
小白都能看懂的缓存入门
缓存是程序员必须了解的技术,无论是前端、后端还是客户端,大到复杂的系统架构,小到 CPU 或是芯片,都少不了缓存的影子。
下面只需 5 分钟,带你入门缓存技术。
什么是缓存?
缓存(Cache)本意是指可以进行高速数据交换的存储器,通俗点来说,就是通过将数据提前存放到内存,以提高访问速度。
在我们设计程序或算法时,有两个基本指标,即时间复杂度和空间复杂度。有时,我们的程序无法同时满足二者,就只能以时间换空间,或者以空间换时间。缓存是以空间换时间思想的典型应用,牺牲一部分内存空间,能够得到数百倍的读取性能提升。
缓存最常见的数据结构是键值对(Key/Value),类似字典,即一个 Key 对应一个 Value,访问缓存时通过 Key 获取 Value。

为什么需要缓存?
最简单的后端系统只需要一个应用服务(比如 Tomcat)和持久化存储数据的数据库(如 MySQL),对于一个访问量很小的系统来说,这样的架构就足够了。


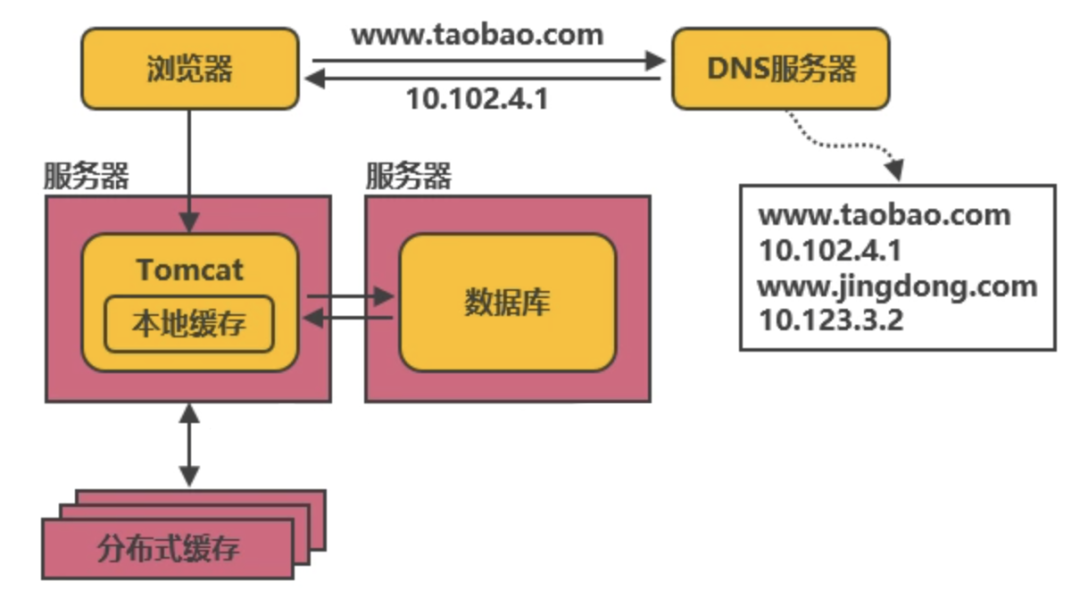
缓存类别
本地缓存
class LocalCache {private static Map<String, Object> cache = new HashMap<>();private LocalCache() {}public static void put(String key, Object value) {cache.put(key, value);}public static Object get(String key) {return cache.get(key);}}
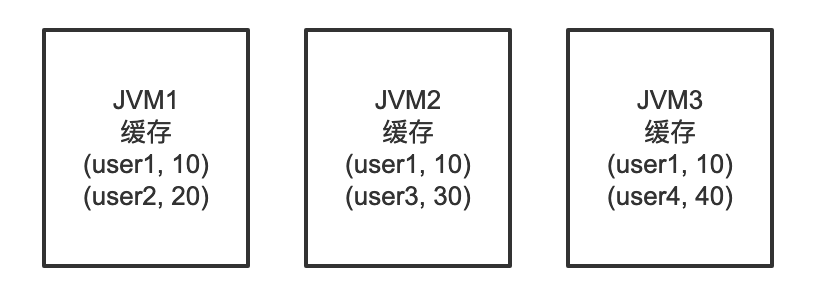
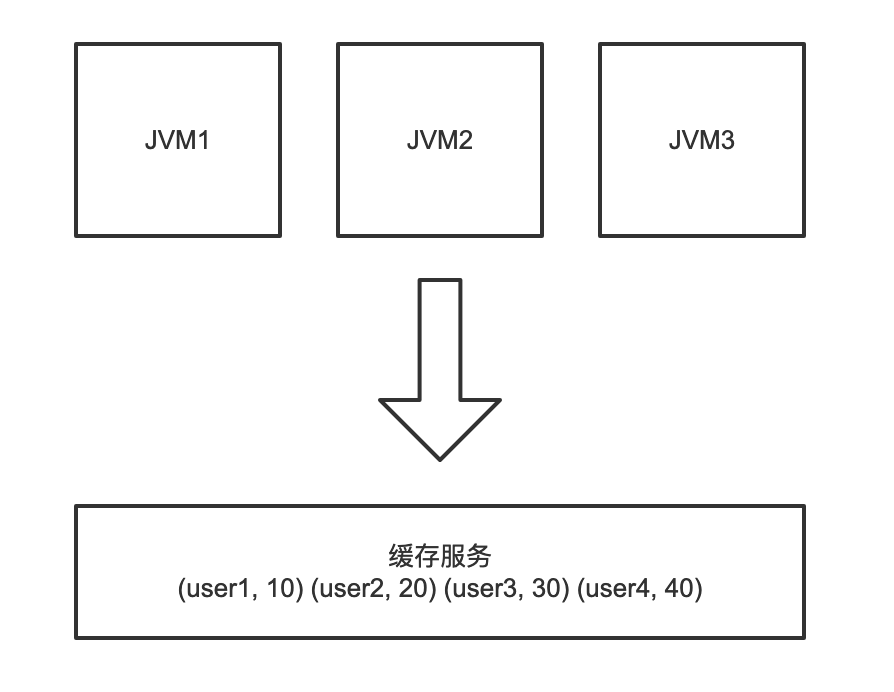
分布式缓存
多级缓存

缓存淘汰策略
LRU 最近最少使用
近似 LRU 算法
TTL 超时时间
LFU 最少使用
FIFO 先进先出

Second-Chance
Random 随机
缓存实现
Caffeine
Guava Cache
Ehcache
Memcached
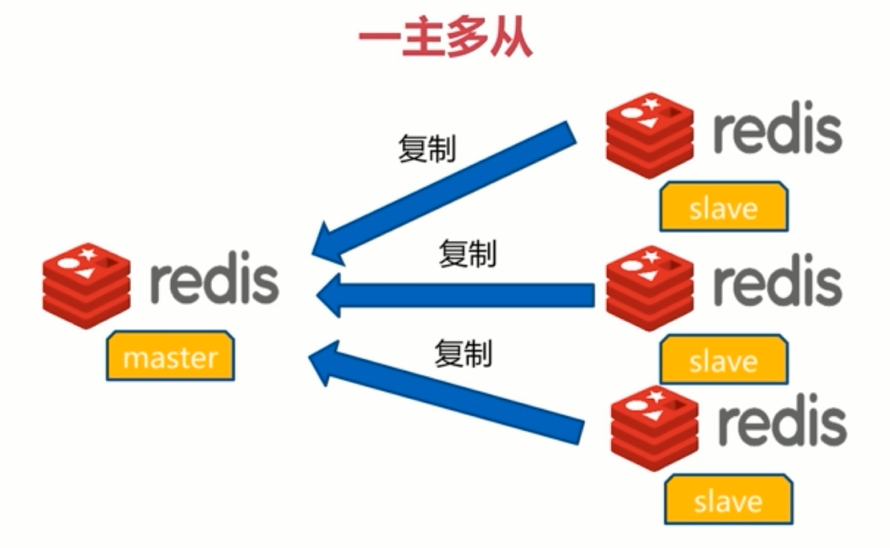
Redis
Spring Cache
没有银弹

评论