
小白都能懂的Mysql主从复制原理(原理+实操)
前一篇的Mysql面试还是非常给力的,非常的干货,有兴趣的可以看一下[MySQL 四万字精华总结 + 面试100 问,和面试官扯皮绰绰有余(收藏系列)],虽然不是我写的,但是内容确实是非常的干货,4万字解决你Mysql面试中存在的问题,好的文章还是要推荐给大家。
讲完了单机版的Mysql问题,来说一说集群,这不写了一篇Mysql主从的搭建,主要讲主从复制的原理,以及自己实践搭建主从,对于还没有接触主从的程序员,还是非常友好的,文章内容通俗易懂。
主从复制简介
在实际的生产中,为了解决Mysql的单点故障已经提高MySQL的整体服务性能,一般都会采用「主从复制」。
比如:在复杂的业务系统中,有一句sql执行后导致锁表,并且这条sql的的执行时间有比较长,那么此sql执行的期间导致服务不可用,这样就会严重影响用户的体验度。
主从复制中分为「主服务器(master)「和」从服务器(slave)」,「主服务器负责写,而从服务器负责读」,Mysql的主从复制的过程是一个「异步的过程」。
这样读写分离的过程能够是整体的服务性能提高,即使写操作时间比较长,也不影响读操作的进行。
主从复制的原理
首先放一张Mysql主从复制的原理图,总的来说Mysql的主从复制原理还是比较好理解的,原理非常的简单。
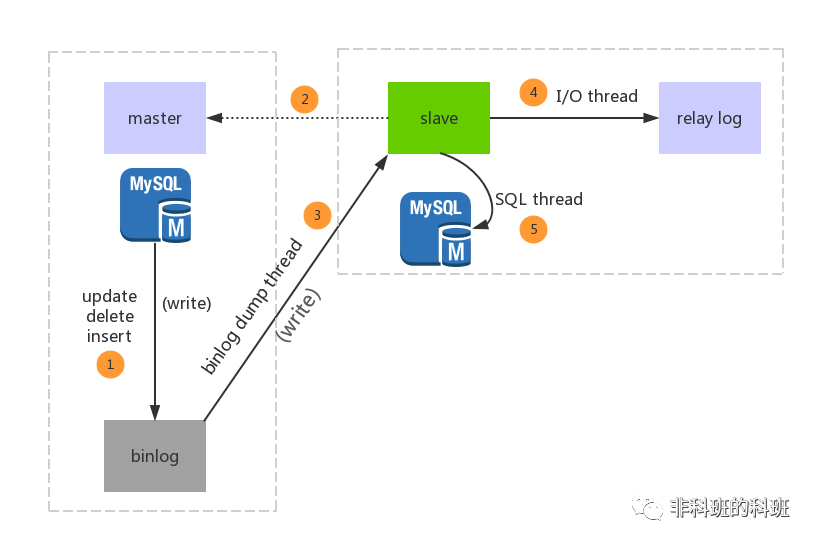
Mysql的主从复制中主要有三个线程:master(binlog dump thread)、slave(I/O thread 、SQL thread),Master一条线程和Slave中的两条线程。
master(binlog dump thread)主要负责Master库中有数据更新的时候,会按照binlog格式,将更新的事件类型写入到主库的binlog文件中。
并且,Master会创建log dump线程通知Slave主库中存在数据更新,这就是为什么主库的binlog日志一定要开启的原因。
I/O thread线程在Slave中创建,该线程用于请求Master,Master会返回binlog的名称以及当前数据更新的位置、binlog文件位置的副本。
然后,将binlog保存在 「relay log(中继日志)」 中,中继日志也是记录数据更新的信息。
SQL线程也是在Slave中创建的,当Slave检测到中继日志有更新,就会将更新的内容同步到Slave数据库中,这样就保证了主从的数据的同步。
以上就是主从复制的过程,当然,主从复制的过程有不同的策略方式进行数据的同步,主要包含以下几种:
「同步策略」:Master会等待所有的Slave都回应后才会提交,这个主从的同步的性能会严重的影响。 「半同步策略」:Master至少会等待一个Slave回应后提交。 「异步策略」:Master不用等待Slave回应就可以提交。 「延迟策略」:Slave要落后于Master指定的时间。
对于不同的业务需求,有不同的策略方案,但是一般都会采用最终一致性,不会要求强一致性,毕竟强一致性会严重影响性能。
主从搭建
下面我们就来实操搭建主从,使用的是两台centos7并且安装的是Mysql 8来搭建主从,有一台centos 7然后直接克隆就行了。
(1)首先检查centos 7里面的Mysql安装包和依赖包:
rpm -qa |grep mysql
执行后,在我本机上的显示如下:

(2)接着可以删除上面的安装包和依赖包:
sudo yum remove mysql*
(3)继续检查一下是否存在Mariadb,若是存在直接删除Mariadb
// 检查是否存在Mariadb
rpm -qa |grep mariadb
// 删除Mariadb
sudo rpm -e --nodeps mariadb-libs-5.5.56-2.el7.x86_64
(4)然后,就是删除Mysql的配置文件,可以使用下面的命令查找Msqyl配置文件的路径:
sudo find / -name mysql
在我本机上的显示的Mysql配置文件的路径如下:

(5)然后,通过下面的命令,将他们逐一删除:
sudo rm -rf /usr/lib64/mysql
......
(6)接着就开始安装Mysql 8了,使用wget命令下载Mysql 8的repo源,并且执行安装:
wget https://repo.mysql.com//mysql80-community-release-el7-3.noarch.rpm
sudo yum -y install mysql80-community-release-el7-3.noarch.rpm
安装完后会在/etc/yum.repos.d/目录下生成下面的两个文件,说明安装成功了:
mysql-community.repo
mysql-community-source.repo

(7)安装完Mysql8后,接着来更新一下yum源,并且查看yum仓库中的Mysql:
// 更新yum源
yum clean all
yum makecache
// 查看yum仓库中的Mysql
yum list | grep mysql
(8)可以查看到仓库中存在mysql-community-server.x86_64,直接安装就行了:
sudo yum -y install mysql-community-server
(9)接着启动Mysql,并检查Mysql的状态:
// 启动Mysql
systemctl start mysqld.service
// 检查Mysql的状态
systemctl status mysqld
确保查看Mysql的状态是active(running),表示正在运行,并且配置一下Mysql开机启动:
systemctl enable mysqld
(10)因为Mysql是新安装的,所以要修改一下初始密码,先查看一下初始密码:
grep "password" /var/log/mysqld.log
你可能找出来有多个,可能是你之前安装卸载后的文件没有删干净,这里你就直接看时间,时间对应你现在的时间,就是你的初始密码:

(11)然后使用初始密码,登陆数据库,并且修改密码:
mysql -uroot -p
ALTER USER 'root'@'localhost' IDENTIFIED BY 'LDCldc@123095;
(12)此时在创建一个可以用于给两一台centos连接的用户,默认的root用户只有本机才能连接:
// 创建连接用户
create user 'test'@'%' identified by 'LDCldc-2020';
// 并且把防火墙给关了,或者配置一下3306端口
systemctl stop firewalld.service;
// 设置防火墙开机自动关闭
systemctl disable firewalld.service;
(13)测试:到这里就Mysql的安装教程就就讲完了,可以测试一下,两台centos是否可以ping通:
ping 192.168.163.156

我这里的两台机是可以互通的,Master:192.168.163.156,Slave:192.168.163.155,并且Slave使用下面的命令可以登陆到Master的Mysql:
mysql -u[user] -p[密码] -h[远程主机ip]
确保了这两项测试成功后,就可以进行下面的主从搭建了。
(14)我这里使用的使用两台centos 7的vmware的ip分别是192.168.163.155(Slave)和192.168.163.156(Master)作为测试,首先在192.168.163.156(Master)中创建一个测试库test:
// 创建测试库
create database test default character set utf8mb4 collate utf8mb4_general_ci;
// 并且授权
grant all privileges on test.* to 'test'@'%';
(15)然后编辑Master中的my.cnf文件,此文件位于/etc/my.cnf,执行下面的sql,并添加下面的信息:
sudo vi /etc/my.cnf
==========以下是配置文件中的信息=============
# 配置编码为utf8
character_set_server=utf8mb4
init_connect='SET NAMES utf8mb4'
# 配置要给Slave同步的数据库
binlog-do-db=test
# 不用给Slave同步的数据库,一般是Mysql自带的数据库就不用给Slave同步了
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
binlog-ignore-db=performance_schema
binlog-ignore-db=sys
# 自动清理30天前的log文件
expire_logs_days=30
# 启用二进制日志
log-bin=mysql-bin
# Master的id,这个要唯一,唯一是值,在主从中唯一
server-id=3
(16)配置完后重启Mysql服务,并查看Mysql的log_bin日志是否启动成功:
systemctl restart mysqld
# 查看log_bin日志是否启动成功
show variables like '%log_bin%';

(17)接着查看Master的状态:
show master status;

这两个数据File和Position要记住,后面配置Slave的时候要使用到这两个数据。
(18)最后登陆Master的数据库,并创建一个用户用于同步数据:
create user 'backup'@'%' IDENTIFIED BY 'LDCldc-2020';
grant file on *.* to 'backup'@'%';
GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* to 'backup'@'%';
到这里Master的配置就配置完了,后面就进行Slave的配置。
(19)在Slave中同样要创建test数据库,并且授权给test用户:
# 创建同步数据的test数据库
create database test default character set utf8mb4 collate utf8mb4_general_ci;
# 授权
grant all privileges on test.* to 'test'@'%';
(20)接着编辑Slave中my.cnf文件,同样是在/etc/my.cnf路径下,加入如下配置:
# 配置从服务器的ID,唯一的
server-id=4
#加上以下参数可以避免更新不及时,SLAVE 重启后导致的主从复制出错。
read_only = 1
master_info_repository=TABLE
relay_log_info_repository=TABLE
(21)并且重启Slave中的Mysql服务:
systemctl restart mysqld
(22)在Slave中添加Master的信息:
# master_host是Master的ip,master_log_file和master_log_pos就是配置之前查看Master状态时显示的File和Position信息
change master to master_host='192.168.163.156',master_port=3306,master_user='backup',master_password='LDCldc-2020',master_log_file='mysql-bin.000001',master_log_pos=1513;
(23)最后查看Slave的状态:
show slave status\G
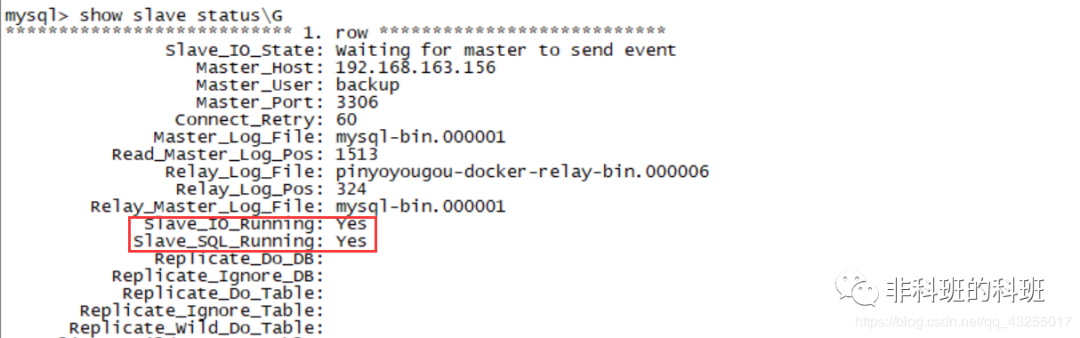
当看到Slave_IO_Running和Slave_SQL_Running都是yes的时候,这表示主从配置成功。
「Slave_IO_Running也就是Slave中的IO线程用于请求Master,Slave_SQL_Running时sql线程将中继日志中更新日志同步到Slave数据库中。」
但是,有时候Slave_IO_Running会为no,而Slave_SQL_Running为yes,这时候需要检查一下原因,因为我自己初次搭建的时候,也是出现这个问题。
首先看重启一下Slave的MySQL服务:systemctl restart mysqld,然后执行:
stop slave;
start slave;
这样就能够使Slave_IO_Running和Slave_SQL_Running显示都是yes了。
(24)最后就是测试了,测试使用的是之前创建的test库,Master是用来写的,在Master的test库中随机创建一个表,你会发现Slave也会有这个表,插入数据也一样,都会被同步到Slave中。
主从面试
❝Mysql主从有什么优点?为什么要选择主从?
❞
高性能方面:主从复制通过水平扩展的方式,解决了原来单点故障的问题,并且原来的并发都集中到了一台Mysql服务器中,现在将单点负载分散到了多台机器上,实现读写分离,不会因为写操作过长锁表而导致读服务不能进行的问题,提高了服务器的整体性能。 可靠性方面:主从在对外提供服务的时候,若是主库挂了,会有通过主从切换,选择其中的一台Slave作为Master;若是Slave挂了,还有其它的Slave提供读服务,提高了系统的可靠性和稳定性。
❝若是主从复制,达到了写性能的瓶颈,你是怎么解决的呢?
❞
主从模式对于写少读多的场景确实非常大的优势,但是总会写操作达到瓶颈的时候,导致性能提不上去。
这时候可以在设计上进行解决采用分库分表的形式,对于业务数据比较大的数据库可以采用分表,使得数据表的存储的数据量达到一个合理的状态。
也可以采用分库,按照业务进行划分,这样对于单点的写,就会分成多点的写,性能方面也就会大大提高。
❝主从复制的过程有数据延迟怎么办?导致Slave被读取到的数据并不是最新数据。
❞
主从复制有不同的复制策略,对于不同的场景的适应性也不同,对于数据的实时性要求很高,要求强一致性,可以采用同步复制策略,但是这样就会性能就会大打折扣。
若是主从复制采用异步复制,要求数据最终一致性,性能方面也会好很多。只能说,对于数据延迟的解决方案没有最好的方案,就看你的业务场景中哪种方案使比较适合的。
— 【 THE END 】— 本公众号全部博文已整理成一个目录,请在公众号里回复「m」获取! 3T技术资源大放送!包括但不限于:Java、C/C++,Linux,Python,大数据,人工智能等等。在公众号内回复「1024」,即可免费获取!!