研究人员提出针对GPT-3等语言模型的偏差修正

大数据文摘出品
来源:VB
快速学习或从几个示例中学习任务的能力是人工智能的关键与强项。像OpenAI的GPT-3这样的大型AI自然语言模型无需精调即可执行多次学习。
但是,新的研究却发现,语言模型(尤其是GPT-3)的准确性,在没有校准的情况下可能会“高度不稳定”。
这项由加州大学伯克利分校、加州大学欧文分校和马里兰大学的科学家合作完成的研究主要聚焦于GPT-3等模型存在的缺陷。
OpenAI本身也指出,GPT-3在女性代词旁边放置了“naughty”等带有主观意识的单词,而在“恐怖主义”之类的单词附近放置了“伊斯兰教”。
斯坦福大学博士候选人、Gradio创始人Abubakar Abid的一篇论文详细描述了GPT-3产生的反穆斯林倾向。米德尔伯里国际研究中心的恐怖主义,极端主义和反恐中心声称,GPT-3可以可靠地产生“信息性”和“有影响力的”文本,这些文本可能“将个人激化成暴力的极右翼极端主义意识形态和行为”。
在假设GPT-3易受某些类型的不稳定影响的前提下,研究人员使用来自数据集的训练示例(通过文本分类,事实检索和信息提取)通过OpenAI API对模型进行了基准测试。这些示例具有各种不同的格式和顺序,包括问题答案模板,对话样式模板以及类似于特定网页的提示。
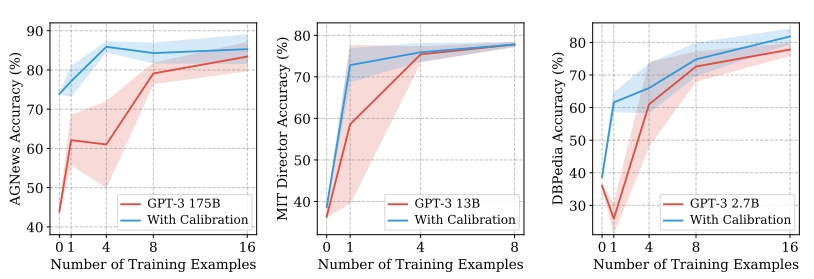
在他们的实验中,研究人员发现,关于格式和顺序的不同选择可能会导致准确性波动。例如,在GPT-3对情感示例进行分类时更改其顺序会促使其准确性从近机率(54%)转变为最新水平(93%)。有趣的是,在训练示例中添加更多的训练示例并不一定会降低准确性的差异,有些训练示例甚至会损害准确性。
研究人员说,他们发现了三个导致GPT-3等语言模型偏向某些答案的陷阱:多数标签偏见,新近度偏见和通用标记偏见。多数标签和新近度偏差会使模型预测经常出现或在提示即将结束时出现的答案。另一方面,常见的令牌偏向导致模型更喜欢在其预训练数据中频繁回答的问题,例如“美国”而不是“圣卢西亚”。
研究人员试图通过“校准”输出分布来抵消这些偏差,通过输入无内容的虚拟输入(例如“ N / A”)来估计模型对某些答案的偏差。他们安装了校准参数,因此无内容输入对每个答案具有统一的分数,他们声称无需任何培训数据就可以很好地设置参数。
实验结果表明,校准可以在提示格式和示例之间不断提高GPT-3的准确性,同时使准确性更加稳定。共同作者在描述其工作的论文中写道:“通过详细的分析,我们发现这种波动性是由语言模型的偏差引起的,例如,它们倾向于输出最新或通用标记的趋势。”
“我们利用这些见识来开发上下文校准,这是调整模型输出概率的简单程序,可提高准确性,减少差异,并总体上使GPT-3之类的工具对最终用户更有效。”