谷歌提出多语言BERT模型:可为109种语言生成与语言无关的跨语言句子嵌入

新智元报道
新智元报道
来源:Google
编辑:雅新
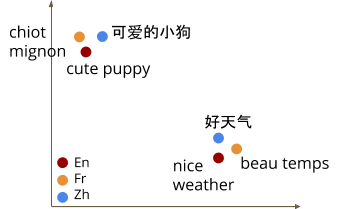
【新智元导读】谷歌研究人员提出了一种LaBSE的多语言BERT嵌入模型。该模型可为109种语言生成与语言无关的跨语言句子嵌入,同时在跨语言文本检索性能优于LASER。

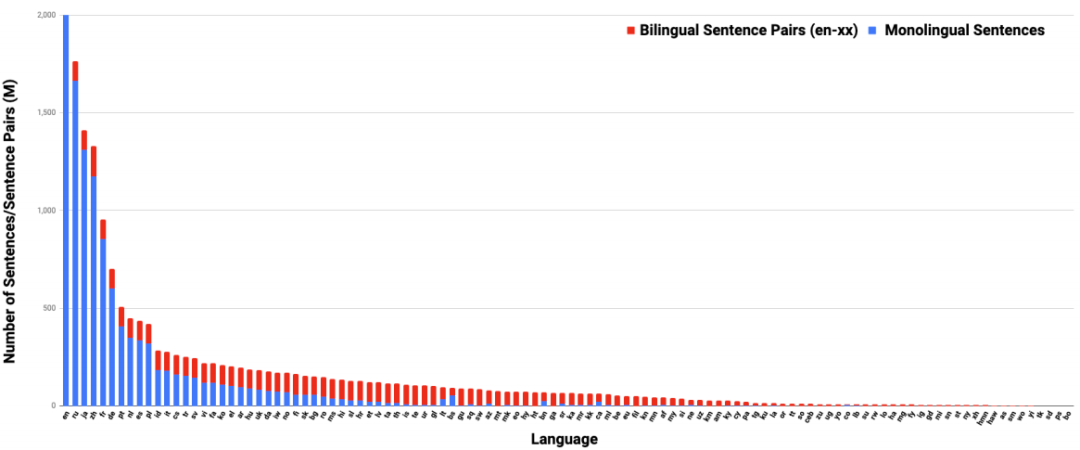 收集109种支持语言的训练数据
收集109种支持语言的训练数据
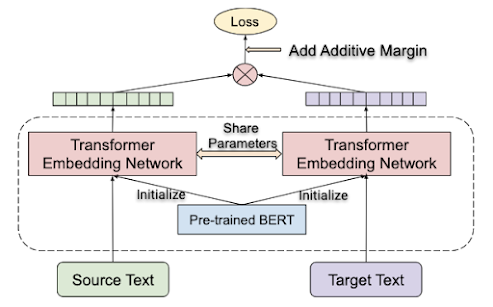

参考链接:
https://ai.googleblog.com/


评论
 下载APP
下载APP
新智元报道
来源:Google
编辑:雅新
收集109种支持语言的训练数据
参考链接:
https://ai.googleblog.com/