
Auto Seg-Loss: 自动损失函数设计

极市导读
本文所提出的Auto Seg-Loss的设计目的在于降低为了某个给定的指标(比如边缘部分的IoU或者F-score)设计和调整损失函数时的试错成本,并向自动损失函数设计更进一步。>>极市福利赠书活动:机器学习“蜥蜴书”最新版来了!豆瓣评分9.9!
前段时间,有一则新闻比较火:
全国游泳冠军赛引发争议,傅园慧等五位预赛排名第一的名将因体能测试分数低而无缘决赛
体能水平可以反映竞技水平吗?对于普通人来说,体能水平和单项的比赛能力大多存在正相关关系。然而,高水平运动员需要的是对特定项目的针对性训练,更高的体能水平并不意味着更好的成绩,比如对于某些项目(如长跑)来说,上肢过于强壮反而是负担。因此,许多高水平运动员即使在专项上打破了亚洲记录,面对体能测试也败下阵来。反过来考虑,如果一个运动员日常只以体能测试的项目作为自己的训练目标,最终长跑、冲刺、引体、深蹲等项目炉火纯青,那么他大概率也可以在某些专项上凭借身体素质取得远超普通人的成绩,但并不足以成为顶尖的运动员。
为什么要说这则新闻呢?实际上,如果把我们的神经网络模型看做一个运动员,许多时候,这个运动员面对的专项比赛的评价指标(比如语义分割里的mIoU)和它的训练目标(比如常用的Cross Entropy Loss)并不完全一致。尽管CE Loss在绝大多数时候可以训练出不错的模型,但这是凭借足够强的“身体素质”得到的成绩,缺少了对于专项的针对性优化。
那么,能否用专项的评价指标,比如mIoU来指导训练呢?不幸的是,多数的评价指标都是不可微的,无法直接通过反向传播进行训练。当然,这并不能阻挡住研究者们的脚步。许多研究尝试通过对评价指标进行可微近似的方式,得到一个代理损失函数来指导训练(比如The Lovász-Softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks 和 Learning Surrogates via Deep Embedding)。但是,这些可微近似并不一定能让模型取得良好的训练效果——尽管训练目标是一致的,但教练的训练计划(梯度)的好坏也决定了运动员(模型)的训练水平。因此,代理损失函数的设计需要expertise以及较高的试错成本;即便如此,设计出的代理损失函数有许多也不足以独当一面,需要和CE Loss联合训练才能达到不错的效果。
Auto Seg-Loss 希望(在语义分割任务上)将这个流程自动化。简单来说,我们发现主流的语义分割指标(基本由TP/TN/FP/FN组成)都能写成可微运算(比如加、乘)、量化(one-hot)和logical运算(与AND、或OR)的形式。由于logical运算实际上只定义在 上,我们使用一个参数化的曲面对logical运算进行插值,使得其在 上有可微的定义,并使用softmax替代one-hot量化,从而得到一个可微版本的代理损失函数。接下来,我们使用强化学习算法(PPO2)对这个曲面的形状进行搜索,从而保证这个代理损失函数能够良好地指导训练。图1是我们算法的整体框架。
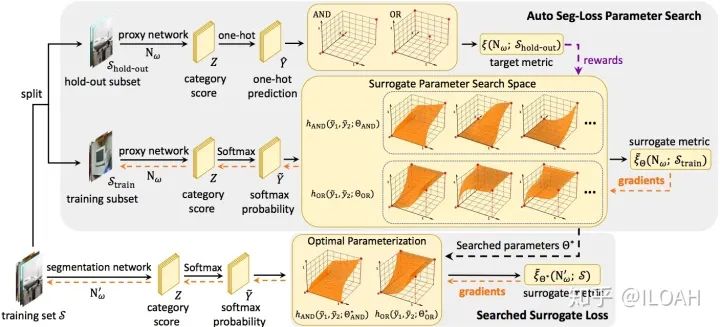
在实现时,我们尝试了分段Bezier曲线和分段线性曲线两种参数化的方式。我们提出了真值表约束和单调性约束作为先验,以限制参数化曲面的形状。实验表明这两种参数化的方式都可以得到不错的代理损失函数,同时这两条约束有效地提高了搜索的效率和效果。
我们在PASCAL VOC和Cityscapes上进行了实验。相对于手动设计的代理损失函数或Cross Entropy的改进,搜索出来的代理损失函数在主流的语义分割指标上都能达到on par或更高的水平,尤其对边缘相关指标的提升比较大。值得一提的有两点:
可能得益于搜索空间的设计,我们的搜索效率比较高,在VOC上使用DeepLab V3+,对于mIoU的搜索只需要8个小时左右(8卡V100,实际上搜到一半已经基本收敛了,时间大概相当于相同数据集两次正常训练); 我们搜索出的代理损失函数可以很好地迁移到其他的模型架构和数据集,因此只需要一次搜索就可多次使用(不仅如此,我们发现针对mIoU搜索出的参数同样适用于FWIoU和Boundary IoU等同类指标)。下面的两个表是我们尝试的两种参数化形式的实验结果。
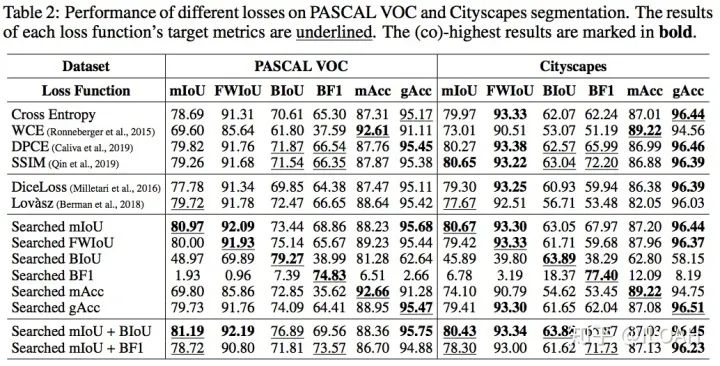
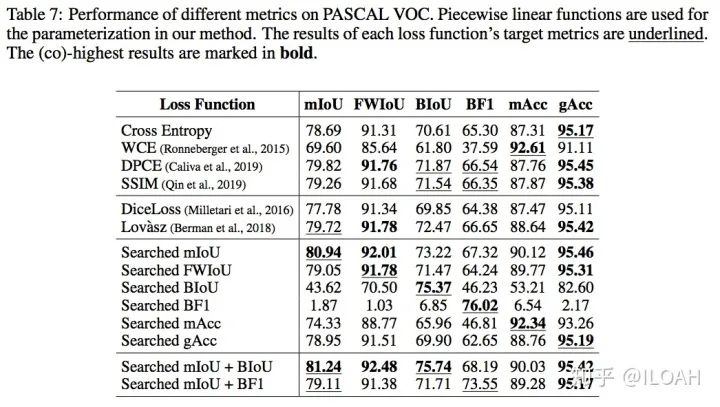
对于边缘相关的指标,我们发现,单独使用边缘指标指导训练会使模型只关注边缘的分割结果。图2展示了这个现象。通过将边缘指标和整体指标(如mIoU)组合进行训练,模型可以在保证合理的整体表现的同时提高边缘的分割效果。另外一个有趣的发现是,用来评估边缘准确度的Boundary F1 score在容许误差不为0时,用来指导训练可能会造成边缘的锯齿效果,这实际上是对这个指标的一个hack。我们在附录里讨论了这个问题。

我们希望Auto Seg-Loss可以降低研究以及业务中,为了某个给定的指标(比如边缘部分的IoU或者F-score)设计和调整损失函数时的试错成本,向自动损失函数设计前进一步。我们的文章已经在arxiv挂出来了,代码也即将开源并整合进一些开源Segmentation框架,期待各位试用以及与各位的讨论!
Auto Seg-Loss: Searching Metric Surrogates for Semantic Segmentation
https://arxiv.org/abs/2010.07930
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!
