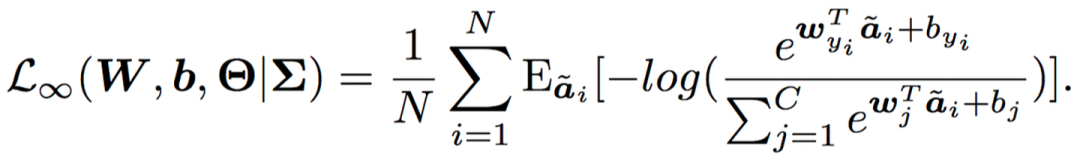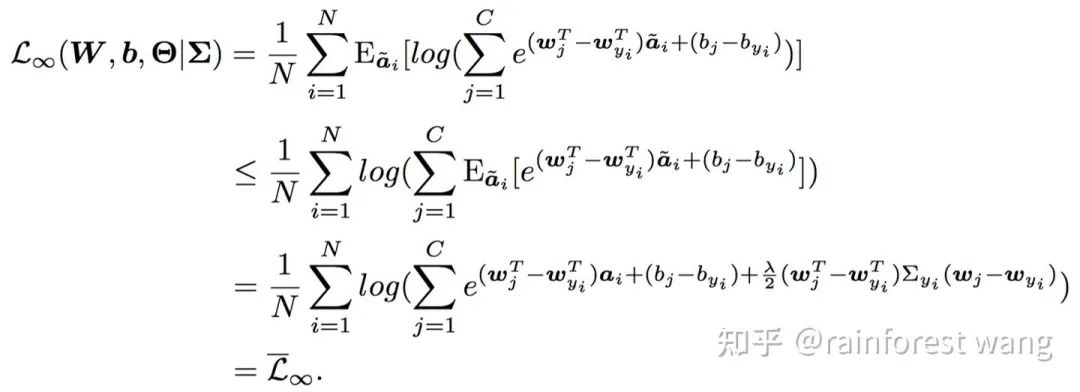点击上方,选择星标 或置顶 ,不定期资源大放送 !
阅读大概需要15分钟
Follow小博主,每天更新前沿干货
本文主要介绍刚刚被IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI)录用的一篇文章:Regularizing Deep Networks with Semantic Data Augmentation。
期刊论文: https://arxiv.org/abs/2007.10538
其会议版本发表在NeurIPS 2019:
会议论文 :https://arxiv.org/abs/1909.12220
代码和预训练模型已开源 :
https://github.com/blackfeather-wang/ISDA-for-Deep-Networks
知乎链接:
https://zhuanlan.zhihu.com/p/344953635
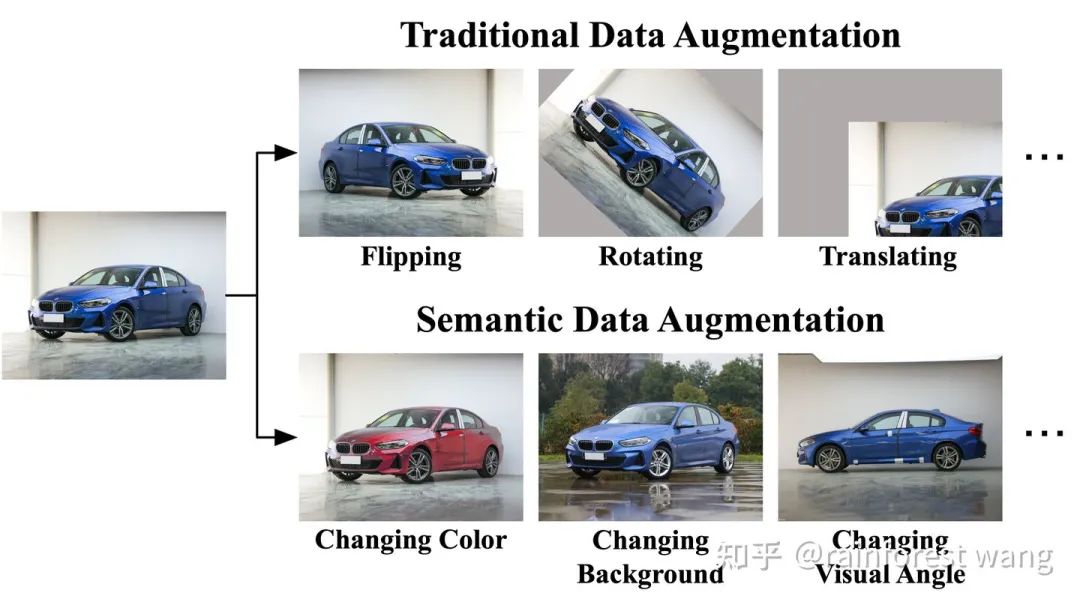
在计算机视觉任务中,数据扩增是一种基于较少数据、产生大量训练样本,进而提升模型性能的有效方法。传统数据扩增方法主要借助于图像域的翻转、平移、旋转等简单变换,如图1中第一行所示。
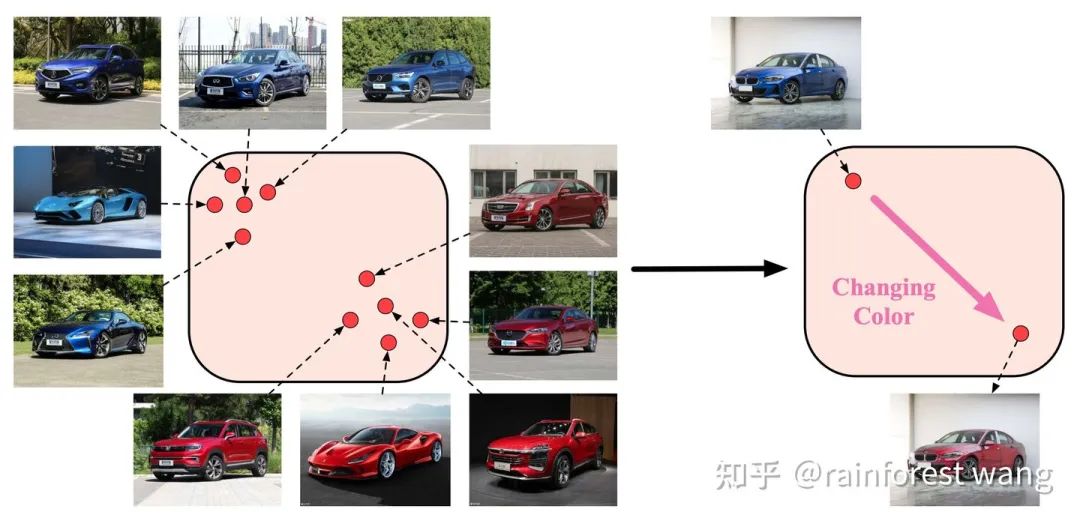
我们的工作则提出了一种隐式语义数据扩增算法:ISDA,意在实现对样本进行更为「高级」的、「语义」层面的变换,例如改变物体的背景、颜色、视角等,如图1中第二行所示,注意这些变换并不改变任务标签。
具体而言,ISDA具有几个重要的特点:
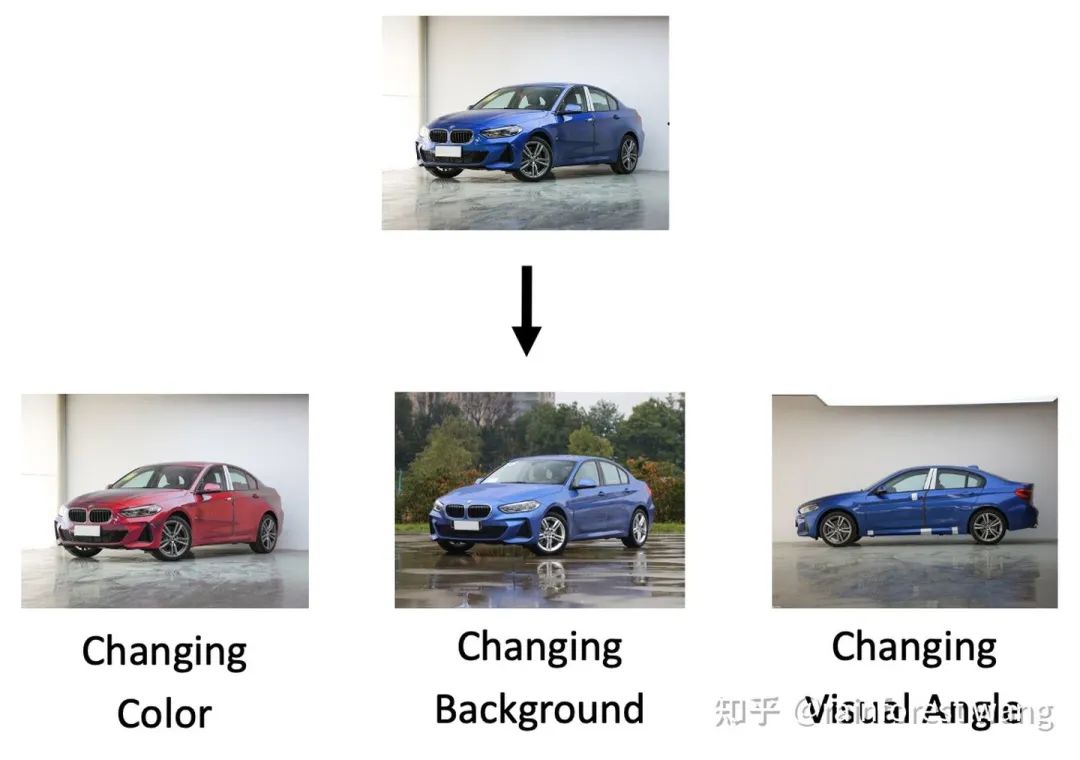
与传统数据扩增方法高度互补,有效地增进扩增多样性和进一步提升性能 巧妙地利用深度神经网络长于学习线性化表征的性质,在特征空间完成扩增过程,无需训练任何辅助生成模型(如GAN等),几乎不引入任何额外计算或时间开销 直接优化无穷扩增样本期望损失的一个上界,最终形式仅为一个全新的损失函数,简单易用,便于实现 可以广泛应用于全监督、半监督图像识别、语义分割等视觉任务,在ImageNet、Cityscapes等较大规模的数据集上效果比较明显 数据扩增是一种非常有效的提升深度学习模型泛化性能的方法,一般而言,我们会在输入空间进行一些特定的变换,以基于有限的数据产生大量的样本用于训练,如图2中对汽车图像进行旋转、左右翻转、放缩、裁剪等。 其效果往往非常显著,例如,在图2右侧柱状图中,我们展示了在相同的实验设置(优化器、训练时长等)下,在 CIFAR 图像识别数据集上,是否进行数据扩增所导致的性能差异。 在 CIFAR-10 数据集上,测试误差从 13.6% 降至 6.4%;在 CIFAR-100 数据集上,测试误差从 44% 降至 27%。 本质上,数据扩增的效果来源于促进模型对于我们定义的这些变换的不变性。然而,从生物体的角度出发,视觉的不变性并不仅限于简单的几何变换,而是更多地体现在更为高级的语义层面。 例如在图3中,当我们改变汽车的颜色、视角和背景时,我们仍然可以辨识出,这是一辆汽车。 这就启发我们:能不能将这些不改变类别主体的语义变换引入到数据扩增中? 图3:语义数据扩增简介
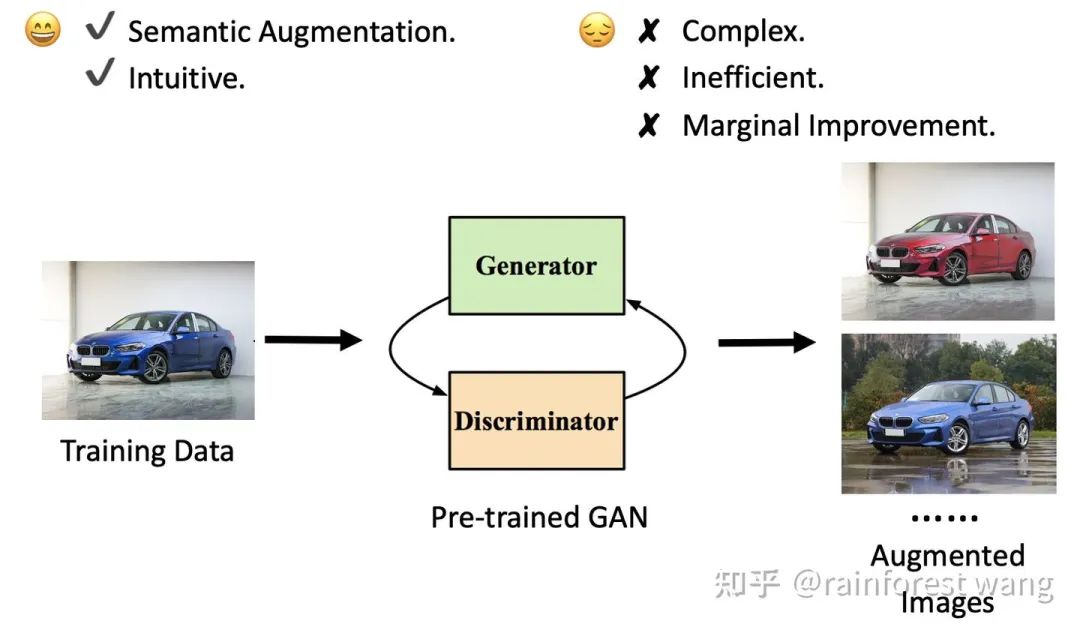
显然,一个最简单的方法就是在数据集上训练一个或多个生成模型,如GAN,去捕捉不同类别的语义分布,再从中得到大量扩增后的样本,但这样做有几个明显的弊端: (1)这一方法比较复杂,训练GAN需要设计特定的模型和配套算法,实现起来比较困难; (2)时间和计算开销较大,一方面,训练GAN需要消耗大量额外的时间和计算资源,另一方面,将GAN应用于产生扩增样本将引入额外的推理开销,并可能减慢主要模型的训练; (3)根据我们的实验结果,这一方法效果比较有限(关于这一点的详情,请参见我们的paper, 简而言之,GAN的训练同样依赖于比较多的数据,于是有一个悖论:数据少->GAN难以训练->扩增效果不好;数据多->虽然GAN可以训练好->但是与直接用这些数据训练模型相比,GAN难以提供超出数据集范畴的信息,效果有限)。 事实上,我们可以借助卷积神经网络的一个非常有趣的性质:之前的研究工作证明,由于我们往往用线性分类器约束网络的输出,深度网络的特征空间往往是线性化的,输入空间中不同样本之间复杂的语义关系倾向于表现为其对应深度特征之间的简单空间线性关系。 换言之,深度特征空间中的一些方向是对应于特定语义变换的。以Deep Feature Interpolation为例(图5),若我们任意收集一定数量蓝色汽车和红色汽车的图片,取得前者深度特征均值指向后者深度特征均值的向量,则这一向量就代表了“将汽车的颜色由蓝色变为红色”这一语义变换。 对于任意一张全新的蓝色汽车图片,我们将其深度特征沿这一方向平移后,就可以得到将这辆汽车的颜色换为红色后,所得图片对应的深度特征(这一方法的合理性证明自,此特征可以以特定方式映射回图像空间)。 图5:借助深度特征空间的图像语义变换 —— Deep Feature Interpolation 我们的工作受到了这一现象的启发,在深度特征空间中,我们为训练样本寻找改变颜色、视角、动作和背景等不影响类别标签的语义变换所对应的方向,通过将训练数据的深度特征在这些方向上平移,低成本地实现多样化的语义数据扩增,以弥补传统扩增方法在语义不变性上的不足。
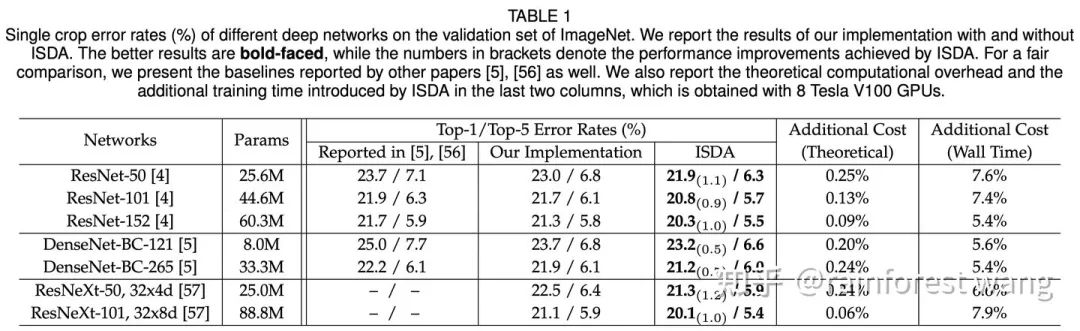
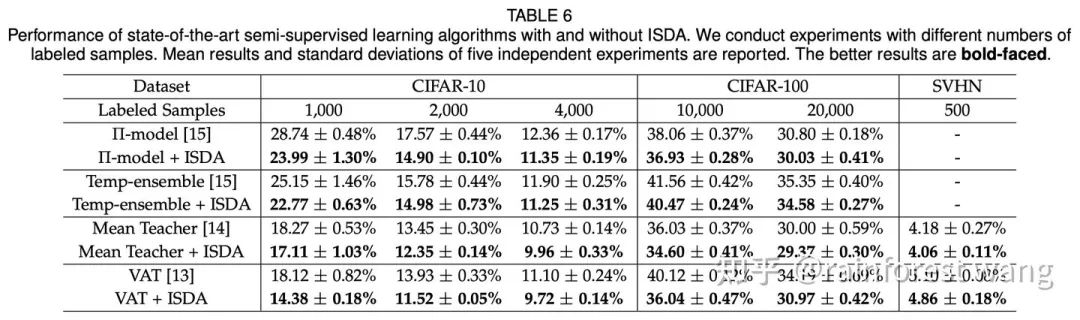
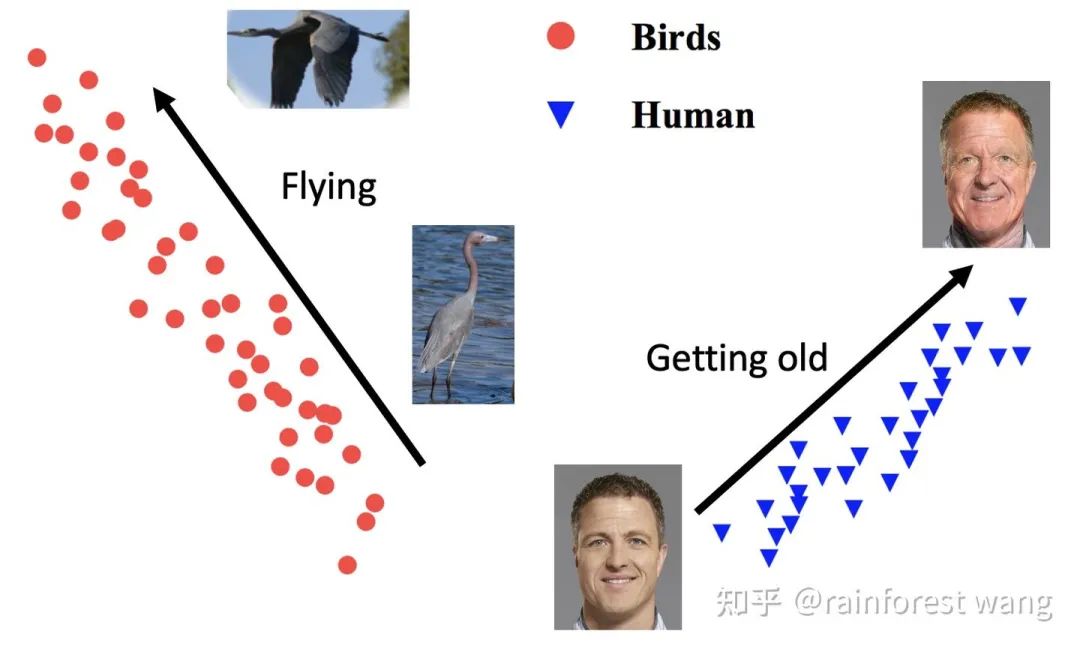
为了实现前文所述的目标,一个显而易见的问题是:如何在深度特征空间中寻找这些“有意义的语义方向”? Deep Feature Interpolation中所采用的的方法是人工收集对应于具体变换的特定数据,再对语义方向进行标注。 其一,对于每一类别甚至每一样本,可行的语义方向都是有所不同的,对每一变换人工收集数据成本巨大; 其二,可能的语义变换数量极多,通过预先定义、人工寻找的方只能找到非常有限的少数方向。 为了解决这两点不足,一个可能的选择是:通过随机采样得到扩增所需的语义方向。 这样一方面节省了人工标注的开销,另一方面可以保证语义方向的在特征空间中连续分布,发现更多潜在的语义方向,从而提升扩增的多样性。 但如此一来,采样的方式就变得尤为重要,考虑到特征空间维度极高(例如ResNet-50在ImageNet上产生2048维的特征空间,即便以二值化的假设近似,可能的取值也有 种)。 若完全随机采样,得到的语义方向极有可能是没有任何意义的,如图6所示,将汽车的图片沿“飞翔”或是“变老”的方向平移是完全没有意义的。 那么,如何设计合适的采样方法呢?我们的工作巧妙地利用了已有的训练数据。具体而言,每一类别的样本都是有其类内特征分布的,实际上这种数据分布隐含了这类数据可能变化的方向。 为了说明这一点,我们首先考虑下面这一个例子(图7)。“鸟”这一类的样本在“飞翔”这一方向上具有较大的方差,因为训练数据中同时包含“飞翔”和“不飞翔”的鸟,相对而言,其在“变老”这一方向上方差几乎为0,因为数据中不可能存在“老”或“年轻”的鸟。 同理,数据中存在“老”或“年轻”的人,而不存在“飞翔”的人,因此“人”这一类的样本在“变老”这一方向上应当有较大的方差,在“飞翔”这一方向上方差几乎为0。 总而言之,在多维空间中,我们可以利用类内特征分布刻画某类图像可能在哪些方向上有语义的变化。 出于这一点,我们通过统计每一类别的类内协方差矩阵,为每一类别构建了一个零均值的高斯分布,进而从中采样出有意义的语义变换方向,用于各自类别内的数据扩增,以此来近似手工标注的过程,以取得正确性、高效性、多样性的良好权衡。 其示意图如图8所示,关于具体的技术细节(例如协方差估计方法),请参阅我们的paper。 在数学上讲,给定第 个样本对应的深度特征 ,其扩增后的形式应当是一个以 为均值的正态分布随机变量 : 其中 为一常数。给定这一形式后,一个来源于传统数据扩增的自然思路是从随机变量 的分布中采样 次,优化其平均损失: 其中 为样本数目, 为 对应的标签, 为网络最后一线性分类层的参数, 为类别数目, 为网络参数。 但事实上, 较大、样本数目较多、特征空间维度较高时,采样 次并计算损失所引入的额外训练开销同样是不容小视的。 因此,我们考虑采样无穷次,即 的情况: 此时,我们实质上得到了在扩增分布上的期望损失。对于传统数据扩增方法而言,这一期望损失是难以计算的。 但是,由于我们的扩增操作是在特征空间完成的,在数学上,我们可以方便的对上式进行处理。 通过利用 Jensen 不等式,我们可以得到其一个易于计算的上界: 通过将这一上界作为我们的实际优化目标,我们得到了一个简单易行且高效的语义数据扩增算法,如下所示: 我们的算法被称为Implicit Semantic Data Augmentation(ISDA,隐式语义数据扩增) ,其最有趣的一点是,我们从语义数据扩增的角度出发,得到的算法最终却可以归化为一个全新的损失函数。 除标准的图像识别外,本算法也可应用于任何使用Soft-Max交叉熵损失的视觉任务,例如图像分割等。 事实上,除了上述介绍的基本的监督学习情境外,ISDA也可以在一致性正则(consistency regularization)的思路下拓展至半监督学习,其最终算法同样体现为一个全新的损失函数(期望KL散度的一个上界),且同样可以与现有方法实现很好的互补。关于这一点的细节,由于空间所限不在此赘述,请参阅我们的paper~ ImageNet 图像识别,在ResNet系列网络上的提升效果普遍在1%左右 与效果较佳的传统数据扩增方法有效互补 (RA、AA分别代表RandAugment[4]和AutoAugment) 图11:与 state-of-the-art 的传统数据扩增方法有效互补 Cityscapes 语义分割,可以在PSPNet[6]和DeepLab-V3[7]的基础上将mIOU提升1%以上
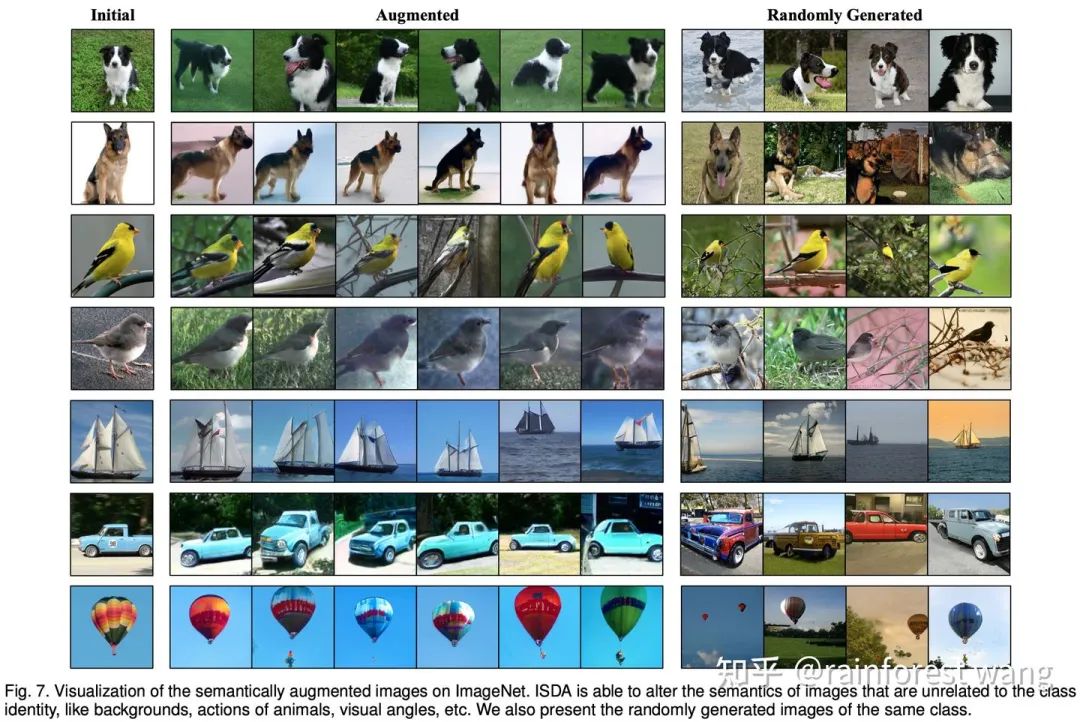
为了证实我们的确实现了语义数据扩增,我们利用BigGAN[8]在ImageNet上进行了可视化实验,其结果如下图所示。 其中 Augmented 中的图片为ISDA扩增的结果,Randomly Generated 中的图片为BigGAN随机生成的图片。 可以看到,ISDA所改变的语义包括狗的动作、鸟的背景、帆船的远近及位置、车的视角、热气球的颜色等,并不改变类别标签,且可以显著地看出,这些扩增得到的样本分布与原图片更为接近,而与类内随机样本差距较大。
最后总结一下,在我个人看来,这项工作的主要价值在于其为数据扩增算法的设计带来了三个启发性的思路:
(1)关注语义层面的数据扩增;
(2)利用特征空间的性质,对深度特征进行数据扩增;
(3)从期望损失的形式出发,向大家展示了数据扩增不一定是随机化的方法,亦可以体现为一个确定的形式,例如损失函数。
@inproceedings{NIPS2019_9426,

 !
!

 种)。
种)。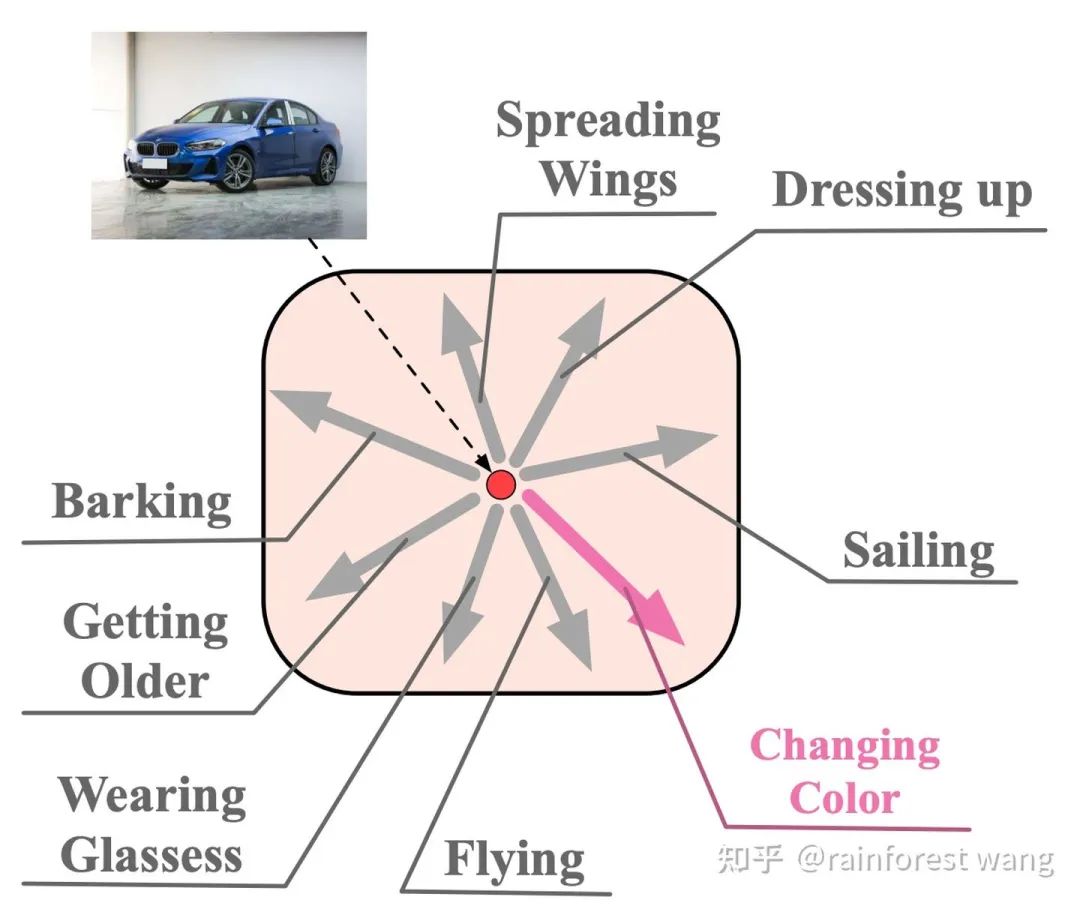

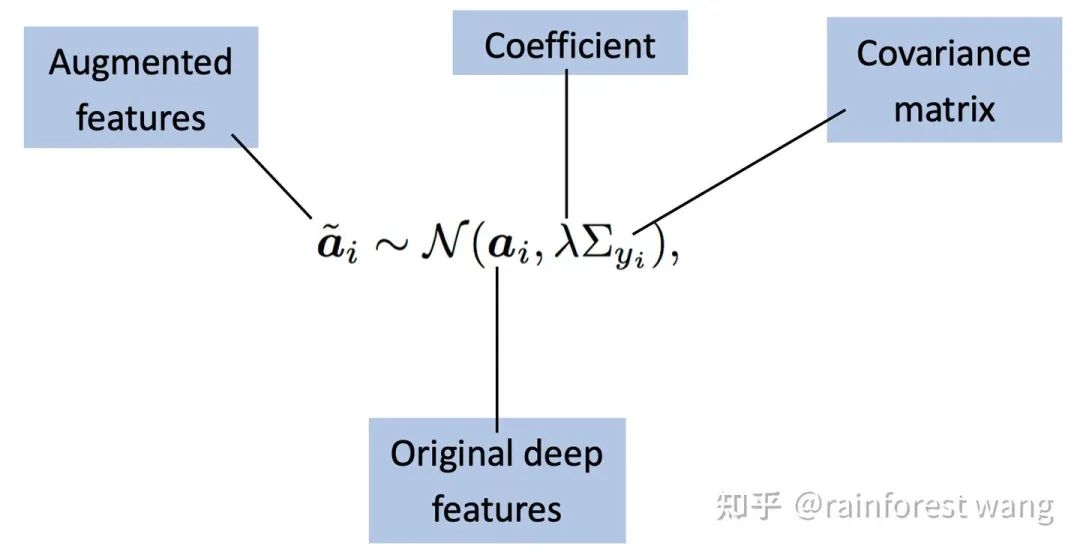
 个样本对应的深度特征
个样本对应的深度特征  ,其扩增后的形式应当是一个以
,其扩增后的形式应当是一个以 :
:
 为一常数。给定这一形式后,一个来源于传统数据扩增的自然思路是从随机变量
为一常数。给定这一形式后,一个来源于传统数据扩增的自然思路是从随机变量 次,优化其平均损失:
次,优化其平均损失: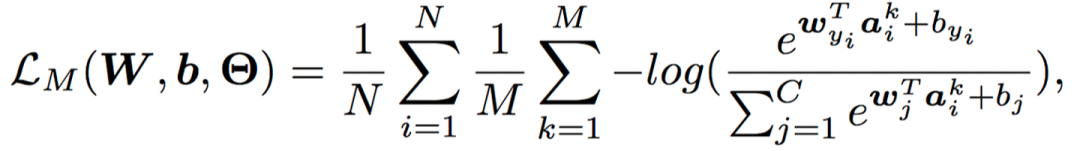
 为样本数目,
为样本数目, 为
为  为网络最后一线性分类层的参数,
为网络最后一线性分类层的参数, 为类别数目,
为类别数目, 为网络参数。
为网络参数。 的情况:
的情况: