
可视化数据
因为数据拥有地理信息(经度和纬度),那么最好的方式是将这些数据根据地理位置显示出来,如下图所示:housing.plot(kind="scatter", x="longitude", y="latitude")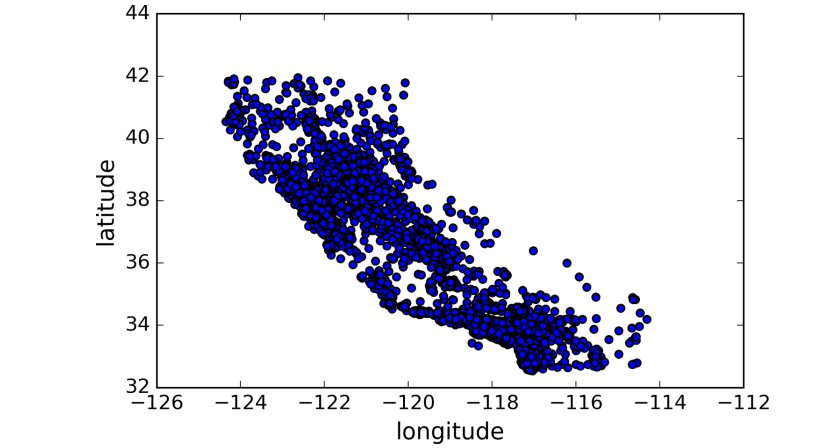
这样显示的话只能看到地理信息,显得十分单调,无法解开数据真正的面纱,那么这里可以根据数据的密度来设置透明度如下所示:
housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.1)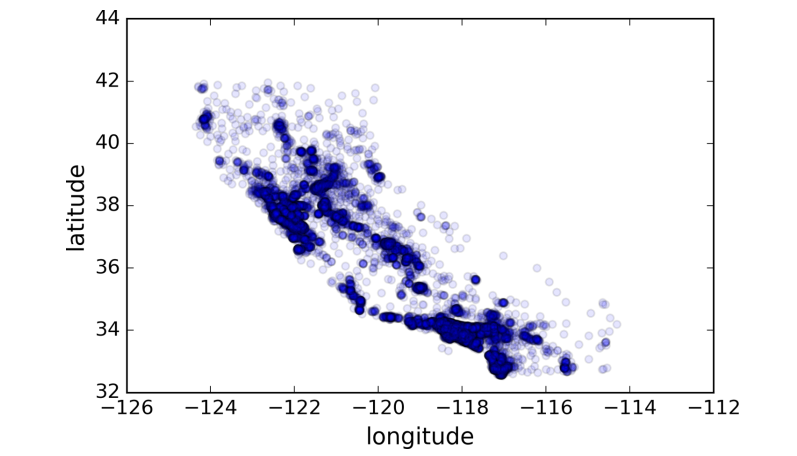
现在稍微好看一点了,你可以很明显看出哪些地区的数据密度高。现在你的脑袋中可能会想如何把其他一些参数也融入图像中,让图像更醒目更令人影响深刻呢。下面我们就用圆的半径大小表示地区人口数(下面程序中的
s),颜色来表示价格(下面程序中的c)。这里我们用了预先定义的"jet"颜色映射图(下面程序中的cmap),它的颜色范围是从蓝色(低值)到红色(高值):housing.plot(kind="scatter", x="longitude", y="latitude", alpha=0.4,
s=housing["population"]/100, label="population",
c="median_house_value", cmap=plt.get_cmap("jet"), colorbar=True,
)
plt.legend()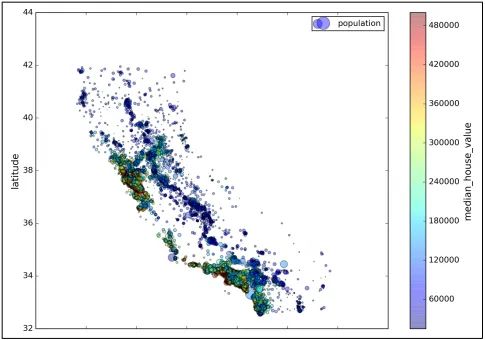
从上图可以很明显的看出房价和地区和人口密度有很强的相关性等。通过数据可视化,可以更清晰的看到数据的真正面目。
寻找相关性
因为数据量不大,所以你能很容易得出数据的标准相关系数这里使用corr()方法:corr_matrix = housing.corr()最主要的还是看
median house value与其他属性的相关性:>>> corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.687170
total_rooms 0.135231
housing_median_age 0.114220
households 0.064702
total_bedrooms 0.047865
population -0.026699
longitude -0.047279
latitude -0.142826
Name: median_house_value, dtype: float64相关系数变化范围是从
-1到1。当很接近1的时候意味着有很强的正相关性,例如,当median income增加的时候median house value也会跟着增加。相反如果值接近-1的时候,也就意味这负相关性越强。那如果系数接近0的话,说明这两个没有线性关系。另一种了解数据相关性的方式是使用
Pandas的scatter_matrix函数,它会把所有的相关性用图像的方式展现出来。因为本文数据有11种属性,那么就有11*11=121个图像,可能用一副图无法显示全部,那么这里就只画出4种属性之间的相关性图,如下所示:from pandas.tools.plotting import scatter_matrix
attributes = ["median_house_value", "median_income", "total_rooms",
"housing_median_age"]
scatter_matrix(housing[attributes], figsize=(12, 8))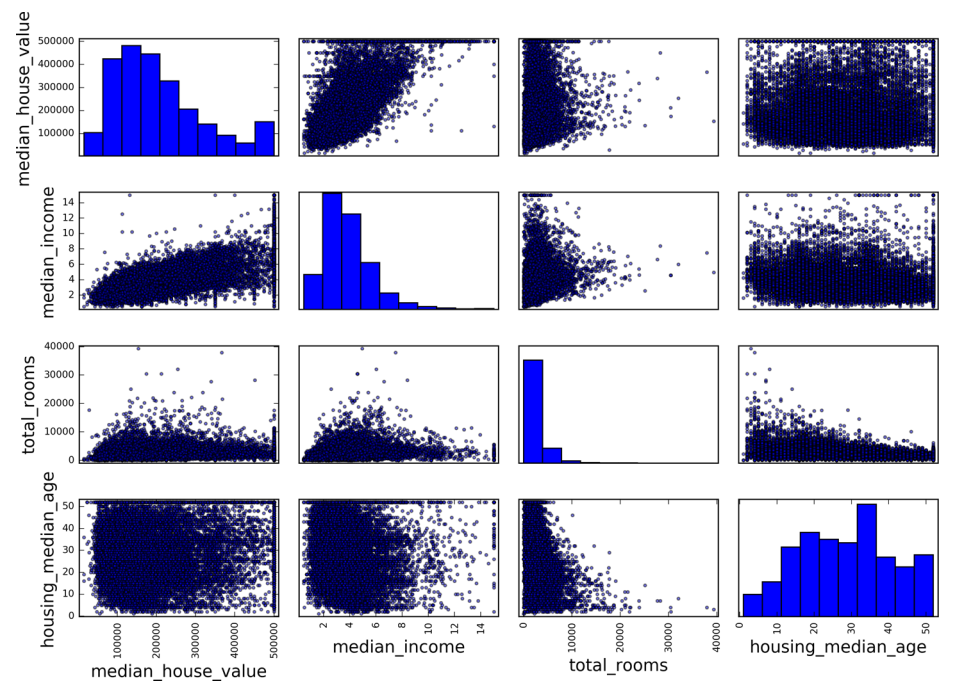
理论上来讲对角线是自己跟自己相关,相关系数应该是
1,对应图上面应该是一条斜线。这里由于从一条斜线上获得的信息量太少,所以Pandas用它的密度直方图取而代之。从上图可以看到和median house value最相关的属性就是median income了,那么我们就单独把这两个相关性的图像画出来,如下所示:housing.plot(kind="scatter", x="median_income", y="median_house_value",
alpha=0.1)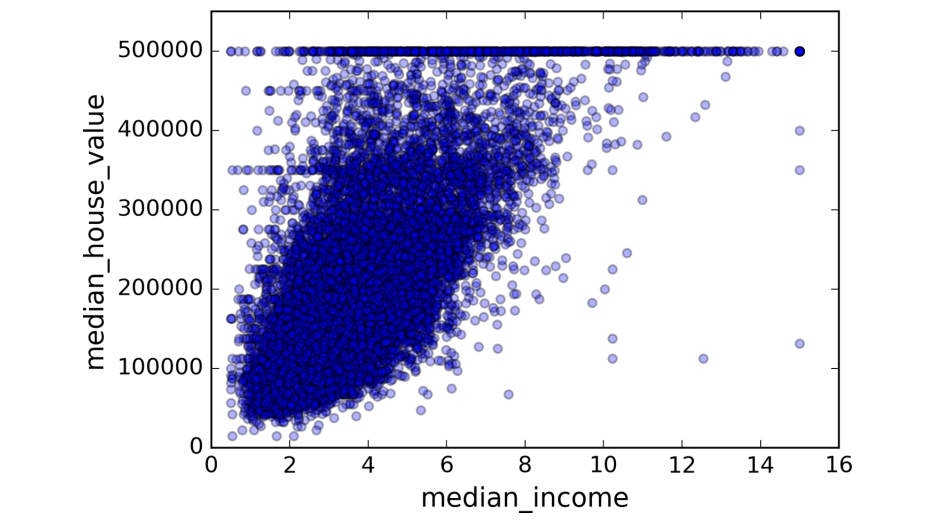
这两个属性之间的相关性还是很强烈的,可以很明显看到它们的上升趋势没有要消失的意思。但是在水平的方向上
$500000的地方有一条很明显的直线,还有$450000、$350000、$280000的水平方向上隐隐约约也有,或者说这些地方有一些数据异常值,为了保证算法的准确性,可能需要移除这些数据点。特征融合
有时候,我们可能会人为的增加一些特征来丰富我们的数据集。例如,在你不清楚households有多少时,total number of rooms这个属性并不是十分有用,类似的,total number of bedrooms也一样,那么你可能想要将这些属性和number of rooms进行比较。还有population/household这个属性看上去也不错,也想尝尝鲜。那么让我们加入一些新的属性吧:housing["rooms_per_household"] = housing["total_rooms"]/housing["households"]
housing["bedrooms_per_room"] = housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]现在让我们重新看看相关系数:
>>> corr_matrix = housing.corr()
>>> corr_matrix["median_house_value"].sort_values(ascending=False)
median_house_value 1.000000
median_income 0.687170
rooms_per_household 0.199343
total_rooms 0.135231
housing_median_age 0.114220
households 0.064702
total_bedrooms 0.047865
population_per_household -0.021984
population -0.026699
longitude -0.047279
latitude -0.142826
bedrooms_per_room -0.260070
Name: median_house_value, dtype: float64看起来还不错,至少
bedrooms_per_room属性看上去还是会比total number of rooms和bedrooms要好。还有,很明显如果bedroom/room的比例少的话,房价明显更贵。rooms per household这个属性所拥有的信息量也会比total number of rooms这个属性要多。至此,我们已基本了解了透析数据集的常见方法,那么我们解开数据集的面纱之后该做什么了呢?
数据抽样
在对数据集了解之后,我们不能够直接将全部的数据集送入机器学习算法,直接去训练,因为需要评估模型的性能,所以需要将整体的数据集进行分组,将数据集分为训练集和测试集,训练集用来训练模型,测试集用来评估模型的性能。
随机抽样
创建测试集的理论也十分简单:一般随机选取数据集的20%作为测试集,如下所示:import numpy as np
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]然后可以使用这些函数:
>>> train_set, test_set = split_train_test(housing, 0.2)
>>> print(len(train_set), "train +", len(test_set), "test")
16512 train + 4128 test上面的运行之后就可以对数据集进行一个简单的随机分组。
另外,
Scikit-Learn也提供了一些函数用于分割数据集。最简单的函数就是train_test_split,如下所示:from sklearn.model_selection import train_test_split
train_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)分层抽样
目前为止,我们已经使用了纯随机采样的方式。这种方式在数据量足够大的情况下会工作的很好,但是如果不是,你就会引入采样偏差。例如US的人口是由51.3%的男性和48.7%的女性组成,那么最好的调查方式是抽取513名男性和487名女性。这个方法叫做分层抽样。如果我们知道对于预测房价
median income是非常重要的属性。那么我们可以用分层抽样的方式进行选择训练集和测试集,median income的分布如下图所示: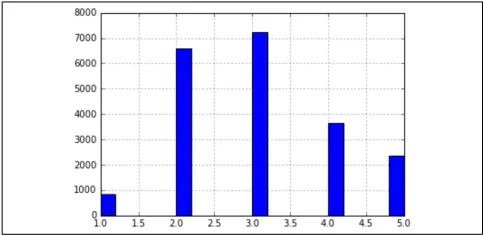
我们可以使用Scikit-Learn的StratifiedShuffleSplit类来对数据集进行分层抽样:
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]抽样分布结果如下所示:
>>> housing["income_cat"].value_counts() / len(housing)
3.0 0.350581
2.0 0.318847
4.0 0.176308
5.0 0.114438
1.0 0.039826
Name: income_cat, dtype: float64
至此,我们就将数据集通过两种方法进行了分组,两种方法各有千秋,根据具体的数据和应用场景进行不同的选择。
文章到这里,我们基本已经从数据集的下载,数据的透析以及数据的分组三大方面洞悉了数据之美,了解了机器学习算法中到底该对数据如何清洗预处理。
【都到这了,点个赞再走!】