说在前面
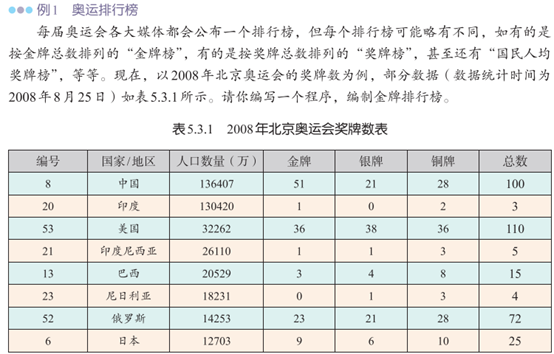
“奥运排行榜”是一个源于实际的排序问题,每个国家的信息是一条记录,包含编号、国家/地区、人口数量、各奖牌数等数据项,根据不同的排序标准,对各条记录进行排序。
教材程序采用一个二维数组来存储数据,每个元素表示一条记录,排序时可以对整条记录进行交换操作。教材还提供了“思考与练习”,继续研究不同数据结构和排序要求下,冒泡排序的不同实现方法,要求学生理解数据结构与算法的关系,值得深入探讨。
教材文本



教材处理
教材程序首先读取csv文件,再逐行将数据插入到二维数组a中,数组a的每个元素都是一个字符串列表,例如a[1]的值为['8', '中国', '136407', '51', '21', '28', '100']。程序在执行冒泡排序时,以金牌数为关键字进行降序排序,故需要先使用int()函数将a[j][3]转换成整数,再作比较。因为a[0]的值是标题,所以不参与排序,这虽然能够解决问题,但造成了隐患,最好是不要把标题存储到a中,这样排序时就可以放心大胆地套用代码模板了。可以引导学生自行编程解决奥运排行榜问题,并比较其与教材程序的异同。学生任务单
阅读教材P132例1“奥运排行榜”,思考如下问题:(1)教材程序中变量a是何种数据结构?其元素值(例如a[3])是什么数据类型?(2)教材程序是如何对数组a排序的?a[0]是否参与的排序?为什么?(3)下列程序也能解决奥运排行榜问题,试比较其与教材程序的异同,并完成填空。csvFile = open("jp.csv", "r") #打开相应数据文件reader = list(csv.reader(csvFile)) # 转换成列表,以便跳过第一行for i in range(1,len(a)): csvFile2 = open('jp2.csv','w', newline='')writer = csv.writer(csvFile2, dialect='excel')writer.writerow(reader[0]) #先写入标题(4)书中程序采用1个二维数组来存储数据,若改成以7个一维数组来存储数据,又该如何编程实现以金牌数为关键字进行降序排序功能?csvFile = open("jp.csv", "r") #打开相应数据文件reader = list(csv.reader(csvFile)) #转换成列表,以便跳过第一行a1 = [item[0] for item in reader[1:]] #编号a3 = [item[2] for item in reader[1:]] #人口数量a4 = [item[3] for item in reader[1:]] #金牌a5 = [item[4] for item in reader[1:]] #银牌a6 = [item[5] for item in reader[1:]] #铜牌for i in range(1,len(a1)): for j in range(len(a1) - i): if int(a4[j]) < int(a4[j+1]):csvFile2 = open('jp2.csv','w', newline='')writer = csv.writer(csvFile2, dialect='excel')writer.writerow(reader[0]) #先写入标题(5)依然采用1个二维数组来存储数据,若将排序关键字改为“国民人均奖牌数”,并按升序排序,该如何编程实现以金牌数为关键字进行降序排序功能?问题解析
(1)a是一个二维数组,其元素值是一个字符串数组,其中a[3]的值为['53', '美国', '32262', '36', '38', '36', '110'],a[3][3]也是一个字符串,可以使用int(a[3][3])将其转换成整数,表示金牌数量。
(2)书中程序采用冒泡排序算法,以金牌数为关键字,对数组a进行降序排序。因为a[0]存储的是标题,故不参与排序。程序的内层循环从下标1开始遍历数组,这样可以跳过a[0]。
(3)填空1:len(a) - i;
填空2:int(a[j][3]) < int(a[j+1][3]);
填空3:a[j+1], a[j];
填空4:i。
(4)填空1:item[1] for item in reader[1:];
填空2:item[1] for item in reader[1:];
填空3: a1[j], a1[j+1] = a1[j+1], a1[j]
a2[j], a2[j+1] = a2[j+1], a2[j]
a3[j], a3[j+1] = a3[j+1], a3[j]
a4[j], a4[j+1] = a4[j+1], a4[j]
a5[j], a5[j+1] = a5[j+1], a5[j]
a6[j], a6[j+1] = a6[j+1], a6[j]
a7[j], a7[j+1] = a7[j+1], a7[j]
填空4:[a1[i],a2[i],a3[i],a4[i],a5[i],a6[i],a7[i]]。
(5)参考代码如下:
import csv
#数据读入
csvFile = open("jp.csv", "r") #打开相应数据文件
reader = list(csv.reader(csvFile)) # 转换成列表,以便跳过第一行
a = []
for item in reader[1:]:
a.append(item)
csvFile.close()
#排序:关键字“国民人均奖牌数”,按升序排序
for i in range(1,len(a)):
for j in range(len(a) - i):
if int(a[j][6])/int(a[j][2]) > int(a[j+1][6])/int(a[j+1][2]):
a[j], a[j+1] = a[j+1], a[j]
#数据写入
csvFile2 = open('jp2.csv','w', newline='')
writer = csv.writer(csvFile2, dialect='excel')
writer.writerow(reader[0]) #先写入标题
for i in a:
writer.writerow(i)
csvFile2.close()
课后作业
任务(4)以7个一维数组来存储数据,当以金牌数为关键字进行降序排序时,不仅是对a4排序,其他6个数组的元素值也要相应变化,效率不高。因为这7个数组的结构一致,相同下标对应同一个国家,故我们可以增加一个索引数组b,专门用来存储这7个数组的下标,这样只需对索引数组b排序,数组a1-a7可以保持不变。输出数组元素时,只要设置正确的索引值,就能实现排序的效果。
这种排序方法被称为“索引排序”,参考代码如下,请将缺失的代码补充完整。
csvFile = open("jp.csv", "r") #打开相应数据文件reader = list(csv.reader(csvFile)) #转换成列表,以便跳过第一行a1 = [item[0] for item in reader[1:]] #编号a3 = [item[2] for item in reader[1:]] #人口数量a4 = [item[3] for item in reader[1:]] #金牌a5 = [item[4] for item in reader[1:]] #银牌a6 = [item[5] for item in reader[1:]] #铜牌b = [i for i in range(len(a1))] #设置索引数组for i in range(1,len(a1)): for j in range(len(a1) - i): if int(a4[b[j]]) < int(a4[b[j+1]]):csvFile2 = open('jp2.csv','w', newline='')writer = csv.writer(csvFile2, dialect='excel')writer.writerow(reader[0]) #先写入标题需要本文word文档、源代码和课后思考答案的,可以加入“Python算法之旅”知识星球参与讨论和下载文件,“Python算法之旅”知识星球汇集了数量众多的同好,更多有趣的话题在这里讨论,更多有用的资料在这里分享。
我们专注Python算法,感兴趣就一起来!
阅读代码和写更好的代码
最有效的学习方式
Python算法之旅文章分类
