
小白都能懂的推荐算法入门(三),FM、类别特征以及Embedding
点击上方蓝字,关注并星标,和我一起学技术。
大家好,上一期文章我们聊了FM模型在推荐系统当中起到的作用,以及它的一些缺点。
今天我们继续来聊FM,不过不是单纯聊FM的原理了,而是聊聊更深层次的方法论,以及FM家族的一些改进策略。
Embedding
FM之所以效果很好,除了模型做了所有特征的二阶交叉之外,很重要的原因是它对类别特征做了embedding。
还没入门的同学不要觉得蒙,embedding其实很好理解,我们就当做是向量理解就可以了,它可以理解成把一个单个的标量转化成一个向量的形式。大家如果对NLP有所了解的话,会知道在NLP当中有一个基础算法叫做Word2vec,这个Word2vec讲的就是单词到向量的转化。我们可以通过算法模型通过学习文本单词的上下文关系,从而学习到每一个单词的向量表达。有了向量表达之后,我们就可以利用向量的性质做很多事。
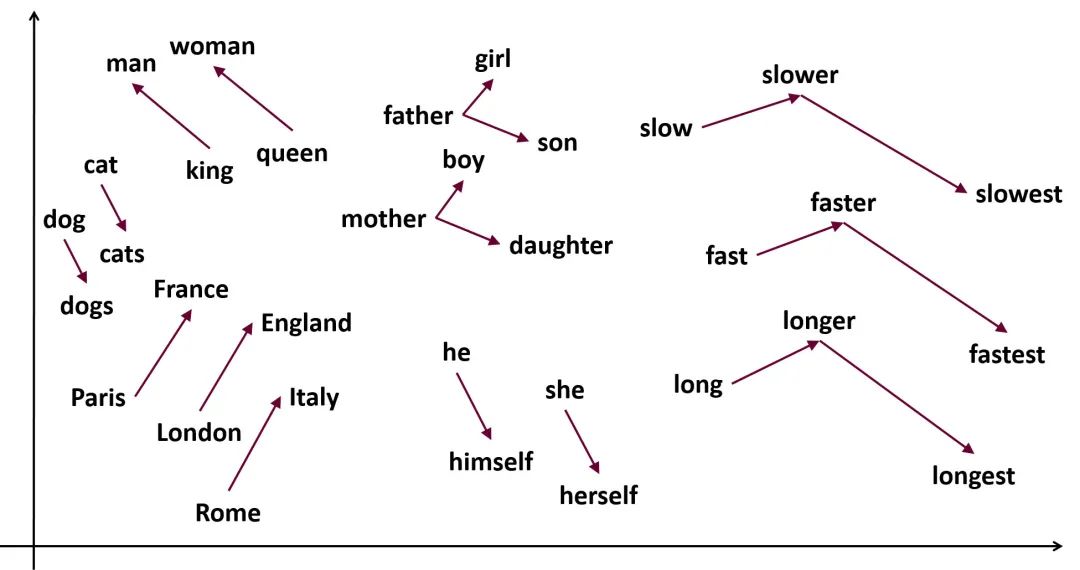
我在网上找了一张示意图,当单词被表达成向量之后,意思相近的单词的向量也会非常接近。利用向量的性质我们可以做很多有意思的事情,比如近义词同义词分析,比如近义词召回,机器翻译等等。
在推荐领域当中的embedding和NLP差不太多,本质上也是把一个特征转化成向量。当然推荐领域一般不会直接用这个向量来表达,而是将它作为模型的输入。
到这里我们先暂停一下,先来思考一个问题:为什么把单个特征转化成向量效果会更好?
这个其实可以有很直观的解释,比如我们有一个特征是性别。如果性别作为一个单个特征,对于模型来说就只有0和1两个意思。但对于我们人类,其实是有很多层含义的。比如说女性大概率会喜欢美妆用品,女性在电商平台的表现也会比男性活跃,女性对于折扣更加敏感……只要我们愿意思考,可以想出很多的这样的特性来。显然这么多复杂的特性只用简单的0和1是无法表达的,所以这就是为什么我们要把它转化成向量的原因,因为向量的维度更高,表达能力更强。
第二个是当前的基于深度神经网络的模型有能力消化这些高维度的特征,神经网络当中有大量的神经元,神经元之间存在大量的信号传递,可以充分学习到高维度向量当中的含义。
你可能还会有问题,那从哪里可以搞到特征的向量表达呢,我们怎么知道怎么表达特征才是正确的呢?这个问题很简单,我们并不需要额外去准备特征的embedding,我们只需要将它作为模型的参数的一部分,让它通过梯度下降自己学习即可。也就是说embedding本身就是模型参数的一部分,模型收敛了,embedding也就有了,并不需要我们额外操心。
正是因为有了embedding,推荐、搜索等引擎的效果才有了大幅提升,而embedding的使用正是从FM模型开始的。FM模型用一个向量V来表示特征之间交叉权重的做法,其实就是一种embedding。
VIP类别特征
有了embedding之后,自然而然地带来了一个有趣的变化:推荐系统当中的类别特征逐渐都变成了VIP,而实数型特征则江河日下到了淘汰的边缘。
我们如果来分析一下电商场景下的推荐,你会发现当中有一个很重要的环节就是“打标签”。也就是给用户给商品打上各种各样的标签,然后通过推荐引擎来通过这些标签进行推荐。
比如说你喜欢电子产品,那你就是一个“电子达人”,她喜欢裙子,那她是“时尚女装”。这个商品很热销,那它是“当季爆款”,有个商品封面放了个大胸妹很吸引人,那它是“标题党”等等……
有了标签之后,模型就可以很容易理解到这些标签之间的作用关系。比如一个电子达人多半是直男,是不会对洛丽塔感兴趣的。同样爆款商品往往也只能吸引那些对于折扣、促销比较敏感的人群,对于钢铁直男同样没有效果……并且由于系统可以拿到用户在平台上活动的所有数据,我们还可以根据用户之前的行为来进行分析。
比如说用户在这一次登陆之前浏览的一直是女装商品,那即使他原本的标签是”钢铁直男“,那么系统也会因地制宜,实时了解到他兴趣的变化,给女装商品提升权重,增加曝光。
正是有了标签一样的特征,模型才能有很好的泛化能力。如果我们把商品的标签转化成商品最近的点击率、最近的转化率、最近的成交额、最近的好评数等特征,你想想看模型还能做出这样神奇的推荐吗?显然不行,因为实数型的特征没有办法做成embedding, 模型表达的能力也会受到影响。
除此之外一些实数型特征和推荐目标之间没有线性关系,比如年龄,你能说年龄越大越喜欢游戏机吗?显然不是,年龄太小或者年龄太大都不行,就只有某一个年龄段最喜欢。
所以最好的办法是对这些实数型的特征分桶,将它强行转化成类别特征。比如18岁以下一个桶,18到30岁一个桶,30岁到50一个桶,50以上一个桶。这样模型拿到的才不会是一个简单的年龄值,而是一个分段,而是一个可以转化成向量的标签。
正是因为以上一系列原因,在推荐系统当中类别特征成了VIP中的VIP,几乎统治一切,很多实数型特征也都会被强行转化成类别特征,沦落称为小弟。我们不仅要了解这些现象,更要透过现象看到本质,了解到变化产生的原因。
AFM和FFM
我们了解embedding和类别特征对于模型的意义之后,再回过头来看FM,会发现FM几乎都涉及到了。只不过FM毕竟还是机器学习时代提出的算法模型,对于神经网络超强的泛化和拟合能力没有很好地使用,所以在后来的深度学习时代有一点点落伍。这并不能说是FM模型设计得不好,相反,它已经是相当超前的设计,使得它横跨十几年即使到了神经网络时代依然能大展身手。
今天我们来简单聊聊关于FM模型的两个演化版本,可以理解成1.1版本。
FFM
FFM模型非常简单,它只是在FM的基础上做了一个很小的优化,即增加了field的概念。原本的FM在做特征交叉的时候,所有特征交叉的权重都一样,也都使用同一个参数向量V。
这样的好处是泛化能力比较强,但是缺点也是太单一了,x和所有的特征y交叉都用同一个向量,一刀切太过粗暴了。所以FFM提出了field的概念,即每个特征都会被映射成多个隐向量:。每个隐向量对应一个field,当两个特征交叉组合的时候,用对方对应的场下对应的隐向量来做内积:
引入了field之后,使得同一个特征x可以做到和不同的向量交叉时使用不同的向量,从而提升了模型的的泛化能力。
AFM
先来说说AFM,AFM我之前写过它的论文解析,感兴趣的同学可以点击下方传送一下。
推荐领域又一经典paper,分分钟搞清楚Attention机制
AFM的模型结构和原理很简单,一点也不复杂,就是在FM两两特征交叉的地方加上了一个Attention网络。这个Attention网络用来学习两个向量的权重。
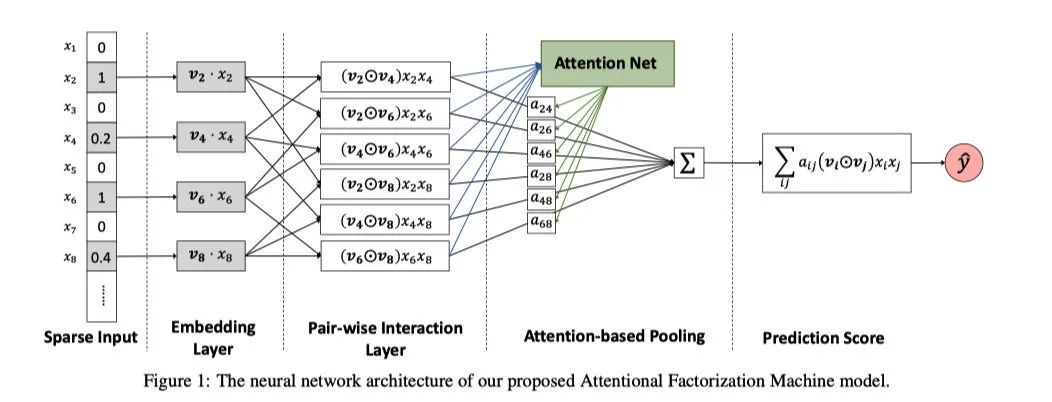
这里的Attention网络其实就是一个多层神经网络,它的表达式如下:
本质上就是我们增加了一个模块专门用来学习交叉项的权重,进行加权求和而已。
尾声
这两个模型的优化点都比较小,模型结构上基本上都沿用了FM,只是做出了一点改进和迭代,还没有完全利用起来神经网络的优势。
在下一篇文章当中我们将会介绍另外几个FM家族的演化版本,它们进一步利用了神经网络超强的泛化能力,整个模型的结果也有了比较大的提升和改动,甚至有些模型看起来已经不像是FM模型了,同样模型的效果也有了不小的飞跃。
好了,今天的文章就到这里,感谢阅读,喜欢的话不要忘了三连。