
我看好数据湖的未来,但不看好数据湖的现在

先随便扯一扯
2020年中期的时候,数据湖这个概念应该开始频繁的进入大家的视线了。
很多兄弟都没有搞懂数据湖的概念的时候就开始吹了。
这也符合咱们中国商业和技术环境特点,先把牛逼吹出去,文章先发出来,先在大家脑海里占有一席之地,然后咱们再开始干活。
我在之前的文章中,详细提到过数据湖这个概念,说实话,小编自己也是一脸懵逼。
在此,我求求这些大佬你们别天天整这么高大上的词汇了,以后发文最好能通俗一点。
下面这段是直接找的Wikipedia和AWS的介绍。此外,阿里云也推出了自己的云产品Data Lake Formation,这个我们稍后介绍。
Wikipedia 是这么定义的:
A data lake is a system or repository of data stored in its natural/raw format,usually object blobs or files. A data lake is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning. A data lake can include structured data from relational databases (rows and columns), semi-structured data (CSV, logs, XML, JSON), unstructured data (emails, documents, PDFs) and binary data (images, audio, video). [2]A data swamp is a deteriorated and unmanaged data lake that is either inaccessible to its intended users or is providing little value
行了,我知道大家不会看,其实我也没看。翻译过来就是:
数据湖是一类存储数据自然/原始格式的系统或存储,通常是对象块或者文件。数据湖通常是企业中全量数据的单一存储。全量数据包括原始系统所产生的原始数据拷贝以及为了各类任务而产生的转换数据,各类任务包括报表、可视化、高级分析和机器学习。数据湖中包括来自于关系型数据库中的结构化数据(行和列)、半结构化数据(如CSV、日志、XML、JSON)、非结构化数据(如email、文档、PDF等)和二进制数据(如图像、音频、视频)。数据沼泽是一种退化的、缺乏管理的数据湖,数据沼泽对于用户来说要么是不可访问的要么就是无法提供足够的价值。
AWS给出的定义在这里:
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics—from dashboards and visualizations to big data processing, real-time analytics, and machine learning to guide better decisions.
翻译过来是这样的:
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
另外,标准狂魔微软也给出了自己的定义,我反正没看懂,就不说了。
我在阿里云的官网上看到的简介倒是非常的合理:
数据湖是一个集中式存储库,可存储任意规模结构化和非结构化数据,支持大数据和AI计算。数据湖构建服务(Data Lake Formation,DLF)作为云原生数据湖架构核心组成部分,帮助用户简单快速地构建云原生数据湖解决方案。数据湖构建提供湖上元数据统一管理、企业级权限控制,并无缝对接多种计算引擎,打破数据孤岛,洞察业务价值。
综上所述,大家都在突出的一个概念是:任意规模结构化和非结构化数据。
好,假设上面说的都是对的,那么数据湖给我描述的应该是一个全新的,分别超越了:
以Hadoop为核心的的离线数仓第一阶段
以Lamda为代表架构批流一体第二阶段
以Kappa为代表架构的数据一致性第三阶段
这三种我们已经使用非常成熟的三种构建数据中心或者数据仓库的形式。
都说数据湖好?好在哪里?
小编参考了AWS的官网发现,AWS对于这个问题给了用户一个清晰的答案:
数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。事先定义数据结构和 Schema 以优化快速 SQL 查询,其中结果通常用于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息源”。
数据湖有所不同,因为它存储来自业务线应用程序的关系数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系数据。捕获数据时,未定义数据结构或 Schema。这意味着您可以存储所有数据,而不需要精心设计也无需知道将来您可能需要哪些问题的答案。您可以对数据使用不同类型的分析(如 SQL 查询、大数据分析、全文搜索、实时分析和机器学习)来获得见解。
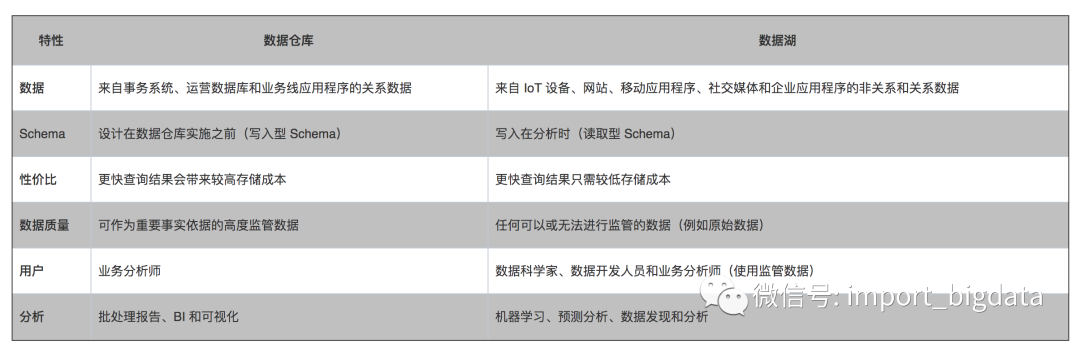
上图中,AWS特别强调了"读取型 Schema"。什么意思?
我个人的浅见:传统的数据仓库在建设之前要经过非常详细、严谨的设计,比如复杂的分层、详细的表结构甚至预留大量扩展字段应对不时之需。
【读取型 Schema】强调的是,业务在进入数仓设计前的不确定性客观存在而且大概率没有办法预测,索性我们一股脑先丢进去,在使用的时候在根据需要查询出来。
基于以上的考虑,数据湖的另外一个能力必须要足够强大,那就是:可管理性,否则你的数据湖就会退化为【数据沼泽】,处于不可用状态。
数据湖可能的架构
这方面小编没有什么经验,我们直接把阿里云的一个典型Demo图拿过来看一下:
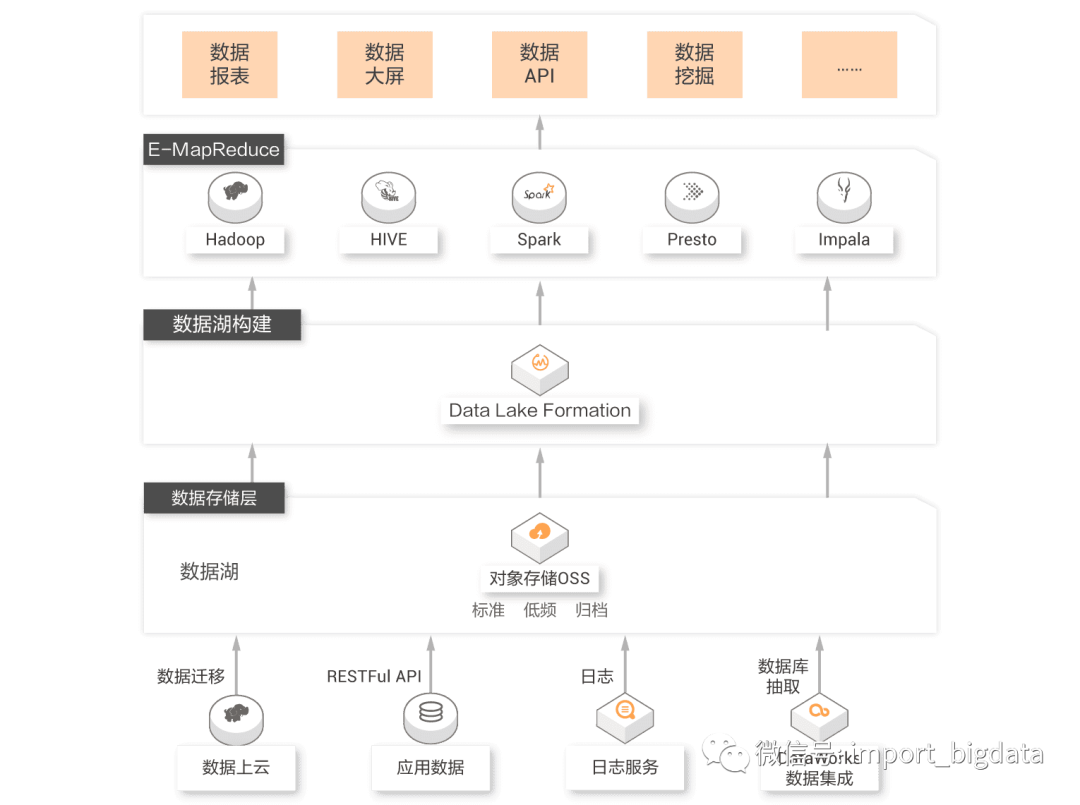
图来源于阿里云官网
这个架构里,数据湖构建完美适配数据存储OSS,同时对接大量计算引擎,满足用户不同的分析需求。小编不才,认为整个数据湖构建的关键在于选择一类可以扩展的基于对象存储的分布式文件系统作为最底层的存储系统,开源的好像除了HDFS没有别的选择。
此外,大家在各个大厂的分享中也看到了一些典型的数据湖架构:
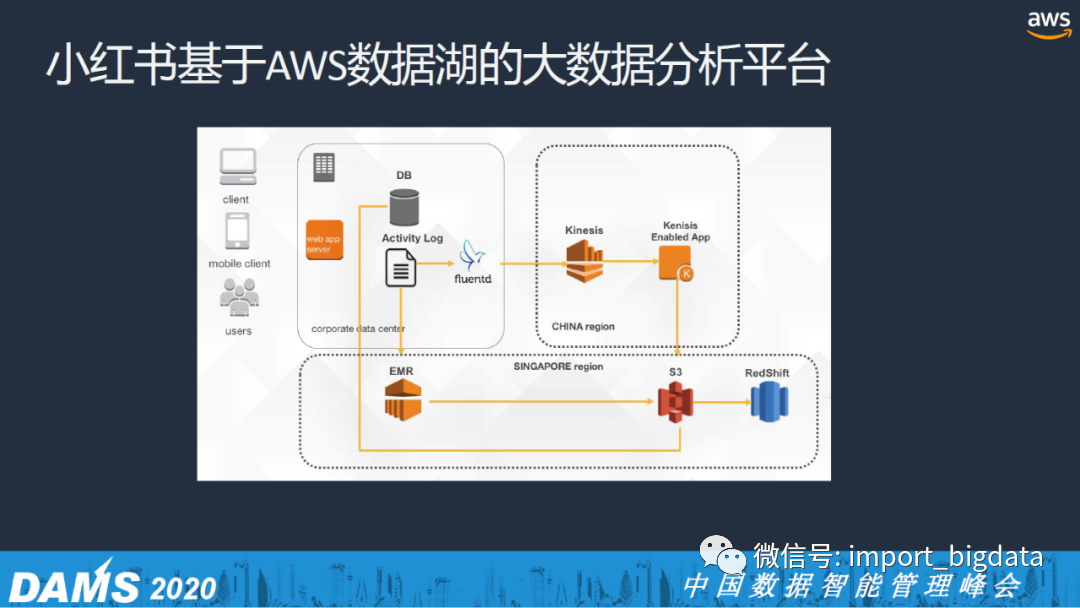 小红书
小红书
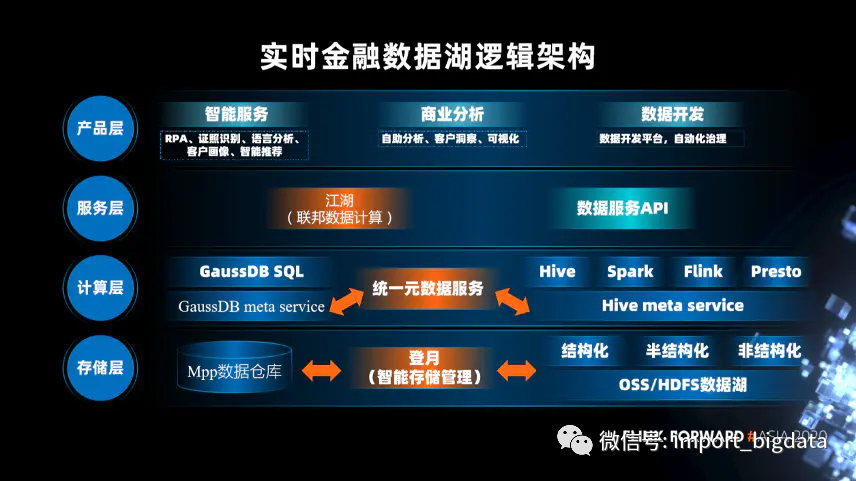 中原银行
中原银行
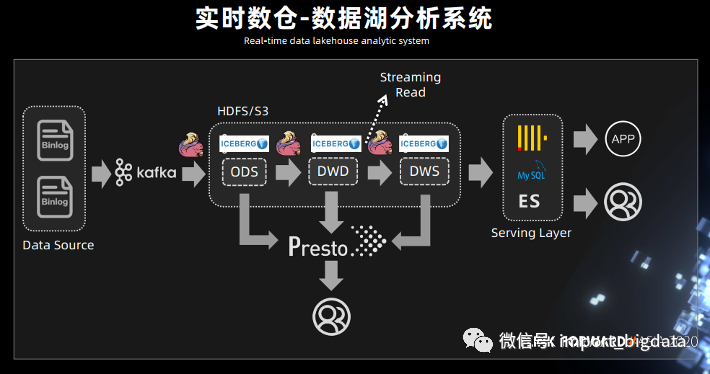 腾讯数据平台部
腾讯数据平台部
关于技术选型
我们先来看看开源的各大厂家的技术方案是怎么做的?
AWS
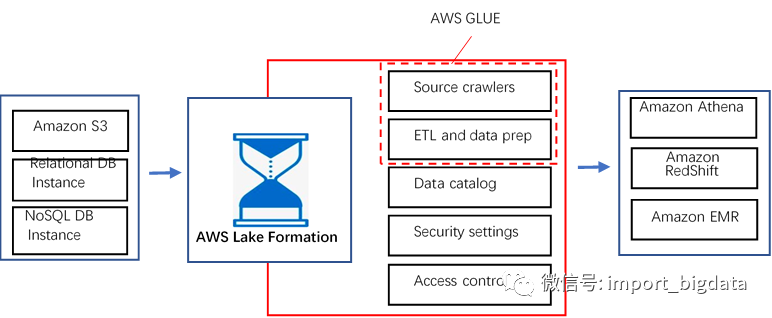
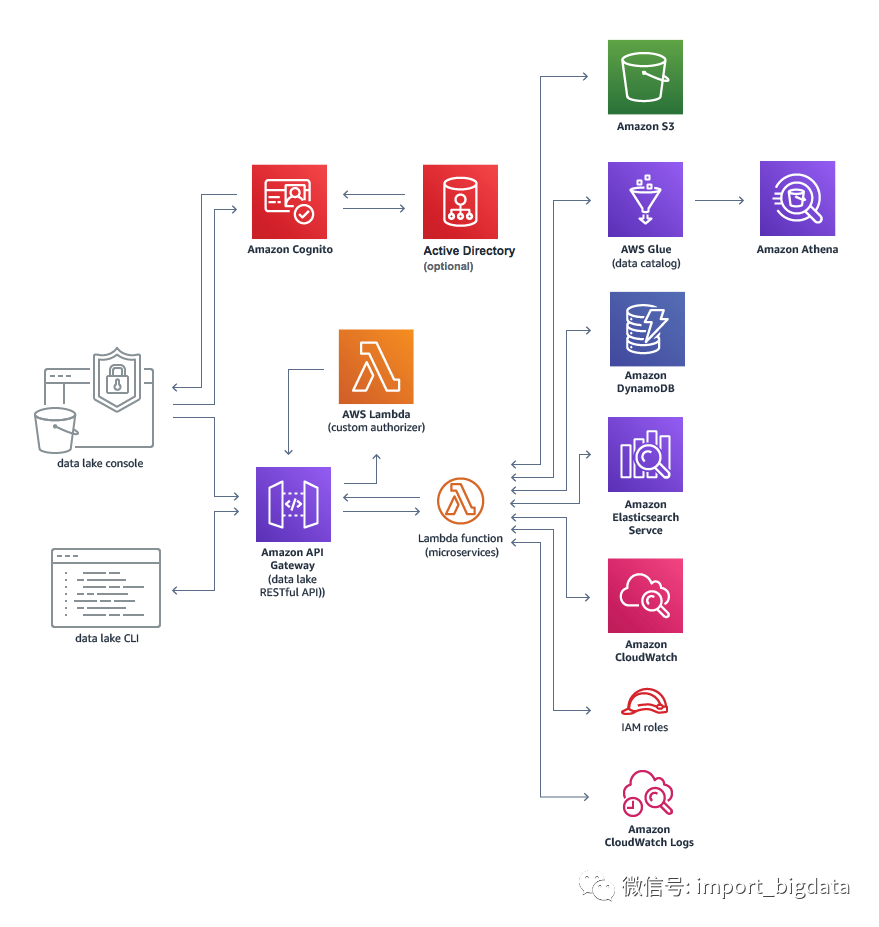
上图是AWS官网给出的数据湖解决方案。2018年,AWS 推出了 AWS Lake Formation,整个方案基于AWS Lake Formation构建。根据AWS的官网介绍,使用 AWS CloudFormation 模板可以在几分钟内完成数据湖架构的部署。
阿里云
很遗憾,我没有在阿里云官网找到一个比较完整的大图,但是我在一篇文章中找到了下面这张图:
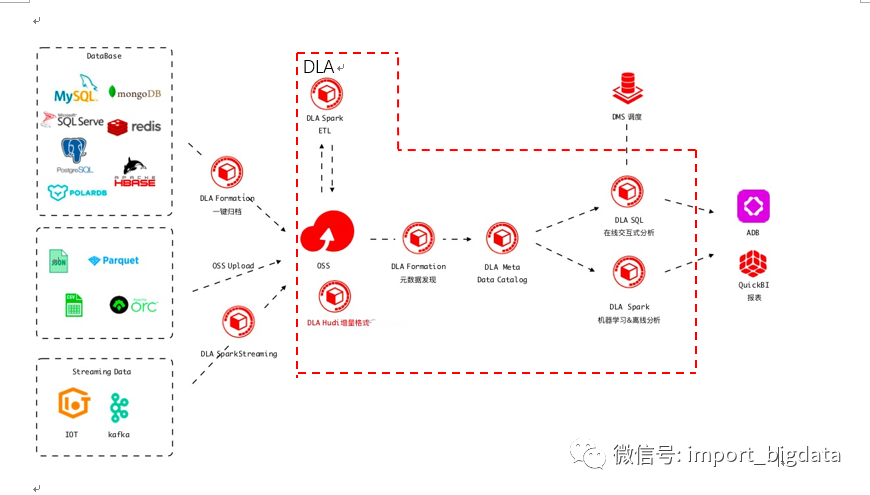
整个方案依然采用OSS作为数据湖的集中存储,其中的 Data Lake Formation 大概和 AWS 的AWS Lake Formation大同小异。
当然华为云和腾讯云等等都有自己的解决方案,整体上都和上面类似。
开源的方案
开源的方案,目前数据湖领域跳的最凶的三巨头包括:Delta、Apache Iceberg 和 Apache Hudi。因为篇幅原因,本文不在展开讨论了,小编在之前的文章中深度对比过这些解决方案的异同点:
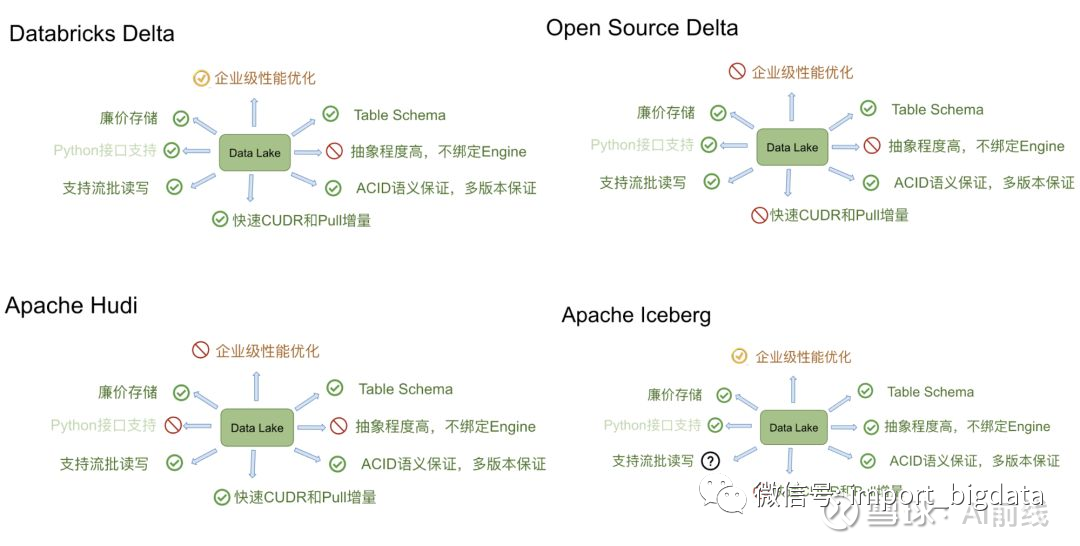
Apache Iceberg 和 Apache Hudi 因为全部开源,且社区蓬勃发展,目前是主流被各大小公司能接受的方案。
我的困惑
我的困惑不在于数据湖本身,而在于大众赋予数据湖的定义。
数据湖这个词是由Pentaho首席技术官詹姆斯迪克森最初提出的。截止目前为止,各大公司都对数据湖进行了自己的定义,但没有一个人能跳出来告诉我们谁是对的,谁是错的?
各大公司和开发者们,你们也不能因为数据架构上用了一个Hudi或者IceBerg就告诉我你们是【数据湖解决方案】。
那么我觉得,阿里云的惊玄老师说的有些道理:
数据湖不应该从一个简单的技术平台视角来看,实现数据湖的方式也多种多样,评价一个数据湖解决方案是否成熟,关键应该看其提供的数据管理能力,具体包括但不限于元数据、数据资产目录、数据源、数据处理任务、数据生命周期、数据治理、权限管理等,以及与外围生态的对接打通能力。
然而上述的这些能力,在传统的实时数仓、离线数仓、批流一体的数据仓库足够支持业务场景的情况下,什么时机去搞数据湖也值得深思。
难道像2020年初大家疯了似的上马Flink,然后一个月一个版本进行升级?
我踏马直呼内行。
所以我的观点【学而暂时不用】。
索性等大厂把坑填完了,我们直接短平快卡卡西过去就好。
