
数据湖存储的现状和趋势

导读:随着近几年数据湖概念的兴起,业界对于数据仓库和数据湖的对比甚至争论就一直不断。有人说数据湖是下一代大数据平台,各大云厂商也在纷纷的提出自己的数据湖解决方案,一些云数仓产品也增加了和数据湖联动的特性。
近几年数据湖的概念非常火热,但是数据湖的定义并不统一,我们先看下数据湖的相关定义。
Wikipedia对数据湖的定义:
数据湖是指使用大型二进制对象或文件这样的自然格式储存数据的系统。它通常把所有的企业数据统一存储,既包括源系统中的原始副本,也包括转换后的数据,比如那些用于报表, 可视化, 数据分析和机器学习的数据。数据湖可以包括关系数据库的结构化数据(行与列)、半结构化的数据(CSV,日志,XML, JSON),非结构化数据 (电子邮件、文件、PDF)和 二进制数据(图像、音频、视频)。储存数据湖的方式包括 Apache Hadoop分布式文件系统, Azure 数据湖或亚马逊云 Lake Formation云存储服务,以及诸如 Alluxio 虚拟数据湖之类的解决方案。数据沼泽是一个劣化的数据湖,用户无法访问,或是没什么价值。
AWS的定义相对简洁:
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
Azure等其他云厂商也有各自的定义,本文不再赘述。
但无论数据湖的定义如何不同,数据湖的本质其实都包含如下四部分:
统一的存储系统
存储原始数据
丰富的计算模型/范式
数据湖与上云无关
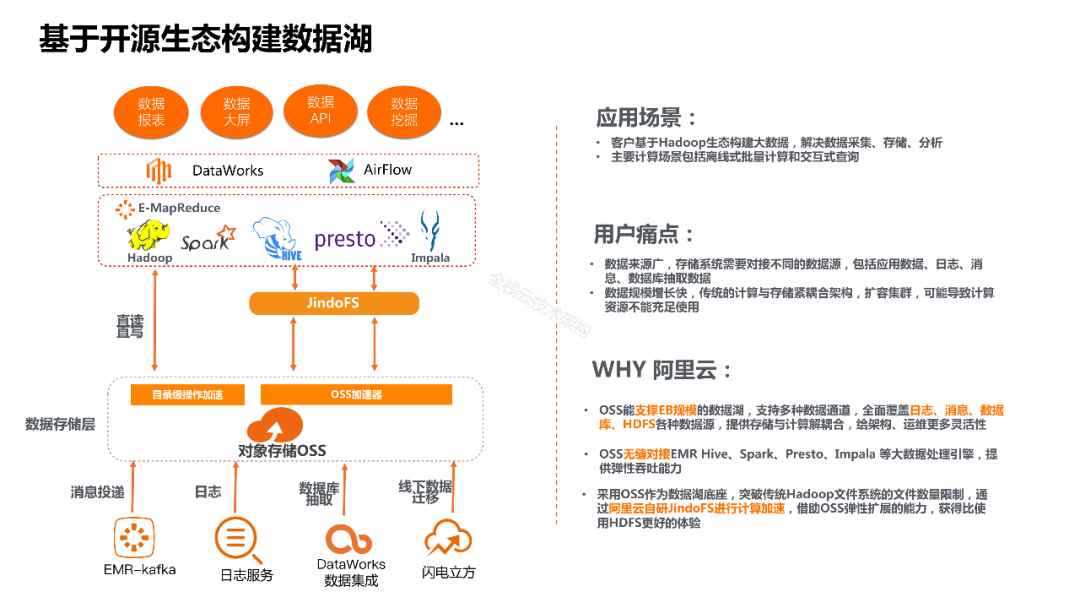
从上述四个标准判断,开源大数据的Hadoop HDFS存储系统就是一个标准的数据湖架构,具备统一的原始数据存储架构。而近期被广泛谈到的数据湖,其实是一个狭义的概念,特指“基于云上托管存储系统的数据湖系统,架构上采用存储计算分离的体系”。例如基于AWS S3系统或者阿里云OSS系统构建的数据湖。
下图是数据湖技术架构的演进过程,整体上可分为三个阶段:
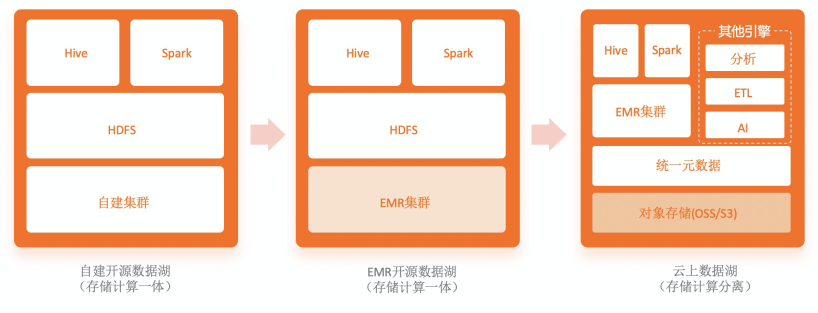
▲图3 数据湖技术架构演进
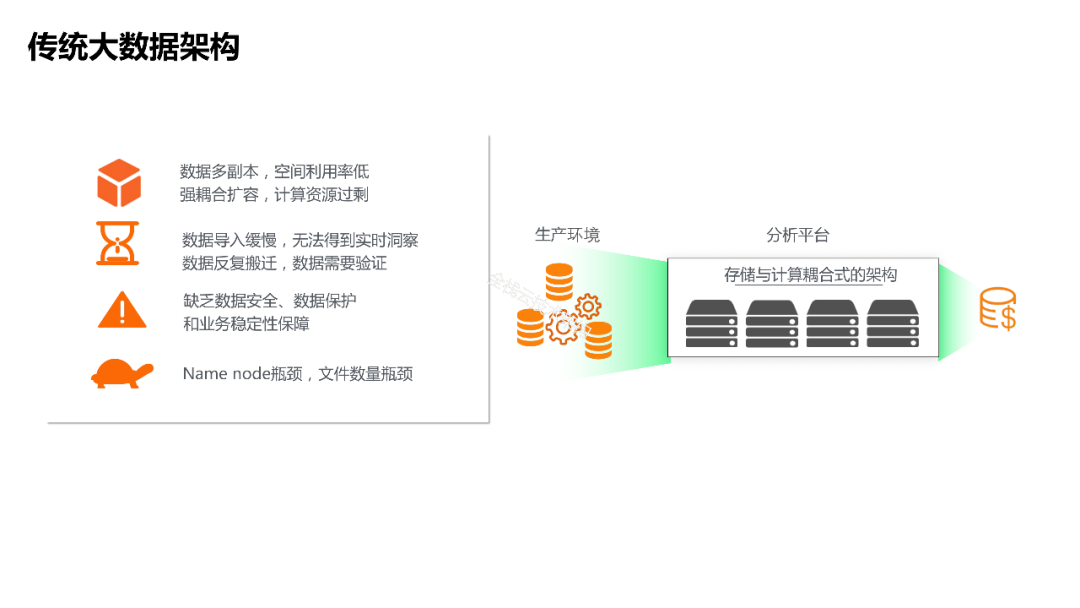
阶段一:自建开源Hadoop数据湖架构,原始数据统一存放在HDFS系统上,引擎以Hadoop和Spark开源生态为主,存储和计算一体。缺点是需要企业自己运维和管理整套集群,成本高且集群稳定性差。
阶段二:云上托管Hadoop数据湖架构(即EMR开源数据湖),底层物理服务器和开源软件版本由云厂商提供和管理,数据仍统一存放在HDFS系统上,引擎以Hadoop和Spark开源生态为主。
这个架构通过云上 IaaS 层提升了机器层面的弹性和稳定性,使企业的整体运维成本有所下降,但企业仍然需要对HDFS系统以及服务运行状态进行管理和治理,即应用层的运维工作。同时因为存储和计算耦合在一起,稳定性不是最优,两种资源无法独立扩展,使用成本也不是最优。
阶段三:云上数据湖架构,即云上纯托管的存储系统逐步取代HDFS,成为数据湖的存储基础设施,并且引擎丰富度也不断扩展。除了Hadoop和Spark的生态引擎之外,各云厂商还发展出面向数据湖的引擎产品。
如分析类的数据湖引擎有AWS Athena和华为DLI,AI类的有AWS Sagemaker。这个架构仍然保持了一个存储和多个引擎的特性,所以统一元数据服务至关重要,如AWS推出了Glue,阿里云EMR近期也即将发布数据湖统一元数据服务。
该架构相对于原生HDFS的数据湖架构的优势在于:
帮助用户摆脱原生HDFS系统运维困难的问题。HDFS系统运维有两个困难:1)存储系统相比计算引擎更高的稳定性要求和更高的运维风险 2)与计算混布在一起,带来的扩展弹性问题。存储计算分离架构帮助用户解耦存储,并交由云厂商统一运维管理,解决了稳定性和运维问题。
分离后的存储系统可以独立扩展,不再需要与计算耦合,可降低整体成本
当用户采用数据湖架构之后,客观上也帮助客户完成了存储统一化(解决多个HDFS数据孤岛的问题)
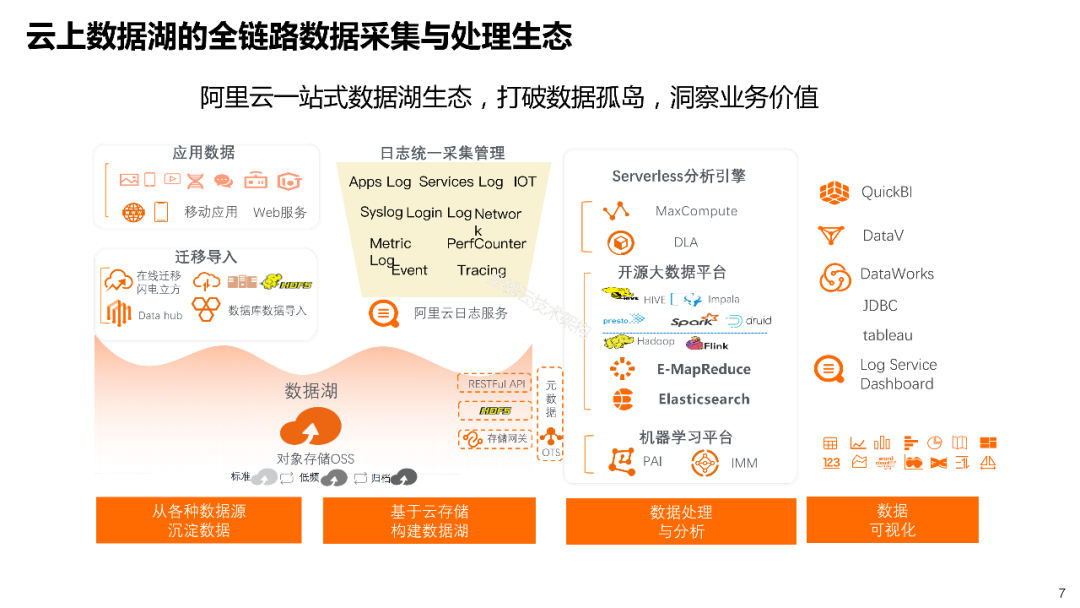
下图是阿里云EMR数据湖架构图,它是基于开源生态的大数据平台,既支持HDFS的开源数据湖,也支持OSS的云上数据湖。
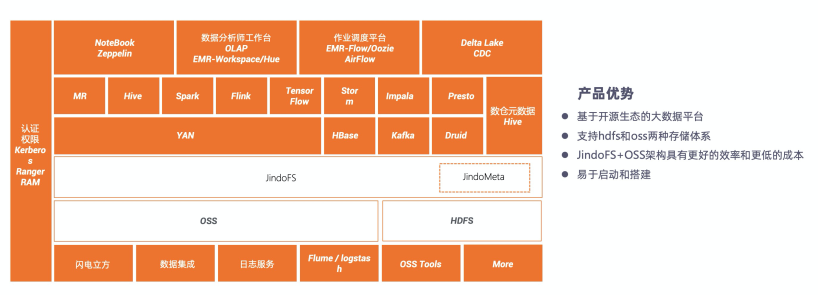
▲图4 阿里云EMR数据湖架构
企业使用数据湖技术构建大数据平台,主要包括数据接入、数据存储、计算和分析、数据管理、权限控制等,下图是Gartner定义的一个参考架构。当前数据湖的技术因其架构的灵活性和开放性,在性能效率、安全控制以及数据治理上并不十分成熟,在面向企业级生产要求时还存在很大挑战。
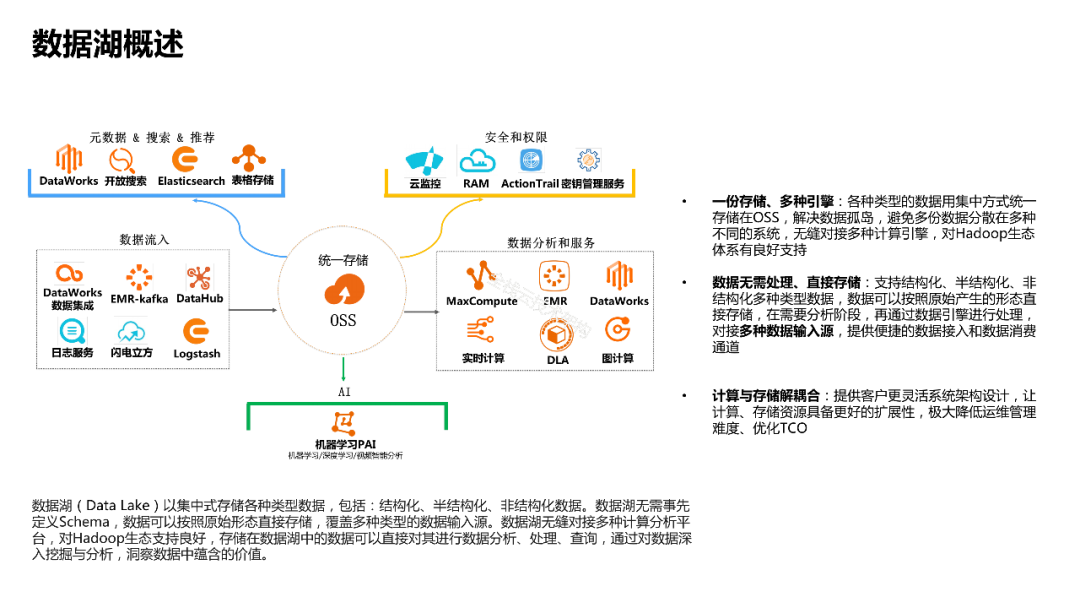
数据湖(Data Lake)以集中式存储各种类型数据,包括:结构化、半结构化、非结构化数据。数据湖无需事先定义Schema,数据可以按照原始形态直接存储,覆盖多种类型的数据输入源。数据湖无缝对接多种计算分析平台,对Hadoop生态支持良好,存储在数据湖中的数据可以直接对其进行数据分析、处理、查询,通过对数据深入挖掘与分析,洞察数据中蕴含的价值。
• 一份存储、多种引擎:各种类型的数据用集中方式统一存储在OSS,解决数据孤岛,避免多份数据分散在多种不同的系统,无缝对接多种计算引擎,对Hadoop生态体系有良好支持;
• 数据无需处理、直接存储:支持结构化、半结构化、非结构化多种类型数据,数据可以按照原始产生的形态直接存储,在需要分析阶段,再通过数据引擎进行处理,对接多种数据输入源,提供便捷的数据接入和数据消费通道
• 计算与存储解耦合:提供客户更灵活系统架构设计,让计算、存储资源具备更好的扩展性,极大降低运维管理难度、优化TCO。
下载链接:



推荐阅读:
不是你需要中台,而是一名合格的架构师(附各大厂中台建设PPT)