
原创 | 一文读懂Transformer

作者:陈之炎 本文约3500字,建议阅读7分钟
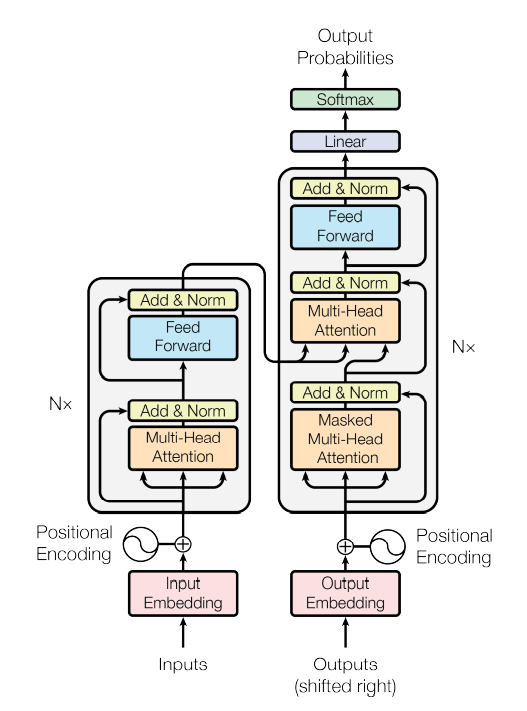
Transformer 是第一个完全依赖于自注意力机制来计算其输入和输出的表示的转换模型。
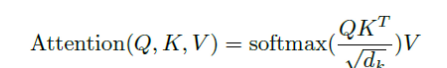
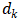 ,计算所有K向量和Q向量的点积,分别除以
,计算所有K向量和Q向量的点积,分别除以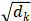 ,并应用一个Softmax函数来获得这些值的权重。实际上在self-Attention中,
,并应用一个Softmax函数来获得这些值的权重。实际上在self-Attention中,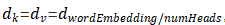 ,为了方便将Attention的计算转化为矩阵运算,论文中采用了点积的形式求相似度。常见的计算方法除了点积还有MLP网络,但是点积能转化为矩阵运算,计算速度更快。的缩放因子外,带缩放的点积注意力机制采用的是点积注意力函数,加注意力函数使用具有单个隐含层的前馈网络来计算兼容性函数。虽然这两者在理论复杂度上相似,但点积注意力函数更快,更节省空间,因为它可以使用高度优化的矩阵乘法码来实现。而对于较小的值,这两种机制的性能相似,但在不加大更大的值的情况下,加注意力函数优于点积注意力函数。对于较大的值,点积相应变大,将Softmax函数推到梯度极小的区域。为了抵消这种影响,我们通过来缩放点积。
,为了方便将Attention的计算转化为矩阵运算,论文中采用了点积的形式求相似度。常见的计算方法除了点积还有MLP网络,但是点积能转化为矩阵运算,计算速度更快。的缩放因子外,带缩放的点积注意力机制采用的是点积注意力函数,加注意力函数使用具有单个隐含层的前馈网络来计算兼容性函数。虽然这两者在理论复杂度上相似,但点积注意力函数更快,更节省空间,因为它可以使用高度优化的矩阵乘法码来实现。而对于较小的值,这两种机制的性能相似,但在不加大更大的值的情况下,加注意力函数优于点积注意力函数。对于较大的值,点积相应变大,将Softmax函数推到梯度极小的区域。为了抵消这种影响,我们通过来缩放点积。在编码器-解码器注意力层,Q值来自上一个解码器层,K值和V值来自编码器的输出,从而使得解码器的每一个位置信息均和输入序列的位置信息相关,这种架构模仿了序列到序列模型编解码器注意力机制。 编码器中包括自注意力层,在自注意力层中,Q 值、K值和V值均来自编码器上一层的输出,编码器中的位置信息参与到前一层的位置编码中去。 同理,解码器中的自注意力机制使得解码器中的位置信息均参与到所有位置信息的解码中去。
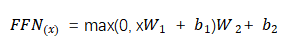
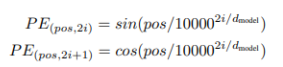
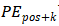 可以表示为
可以表示为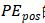 的线性函数。
的线性函数。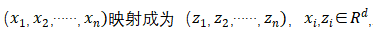 从三个因素来考量采用自注意力机制:首先是每一层计算的复杂程度;其次,是可以并行计算的计算量,用对序列操作的最小数目表示;第三,是网络中最长相关路径的长度。在序列学习任务中,对长序列相关性的学习是关键性的难点问题,前向和后向信号路径的长度往往是影响学习效率的关键因素,输入和输出序列之间的位置越短,前向和后向信号路径则越短,更容易学习到长序列的依赖关系,通过对比网络中输入输出序列位置的最长通路路径,来回答为什么采用自注意力机制来搭建Transformer模型。
从三个因素来考量采用自注意力机制:首先是每一层计算的复杂程度;其次,是可以并行计算的计算量,用对序列操作的最小数目表示;第三,是网络中最长相关路径的长度。在序列学习任务中,对长序列相关性的学习是关键性的难点问题,前向和后向信号路径的长度往往是影响学习效率的关键因素,输入和输出序列之间的位置越短,前向和后向信号路径则越短,更容易学习到长序列的依赖关系,通过对比网络中输入输出序列位置的最长通路路径,来回答为什么采用自注意力机制来搭建Transformer模型。 表 3-1 不同层序列操作的的最大路径长度、每层的复杂性和最小操作数
表 3-1 不同层序列操作的的最大路径长度、每层的复杂性和最小操作数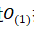 操作将序列的位置信息关联起来,而RNN则需要对序列进行
操作将序列的位置信息关联起来,而RNN则需要对序列进行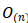 次操作。从计算的复杂程度来看,当序列长度n小于表示向量的维度d 时,在机器翻译任务中性能能达到最优。为了提高超长输入序列的计算性能,限制自注意力中的邻域r的大小,从而会使得最长相关路径的长度变为
次操作。从计算的复杂程度来看,当序列长度n小于表示向量的维度d 时,在机器翻译任务中性能能达到最优。为了提高超长输入序列的计算性能,限制自注意力中的邻域r的大小,从而会使得最长相关路径的长度变为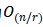 。
。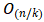 层卷积层堆叠,使得最长相关路径的长度变长。通常,CNN的训练成本比RNN的训练成本要高。
层卷积层堆叠,使得最长相关路径的长度变长。通常,CNN的训练成本比RNN的训练成本要高。4.1训练数据和批次大小
4.2 硬件配置
4.3 优化器
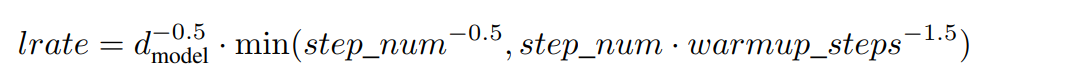
4.4 正则化
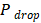 = 0.1。
= 0.1。4.5 训练结果
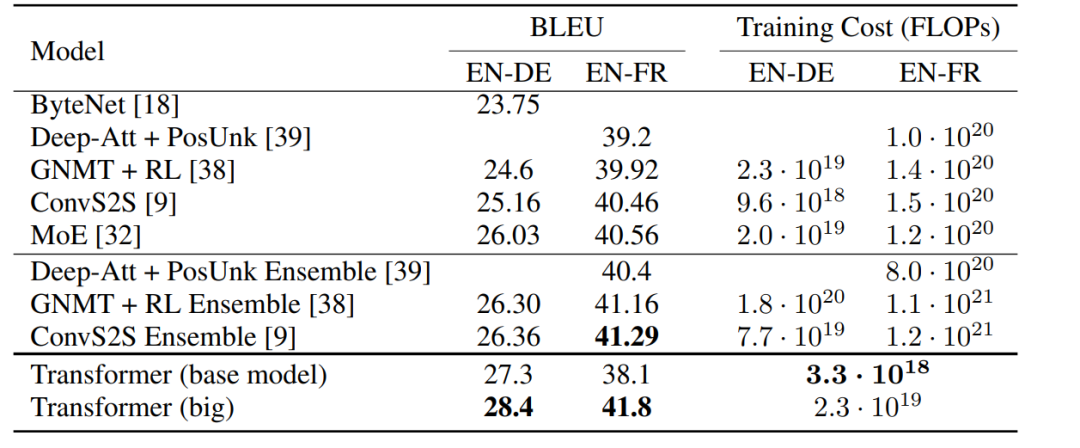
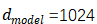 的4层Transformer。此外,还在半监督设置下训练它,使用更大的高置信度和伯克利解析器语料库,大约1700万语句。对《华尔街日报》的设置使用了16K标记词汇,对半监督的设置使用了32K标记词汇。
的4层Transformer。此外,还在半监督设置下训练它,使用更大的高置信度和伯克利解析器语料库,大约1700万语句。对《华尔街日报》的设置使用了16K标记词汇,对半监督的设置使用了32K标记词汇。作者简介
陈之炎,北京交通大学通信与控制工程专业毕业,获得工学硕士学位,历任长城计算机软件与系统公司工程师,大唐微电子公司工程师。目前从事智能化翻译教学系统的运营和维护,在人工智能深度学习和自然语言处理(NLP)方面积累有一定的经验。
编辑:于腾凯
校对:林亦霖
数据派研究部介绍
数据派研究部成立于2017年初,以兴趣为核心划分多个组别,各组既遵循研究部整体的知识分享和实践项目规划,又各具特色:
算法模型组:积极组队参加kaggle等比赛,原创手把手教系列文章;
调研分析组:通过专访等方式调研大数据的应用,探索数据产品之美;
系统平台组:追踪大数据&人工智能系统平台技术前沿,对话专家;
自然语言处理组:重于实践,积极参加比赛及策划各类文本分析项目;
制造业大数据组:秉工业强国之梦,产学研政结合,挖掘数据价值;
数据可视化组:将信息与艺术融合,探索数据之美,学用可视化讲故事;
网络爬虫组:爬取网络信息,配合其他各组开发创意项目。
点击文末“阅读原文”,报名数据派研究部志愿者,总有一组适合你~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派THUID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
未经许可的转载以及改编者,我们将依法追究其法律责任。
点击“阅读原文”加入组织~
评论