
三星提出XFormer | 超越MobileViT、DeiT、MobileNet等模型


ViT的最新进展在视觉识别任务中取得了出色的表现。卷积神经网络 (CNN) 利用空间归纳偏差来学习视觉表示,但这些网络是空间局部的。ViTs可以通过其self-attention机制学习全局表示,但它们通常是heavy-weight的,不适合移动设备。在本文中提出了
Cross Feature Attention(XFA) 以降低Transformer的计算成本,并结合高效的mobile CNNs形成一种新颖的高效轻量级CNN-ViT混合模型XFormer,可作为通用主干学习全局和局部表示。实验结果表明,
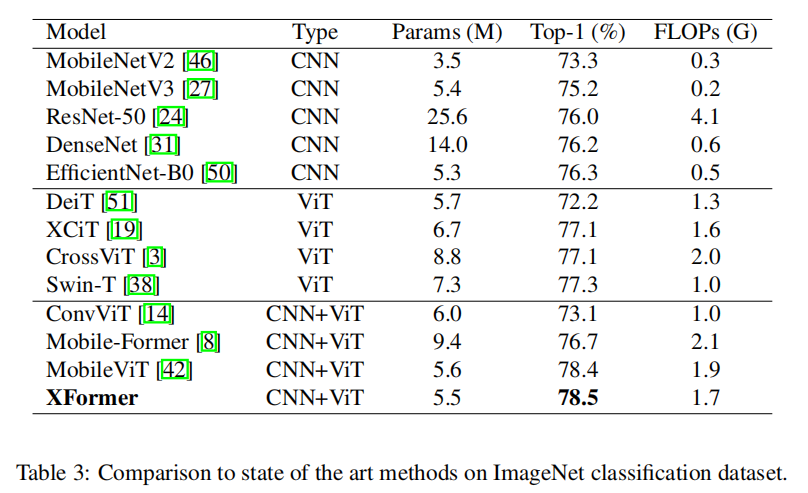
XFormer在不同的任务和数据集上优于众多基于CNN和ViT的模型。在ImageNet-1K数据集上,XFormer使用 550 万个参数实现了78.5%的top-1准确率,在相似数量的参数下,比EfficientNet-B0(基于CNN)和DeiT(基于ViT)的准确率分别提高了2.2%和6.3%。
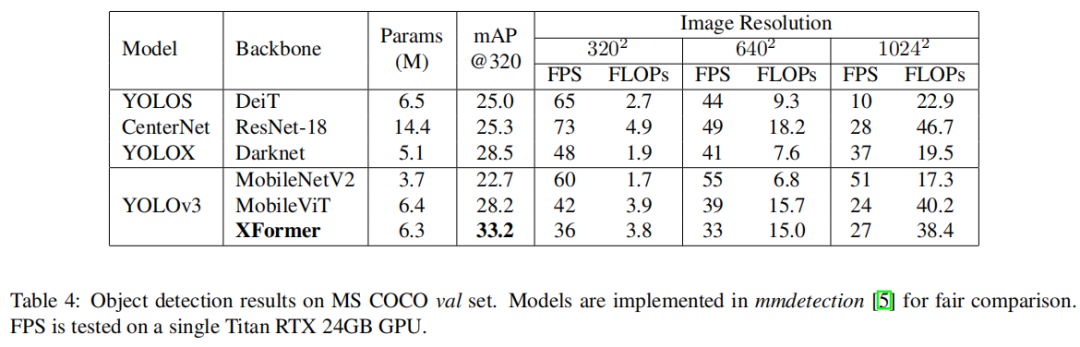
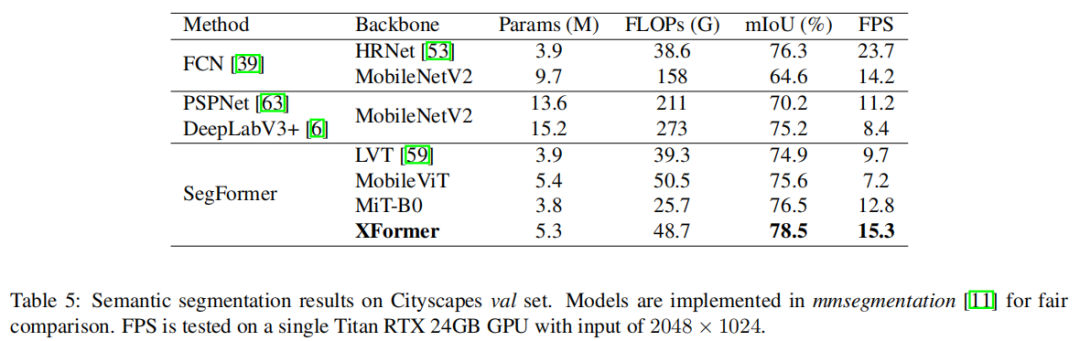
XFormer的模型在转移到目标检测和语义分割任务时也表现良好。在MS COCO数据集上,XFormer在YOLOv3框架中超过MobileNetV210.5 AP(22.7→33.2AP),只有 6.3M 参数和 3.8G FLOPs。在Cityscapes数据集上,只有一个简单的all-MLP解码器,XFormer实现了78.5的mIoU和15.3的FPS,超过了最先进的轻量级分割网络。
1Method
一个标准的 ViT 模型首先使用patch size h×w 将输入 reshape为一系列flattened patches ,其中 和 表示token数。然后将 投影到固定的 D 维空间 并使用一堆transformer blocks来学习inter-patch表示。由于忽略了空间归纳偏差,ViT 通常需要更多参数来学习视觉信息。此外,transformers 中 self-attention 的昂贵计算导致优化此类模型的瓶颈。
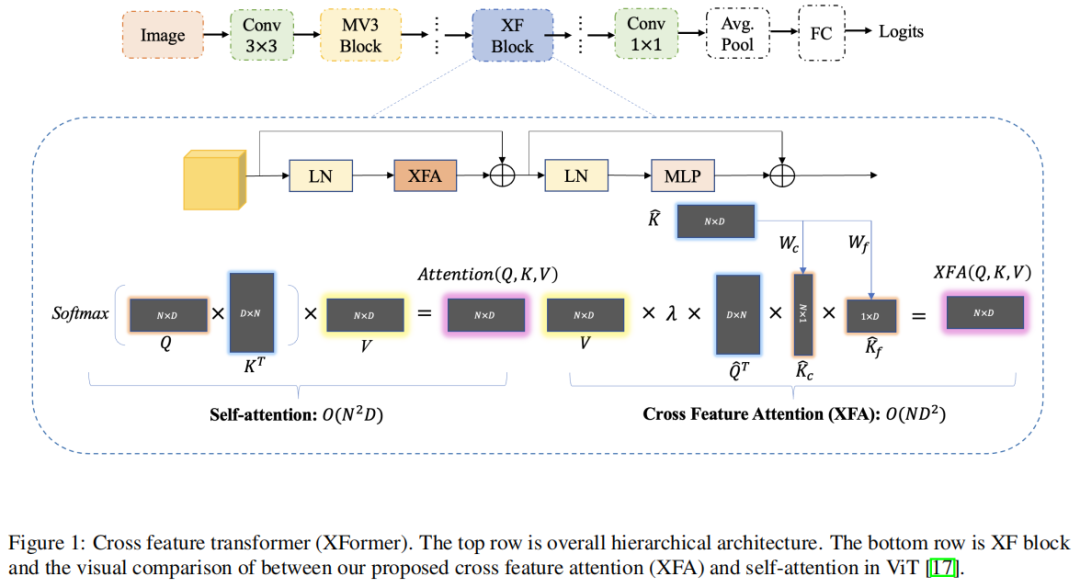
在本节提出了 XFormer,这是高效、轻量级的 CNN-ViT 框架,以解决 ViT 中的上述问题。首先介绍了一种提高自注意力效率的新方法,然后说明了新的 CNN-ViT 混合模型的架构设计。
1.1 Cross Feature Attention (XFA)
1、Attention Overview
Transformer 的主要计算瓶颈之一在于 self-attention 。在最初的 self-attention 过程中, 首先用于通过线性投影生成query Q、key K 和value V。它们都具有相同的维度(N × D),其中 N 是图像token数,每个维度为 D。然后计算注意力分数为:
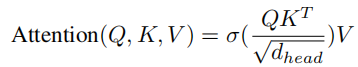
其中 σ 是 softmax 操作, 是head维度。计算注意力分数的计算复杂度为 。 self-attention 的二次复杂性导致了巨大的计算瓶颈,这使得 ViT 模型难以在移动设备上按比例缩小。
2、Efficient Attention
为了解决 self-attention 中的二次复杂性问题,作者提出了一种新的注意力模块结构,称为Cross Feature Attention(XFA)。在之前的工作之后,首先沿特征维度 D 对query Q 和key K 应用 L2 归一化:
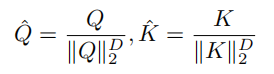
在原始 self-attention 中的直觉是定位应该关注的重要图像块。
但是直接计算会导致不必要的冗余和计算开销。相反,作者为 K 构建了2个中间分数:查询上下文分数 和查询特征分数 。使用2个卷积核矩阵 和 沿token维度 N 计算 ,沿特征维度 D 计算 。借助卷积滤波器中间分数向量可以表示计算注意力图的更紧凑的表示,同时也降低了计算成本。 和 表示为:
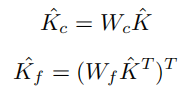
最后,将Cross Feature Attention(XFA)定义为:
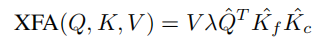
其中 λ 是一个温度参数,用于动态调整不同transformer层中的比例因子,从而提高训练稳定性。注意到归一化将注意力值限制在一定范围内,因此放弃了冗余且昂贵的 softmax 操作。与原始的具有二次复杂度的 self-attention 不同,XFA模块将计算成本从 降低到 .
3、Comparison with Self-attention
本文提出的 XFA 模块和原始注意力之间的主要区别是:
XFA通过构建中间查询上下文和特征分数,沿特征维度D计算注意力图,大大降低了计算成本;XFA使用可学习的温度缩放参数来调整归一化,并且不受softmax操作的影响。
本文方法为二次复杂度问题提供了解决方案,并且对于资源受限的设备更有效且对移动设备更友好。
1.2 Building XFormer
1、MobileNetV3 Block
MobileNetV2 首先引入了inverted residual和linear bottleneck以构建更高效的层结构。MobileNetV3 随后添加了squeeze excitation (SE) 模块以处理更大的表示特征。最近的工作证明了通过在 ViT 的早期阶段结合卷积层来提高 ViT 性能的合法性。受这种直觉的启发,继续为轻量级模型探索这种 CNN-ViT 混合设计。MobileNetV3 块内的操作可以表述为:
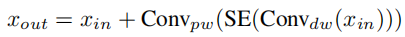
其中 是前一层的输入特征, 是 MV3 Block 的输出特征,SE 是squeeze excitation模块。 表示depth-wise卷积操作, 表示point-wise卷积操作。
2、XF Block
利用提出的Cross Feature Attention模块介绍了 XF Block,一个精心设计的轻量级 transformer module。XF Block内的操作可以表述为:
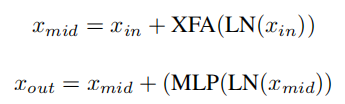
其中 是前一层的输入特征, 是 XFA 模块的特征, 是 XF Block 的输出特征。LN 表示层归一化操作,MLP 为全连接层。
3、Patch Size Choice
对于较大的模型(ViT-Large),基于 ViT 的模型通常采用 8×8、16×16 甚至 32×32 的Patch Size。具有较大Patch Size的优点之一在于,对于分类等图像级任务,ViT 可以有效地提取图像块信息,而不会增加过多的计算开销。
最近的工作表明,当迁移到语义和实例分割等下游任务时,更小的Patch Size更受青睐,因为它可以增强 Transformer 学习更好的像素级信息的能力,这通常会带来更好的性能。
此外,随着Patch Size的减小,token数 N 会大得多。线性复杂度 XFA 模块可以避免潜在的计算瓶颈。在网络设计中,每个 XF 块的Patch Size设置为 2×2。
4、XFormer
在 MobileNetV3 和 XF Block 的基础上提出了 XFormer,这是一种 CNN-ViT 混合轻量级模型,由堆叠的 MobileNetV3 Block 和 XF Block 组成,用于学习全局和局部上下文信息。与之前设计高效 CNN 的工作一样,本文的网络由 块组成,用于提取原始图像特征,在特征由 CNN 和transformer blocks处理后,使用 、全局池化和全连接层来产生最终的 logit 预测。
在主要处理块中,XFormer 有5个阶段。前2个阶段仅包含 MobileNetV3 Block (MV3) ,因为卷积块比全 ViT 模型更能提取重要的图像级特征表示,并随后帮助转换器块看得更清楚。最后三个阶段中的每一个都包括一个 MV3 块和几个 XF 块。结合来自 MV3 块的局部归纳偏差和来自 Transformer Block 的全局信息,网络可以学习更全面的特征表示,可以轻松地转移到不同的下游任务。
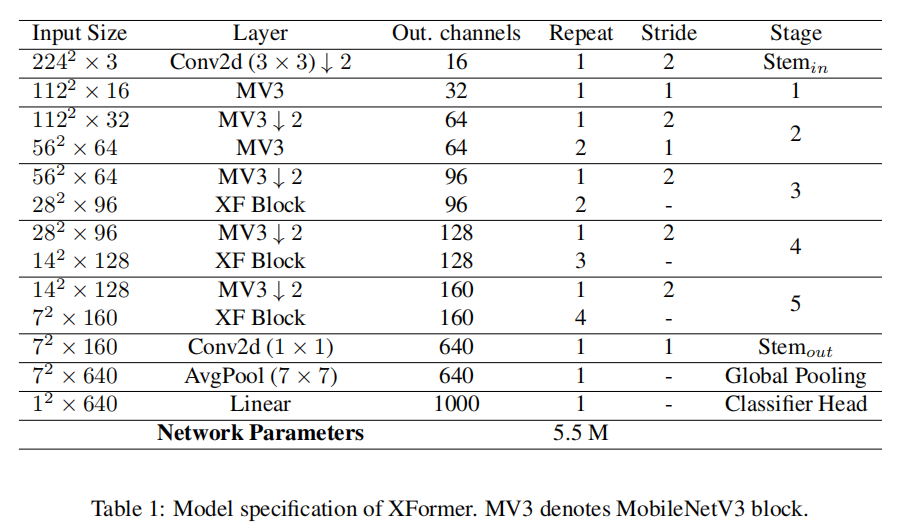
先前关于 ViT 的工作表明,应在更深的Transformer layers中使用更大的 MLP 比率,并且 Q-K-V 维度应相对小于嵌入维度,以便在性能和模型大小之间进行更好的权衡。作者遵循这些建议并相应地设计轻量级模型。对于三个不同阶段的 XF Block ,它们的 MLP 比率、嵌入维度和 Q-K-V 维度分别设置为(2、2、3)、(144、192、240)和(96、96、96)。在全连接层中将 ReLU 替换为 GELU 激活;在所有其他层中使用 SiLU。对于 MV3 Block,扩展比均设置为 4。规格如表 1 所示。
5、Model efficiency
模型的总参数大小只有 550 万。与类似大小的基于 ViT 的模型相比,本文的模型可以更有效地处理高分辨率图像并避免潜在的内存瓶颈(见表 2)。
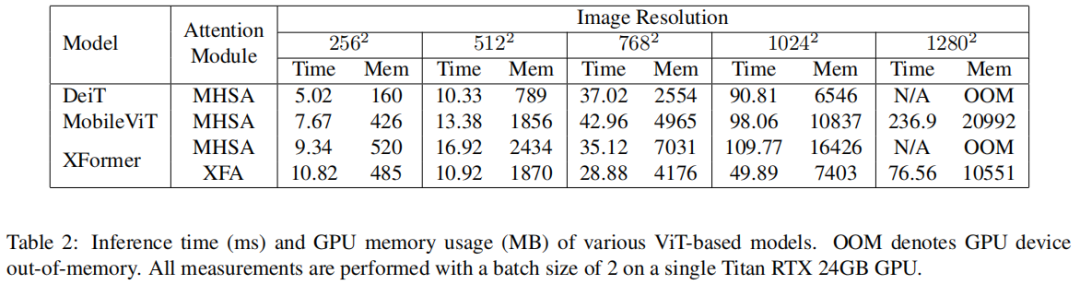
例如,当输入分辨率为 1024×1024 时,与使用原始自注意力的 MobileViT 相比,XFormer 的推理速度提高了近 2 倍,GPU 内存使用量减少了 32%。本文的模型可以轻松处理高分辨率吞吐量,而不会出现内存瓶颈。最重要的是,XFormer 提供了比比较模型更好的精度(参见表 3),在模型大小和性能之间实现了很好的平衡。
2实验
2.1 图像分类
2.2 目标检测

2.3 语义分割

3参考
[1].Lightweight Vision Transformer with Cross Feature Attention
4推荐阅读
ECCV2022 Oral | 全新Ancho-free检测模型ObjectBox,120FPS超越OTA、TOOD等
Transformer 落地出现 | Next-ViT实现工业TensorRT实时落地,超越ResNet、CSWin
超越 ConvNeXt、RepLKNet | 看 51×51 卷积核如何破万卷!
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
