
基于YOLOV5的数据集标注&训练,Windows/Linux/Jetson Nano多平台部署全流程

来源 | GiantPandaCV
编辑 | 极市平台
极市导读
本文将分windows和linux, pc和jetson nx平台分别给大家讲解如何使用Msnhnet部署yolov5. >>加入极市CV技术交流群,走在计算机视觉的最前沿
准备工作和数据标注
1. 安装配置Cuda, Cudnn, Pytorch该部分不进行详细介绍, 具体过程请百度.此处小编使用Pytorch1.9.、
2. 制作自己的数据集这里小编给大家准备了一个人体检测的数据集,供大家测试使用.链接:https://pan.baidu.com/s/1lpyNNdYqdKj8R-RCQwwCWg 提取码:6agk
3. 数据集准备工作.(1) 层级关系yolov5数据集所需的文件夹结构,以小编提供的数据集为例.
people文件夹下包含两个子文件夹images(用于存放图片)和labels(用于存放标签文件).
images文件夹下包含train和val两个文件夹,分别存放训练集的图片和验证集的图片.
labels文件夹下包含train和val两个文件夹,分别存放训练集的标签和验证集的标签.

dataset.png
(2) 下载标注软件这里小编自己编写了一款标注软件,直接支持导出yolov5格式。链接:https://pan.baidu.com/s/1AI5f5BYbboK0KYpHf7v4-A 提取码:19o1
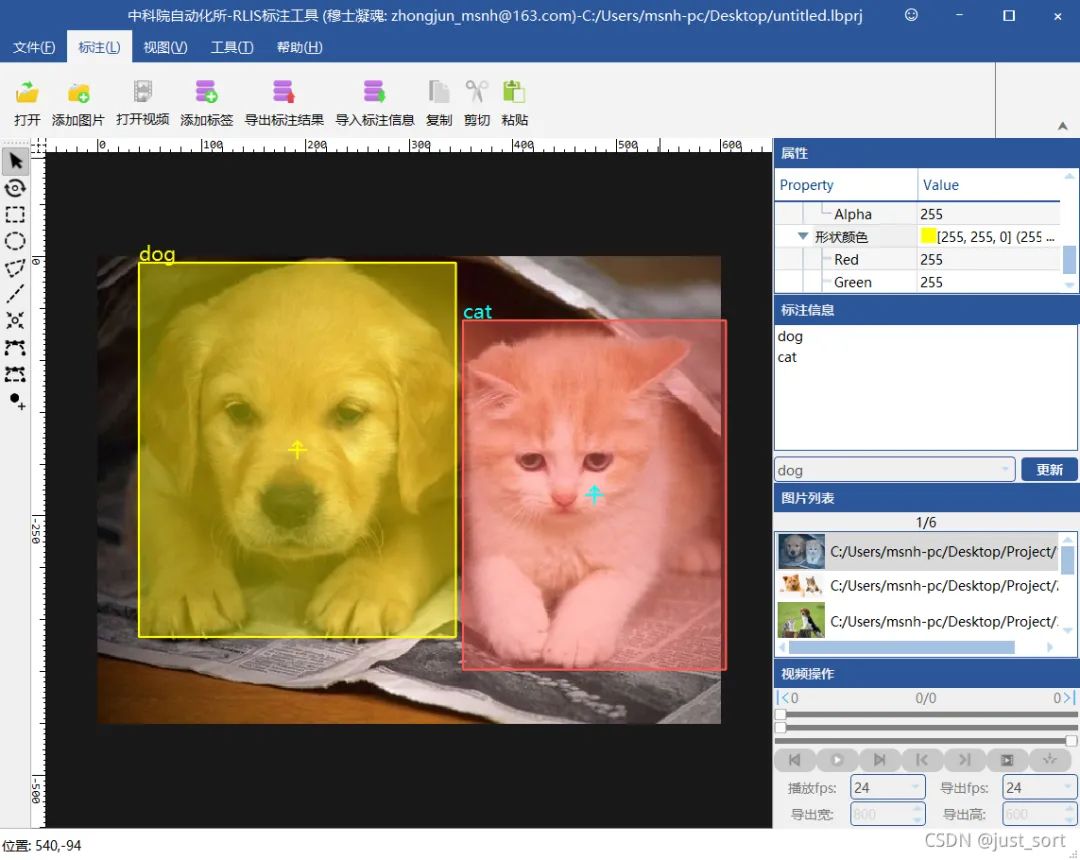
(3) 准备需要标注的数据(注意本软件单次只能标注1000张,建议单次500张以下)这里我简单准备了5张猫狗数据的。
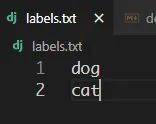
(4) 准备标签文件新建一个labels.txt文件(名字任意).将类名按照自己需要的顺序进行输入(注意,这里的顺序关系到最后导出yolov5 labels文件的标签顺序)
4. 开始标注
(1) 导入图片和标签文件
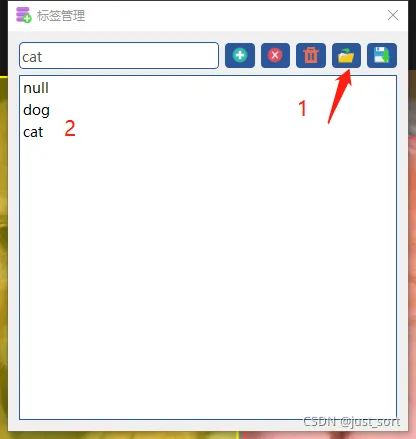
打开CasiaLabeler软件.点击 标注>打开 导入图片.点击 标注>添加标签导入标签。选择之前创建的标签文件,导入后如图。
(2) 开始标注并指定标签初步框选标注对象。

在标注信息栏,修改目标的标签。
在属性窗口可以修改标注框的颜色。
完成之后。(PS.标注框可以通过Ctrl+C和Ctrl+V进行复制粘贴)
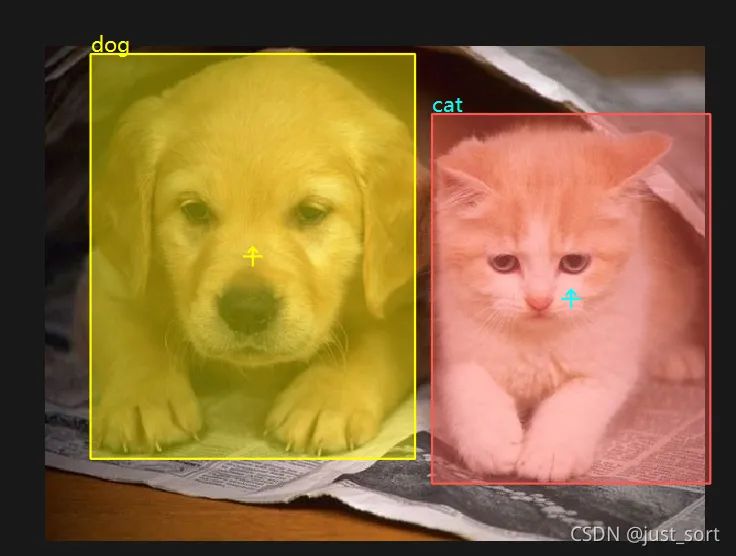
(3) 导出标注结果点击 标注>导出标注结果>yolov5 ,并指定一个空文件夹。
(4) 整理数据集层级结构
PS.
1.标注过程请及时保存工程文件。
2.第一次保存工程后,会在工程目录下间隔一定时间自动保存工程。可以点击 帮助>设置 选择自动保存时间间隔。
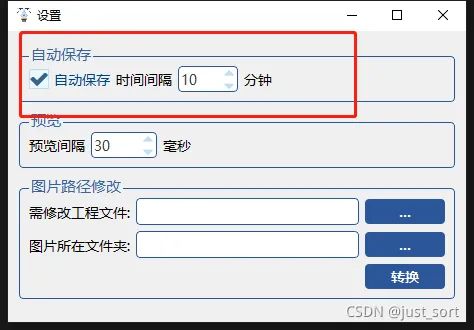
标注工程保存间隔时间设置,可调节 3.标注完成后,可以自动切换下一张预览标注结果。点击 视图>预览 即可自动切换标注场景,切换间隔时间按可以点击 帮助>设置 设置预览间隔时间。
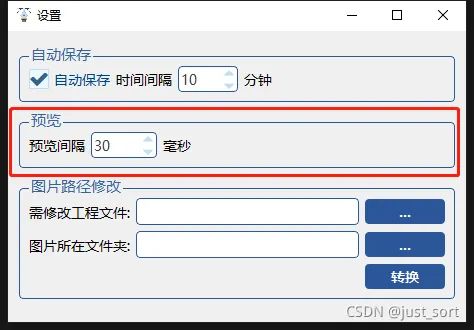
设置预览间隔时间 4.在标注一部分图片后,图片的位置发生了变化,或者图片拷贝至另外一台的电脑上,则会出现路径丢失的情况。
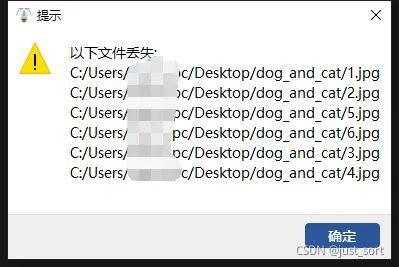
容错机制 5.丢失解决方法,点击 帮助>设置.在图片路径修改处,选择需要修改的工程,并指定图片新的路径,点击 转换 即可完成工程文件修复。再次打开工程即可。
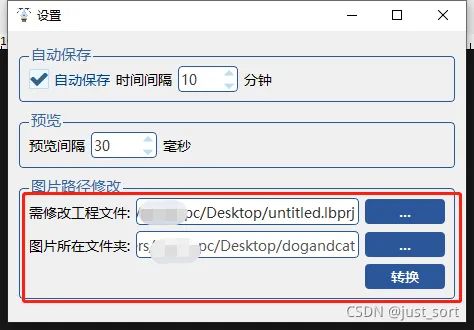
丢失解决方法
5. 准备Yolov5代码1 Clone代码git clone https://github.com/msnh2012/MsnhnetModelZoo.git**(注意!必须Clone小编为msnhnet定制的代码!)**2 安装依赖pip install requirements.txt(可以手动安装)
6. 准备Yolov5预训练模型
(1) 这里小编已经给大家准备好了预训练模型(yolov5_pred文件夹中)链接:https://pan.baidu.com/s/1lpyNNdYqdKj8R-RCQwwCWg 提取码:6agk
(2) 将下载好的预训练模型文件拷贝至yolov5ForMsnhnet/yolov5/weights文件夹下
模型训练
1. 准备工作(1) 数据集准备(这里以people数据集为例)
将标注好的数据集放置在datas文件夹下。
在datas文件夹下创建一个people.yaml文件,用于配置数据集信息。
train: 训练集图片位置
val: 验证集图片位置
nc: 类别数量
names: 所有类的名称
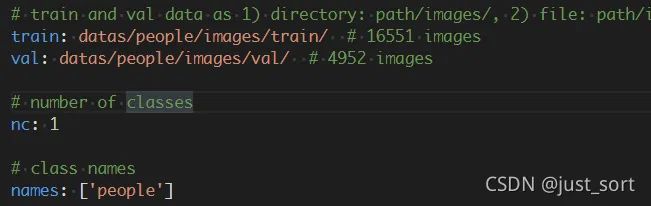
yaml文件配置
(2) 选择所需训练的模型(这里以yolov5m为例)
在models文件夹下,复制一份yolov5m.yaml,重新命名为yolov5m_people.yaml.
将nc改为1(还是一样,改成数据集的类的个数).
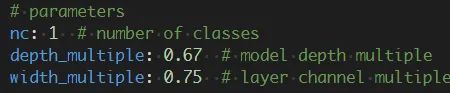
nc代表数据集目标类别总数
(3) 关于anchors
`# anchors
anchors:
[10,13, 16,30, 33,23] # P3/8 [30,61, 62,45, 59,119] # P4/16 [116,90, 156,198, 373,326] # P5/32
`
anchors参数共有三行,每行9个数值;每一行代表不同的特征图;
第一行是在最大的特征图上的anchors 第二行是在中间的特征图上的anchors 第三行是在最小的特征图上的anchors yolov5会在训练最开始自动对anchors进行check(可以修改 train.py中以下代码使用或者不使用自动anchor).
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
如果标注信息对anchor的最佳召回率>=0.98,则不需要重新计算anchor,反之则需要从新计算。
check代码如下:
参数:
dataset: 数据集
model: 模型
thr: dataset中标注框宽高比最大阈值,参数在超参文件 hyp.scratch.yaml"中"anchor_t"设置。
imgsz: 图片尺寸
def check_anchors(dataset, model, thr=4.0, imgsz=640):
# Check anchor fit to data, recompute if necessary
print('\nAnalyzing anchors... ', end='')
m = model.module.model[-1] if hasattr(model, 'module') else model.model[-1] # Detect()
shapes = imgsz * dataset.shapes / dataset.shapes.max(1, keepdims=True)
scale = np.random.uniform(0.9, 1.1, size=(shapes.shape[0], 1)) # augment scale
wh = torch.tensor(np.concatenate([l[:, 3:5] * s for s, l in zip(shapes * scale, dataset.labels)])).float() # wh
def metric(k): # compute metric
r = wh[:, None] / k[None]
x = torch.min(r, 1. / r).min(2)[0] # ratio metric
best = x.max(1)[0] # best_x
aat = (x > 1. / thr).float().sum(1).mean() # anchors above threshold
bpr = (best > 1. / thr).float().mean() # best possible recall
return bpr, aat
bpr, aat = metric(m.anchor_grid.clone().cpu().view(-1, 2))
print('anchors/target = %.2f, Best Possible Recall (BPR) = %.4f' % (aat, bpr), end='')
if bpr < 0.98: # threshold to recompute
print('. Attempting to generate improved anchors, please wait...' % bpr)
na = m.anchor_grid.numel() // 2 # number of anchors
new_anchors = kmean_anchors(dataset, n=na, img_size=imgsz, thr=thr, gen=1000, verbose=False)
new_bpr = metric(new_anchors.reshape(-1, 2))[0]
if new_bpr > bpr: # replace anchors
new_anchors = torch.tensor(new_anchors, device=m.anchors.device).type_as(m.anchors)
m.anchor_grid[:] = new_anchors.clone().view_as(m.anchor_grid) # for inference
m.anchors[:] = new_anchors.clone().view_as(m.anchors) / m.stride.to(m.anchors.device).view(-1, 1, 1) # loss
check_anchor_order(m)
print('New anchors saved to model. Update model *.yaml to use these anchors in the future.')
else:
print('Original anchors better than new anchors. Proceeding with original anchors.')
print('') # newline
聚类anchor代码 参数 path: 之前创建的people.yaml数据集配置文件路径。 n: anchors 组数量 xx,xx为一组 img_size: 图片尺寸。 thr: dataset中标注框宽高比最大阈值,参数在超参文件 hyp.scratch.yaml"中"anchor_t"设置。 gen: kmean算法iter次数。 verbose: 是否打印结果。
def kmean_anchors(path='./data/coco128.yaml', n=9, img_size=640, thr=4.0, gen=1000, verbose=True):
""" Creates kmeans-evolved anchors from training dataset
Arguments:
path: path to dataset *.yaml, or a loaded dataset
n: number of anchors
img_size: image size used for training
thr: anchor-label wh ratio threshold hyperparameter hyp['anchor_t'] used for training, default=4.0
gen: generations to evolve anchors using genetic algorithm
Return:
k: kmeans evolved anchors
Usage:
from utils.general import *; _ = kmean_anchors()
"""
thr = 1. / thr
def metric(k, wh): # compute metrics
r = wh[:, None] / k[None]
x = torch.min(r, 1. / r).min(2)[0] # ratio metric
# x = wh_iou(wh, torch.tensor(k)) # iou metric
return x, x.max(1)[0] # x, best_x
def fitness(k): # mutation fitness
_, best = metric(torch.tensor(k, dtype=torch.float32), wh)
return (best * (best > thr).float()).mean() # fitness
def print_results(k):
k = k[np.argsort(k.prod(1))] # sort small to large
x, best = metric(k, wh0)
bpr, aat = (best > thr).float().mean(), (x > thr).float().mean() * n # best possible recall, anch > thr
print('thr=%.2f: %.4f best possible recall, %.2f anchors past thr' % (thr, bpr, aat))
print('n=%g, img_size=%s, metric_all=%.3f/%.3f-mean/best, past_thr=%.3f-mean: ' %
(n, img_size, x.mean(), best.mean(), x[x > thr].mean()), end='')
for i, x in enumerate(k):
print('%i,%i' % (round(x[0]), round(x[1])), end=', ' if i < len(k) - 1 else '\n') # use in *.cfg
return k
if isinstance(path, str): # *.yaml file
with open(path) as f:
data_dict = yaml.load(f, Loader=yaml.FullLoader) # model dict
from utils.datasets import LoadImagesAndLabels
dataset = LoadImagesAndLabels(data_dict['train'], augment=True, rect=True)
else:
dataset = path # dataset
# Get label wh
shapes = img_size * dataset.shapes / dataset.shapes.max(1, keepdims=True)
wh0 = np.concatenate([l[:, 3:5] * s for s, l in zip(shapes, dataset.labels)]) # wh
# Filter
i = (wh0 < 3.0).any(1).sum()
if i:
print('WARNING: Extremely small objects found. '
'%g of %g labels are < 3 pixels in width or height.' % (i, len(wh0)))
wh = wh0[(wh0 >= 2.0).any(1)] # filter > 2 pixels
# Kmeans calculation
print('Running kmeans for %g anchors on %g points...' % (n, len(wh)))
s = wh.std(0) # sigmas for whitening
k, dist = kmeans(wh / s, n, iter=30) # points, mean distance
k *= s
wh = torch.tensor(wh, dtype=torch.float32) # filtered
wh0 = torch.tensor(wh0, dtype=torch.float32) # unflitered
k = print_results(k)
# Plot
# k, d = [None] * 20, [None] * 20
# for i in tqdm(range(1, 21)):
# k[i-1], d[i-1] = kmeans(wh / s, i) # points, mean distance
# fig, ax = plt.subplots(1, 2, figsize=(14, 7))
# ax = ax.ravel()
# ax[0].plot(np.arange(1, 21), np.array(d) ** 2, marker='.')
# fig, ax = plt.subplots(1, 2, figsize=(14, 7)) # plot wh
# ax[0].hist(wh[wh[:, 0]<100, 0],400)
# ax[1].hist(wh[wh[:, 1]<100, 1],400)
# fig.tight_layout()
# fig.savefig('wh.png', dpi=200)
# Evolve
npr = np.random
f, sh, mp, s = fitness(k), k.shape, 0.9, 0.1 # fitness, generations, mutation prob, sigma
pbar = tqdm(range(gen), desc='Evolving anchors with Genetic Algorithm') # progress bar
for _ in pbar:
v = np.ones(sh)
while (v == 1).all(): # mutate until a change occurs (prevent duplicates)
v = ((npr.random(sh) < mp) * npr.random() * npr.randn(*sh) * s + 1).clip(0.3, 3.0)
kg = (k.copy() * v).clip(min=2.0)
fg = fitness(kg)
if fg > f:
f, k = fg, kg.copy()
pbar.desc = 'Evolving anchors with Genetic Algorithm: fitness = %.4f' % f
if verbose:
print_results(k)
return print_results(k)
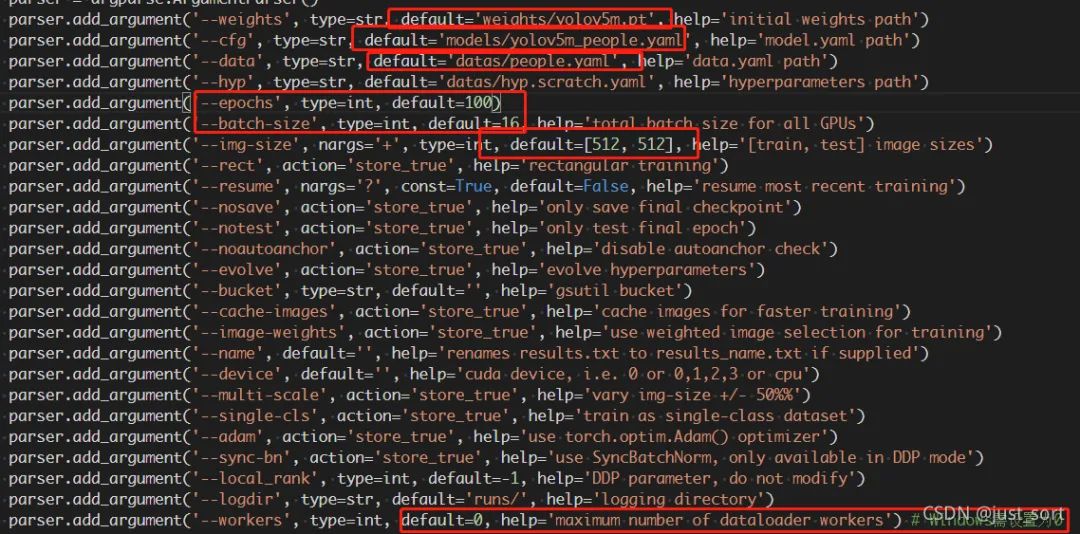
(4) train文件复制一个train.py文件命名为train_people.py.修改模型参数。
修改opt参数:
weights: 加载的权重文件(weights文件夹下yolov5m.pt) cfg: 模型配置文件,网络结构(model文件夹下yolov5m_people.yaml) data: 数据集配置文件,数据集路径,类名等(datas文件夹下people.yaml) hyp: 超参数文件 epochs: 训练总轮次 batch-size: 批次大小 img-size: 输入图片分辨率大小(512*512) rect: 是否采用矩形训练,默认False resume: 接着打断训练上次的结果接着训练 nosave: 不保存模型,默认False notest: 不进行test,默认False noautoanchor: 不自动调整anchor,默认False evolve: 是否进行超参数进化,默认False bucket: 谷歌云盘bucket,一般不会用到 cache-images: 是否提前缓存图片到内存,以加快训练速度,默认False name: 数据集名字,如果设置:results.txt to results_name.txt,默认无 device: 训练的设备,cpu;0(表示一个gpu设备cuda:0);0,1,2,3(多个gpu设备) multi-scale: 是否进行多尺度训练,默认False single-cls: 数据集是否只有一个类别,默认False adam: 是否使用adam优化器 sync-bn: 是否使用跨卡同步BN,在DDP模式使用 local_rank: gpu编号 logdir: 存放日志的目录 workers: dataloader的最大worker数量(windows需设置为0)
2. 开始train
train_people.py
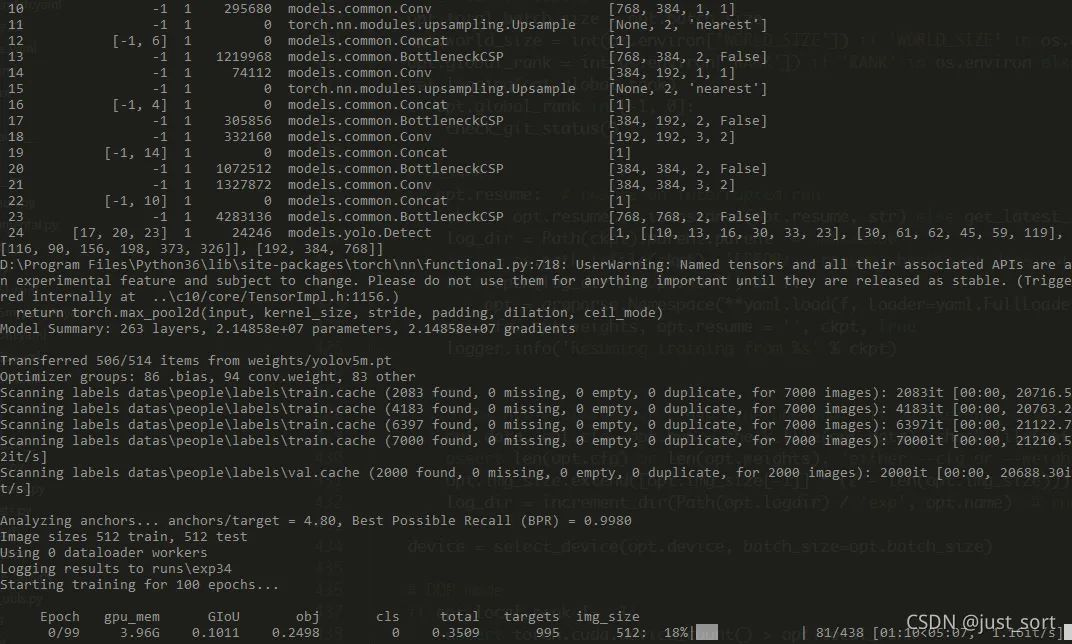
训练过程中,会在yolov5/runs文件夹下生成一个exp文件夹。
weights包含训练过程中最后一次训练好的模型last.pt和历史最佳模型best.pt。 events文件可以使用tensorboard查看训练过程。 在exp文件夹中,打开终端,运行 tensorboard --logdir=.在浏览器中输入http://localhost:6006/可查看训练过程与曲线.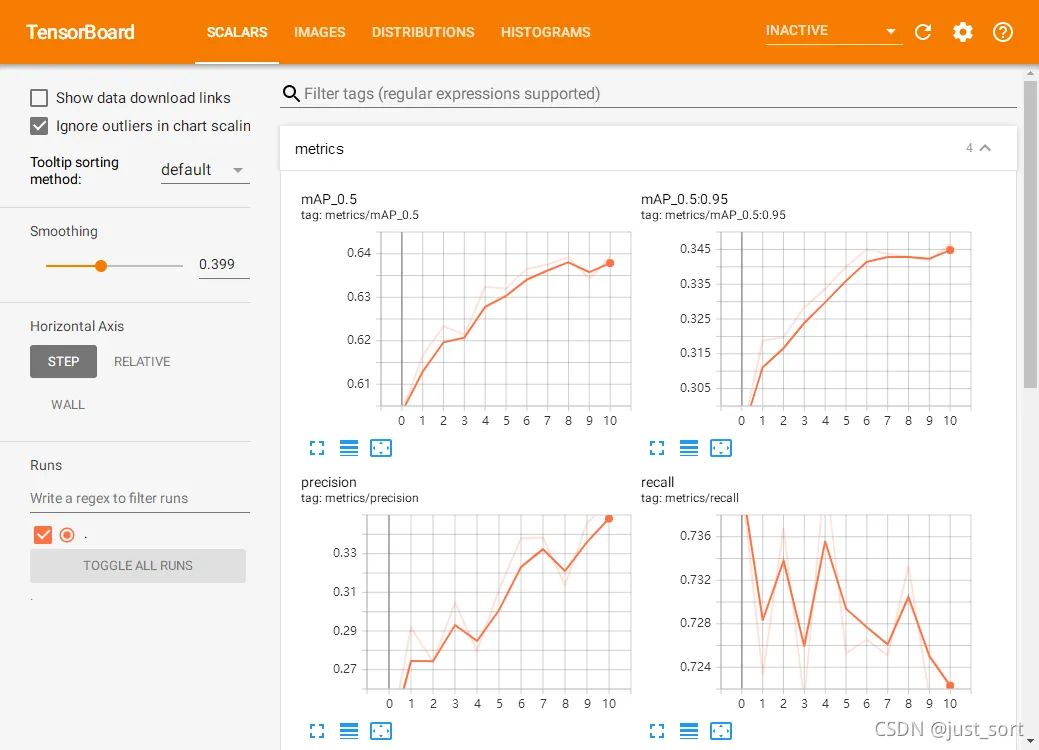
其它过程文件。
推理测试
将runs/exp文件夹下的best.pt文件拷贝到weights文件夹下。 在inference/images文件夹下放置几个测试图片。这里放置一张官方的bus.jpg

在yolov5文件夹中打开终端,执行:python detect --weights weights/best.pt --source inference/images --output inference/output
在inference/output文件夹中会生成推理结果。

至此,使用pytorch训练yolov5模型完成,下一节将介绍如何在CMake(c++),Winform(C#)以及windows(PC),linux(Jetson Nx)中使用Msnhnet部署yolov5.
基于MsnhNet部署yolov5
本篇将分windows和linux, pc和jetson nx平台分别给大家讲解如何使用Msnhnet部署yolov5.
pytorch模型转msnhnet
在yolov5文件夹下打开终端。将best.pt拷贝至weights文件夹下。执行
python yolov5ToMsnhnet.py
yolov5ToMsnhnet.py文件内容:
`from PytorchToMsnhnet import *
Msnhnet.Export = True
from models.experimental import attempt_load
import torch
weights = "weights/best.pt" # pt文件
msnhnetPath = "yolov5m.msnhnet" # 导出.msnhnet文件
msnhbinPath = "yolov5m.msnhbin" # 导出.msnhbin文件
model = attempt_load(weights, "cpu")
model.eval() # cpu模式,推理模式
img = torch.rand(5125123).reshape(1,3,512,512) #生成随机推理数据
tans(model,img,msnhnetPath,msnhbinPath) #模型转换
`
导出成功后会在文件夹下生成yolov5m.msnhnet和yolov5m.msnhbin文件。
Windows 篇
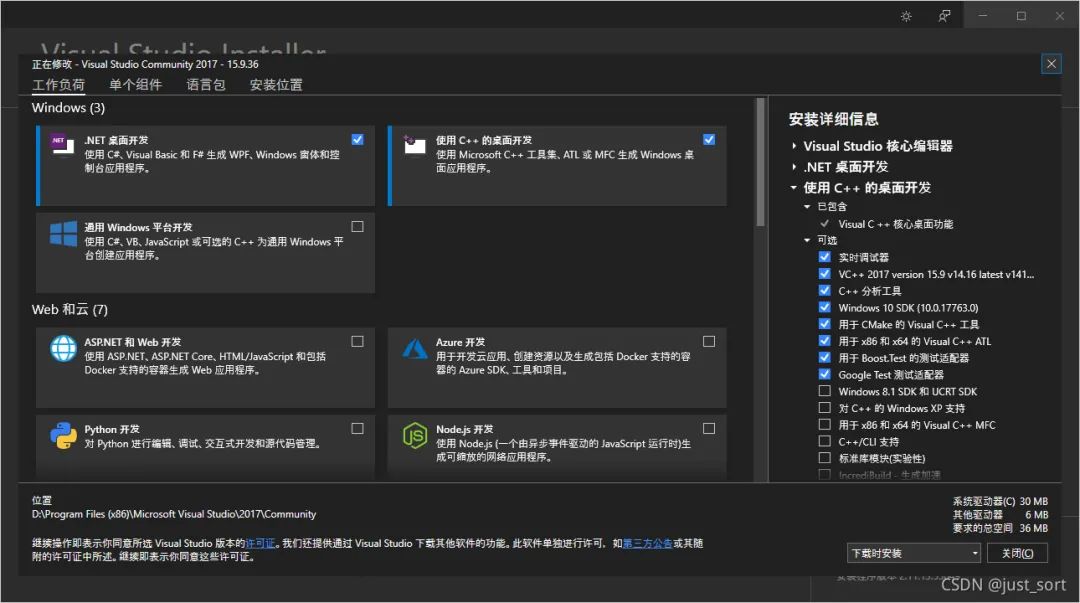
1. 准备工作(1) 安装Visual studio
网址:https://visualstudio.microsoft.com/zh-hans/ 下载visual studio 2017以上任意版本进行安装。此处勾选.Net桌面开发和使用c++的桌面开发。
(2) 安装cuda和cudnn, 此处请自行百度.
cuda网址:https://developer.nvidia.com/cuda-downloads
cudnn网址:https://developer.nvidia.com/zh-cn/cudnn
下载cudaxx.exe文件安装cuda(此过程最好使用cuda中自带的显卡驱动程序),下载cudnnxxx.zip文件,将其解压到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vxx.xx文件夹下,即完成了cuda和cudnn配置。
将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\vxx.xx 添加到系统环境变量。
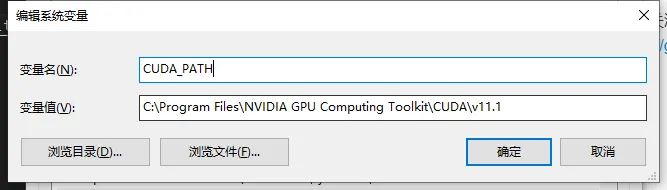
设置CUDA环境变量
(3) 打开cmd, 输入nvcc.测试cuda是否安装完成。以下结果说明cuda配置完成。

(4) 安装cmake(建议3.17).
cmake下载网址:https://cmake.org/files/v3.17/ 下载文件: cmake-3.17.5-win64-x64.msi 完成安装。
(5) clone Msnhnetgit clone https://github.com/msnh2012/Msnhnet.git2. 编译OpenCV库(1) 小编这里给大家准备好了OpenCV的源码文件,不用科学上网了。链接:https://pan.baidu.com/s/1lpyNNdYqdKj8R-RCQwwCWg 提取码:6agk(2) 打开cmake-gui.exe。

(3) 点击config选择安装的visual studio版本,选择x64(此处以VS2017为例),点击Finish,等待配置完成.
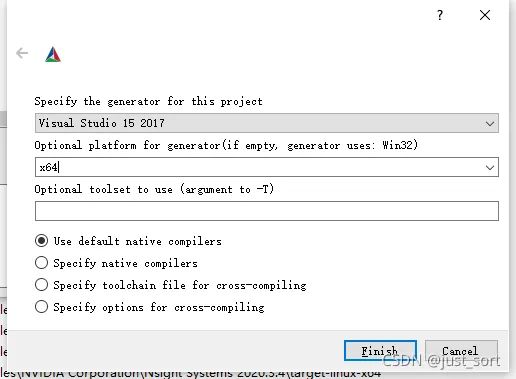
(4) 参数配置.
- CMAKE_INSTALL_PREFIX #指定安装位置,如: D:/libs/opencv
- CPU_BASELINE #选择AVX2(如果CPU支持AVX2加速)
- BUILD_TESTS #取消勾选
(5) 点击generate->Generating done.
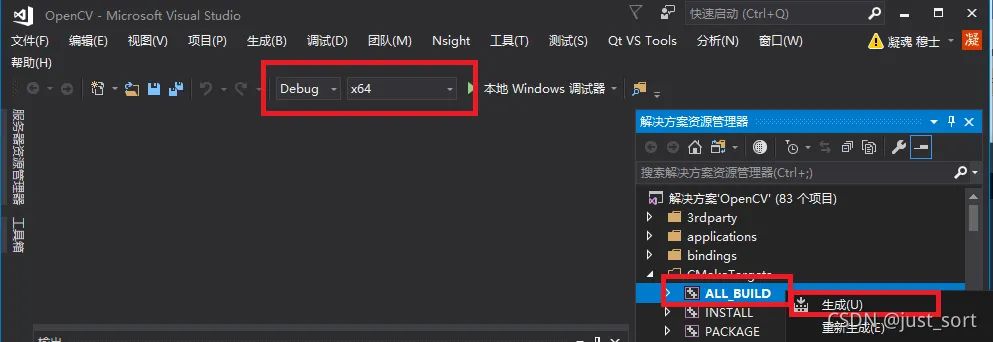
(6) 点击Open Project.分别选择Debug右键生成。(此过程需要等待10min~60min不等,根据电脑配置)
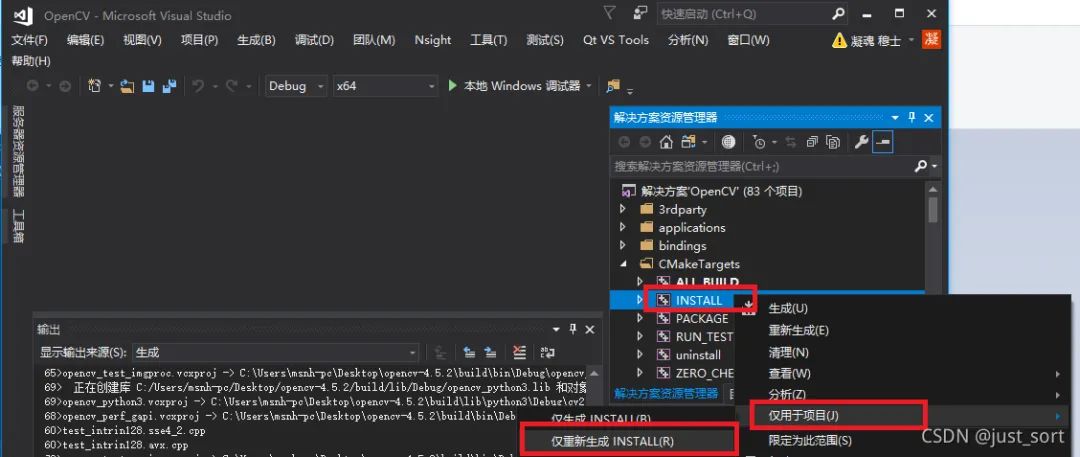
(7) 右键安装。(会将编译好的可执行文件安装在指定安装位置,如:D:/libs/opencv)
(8) 重复6-7步选择Release版本进行编译安装。
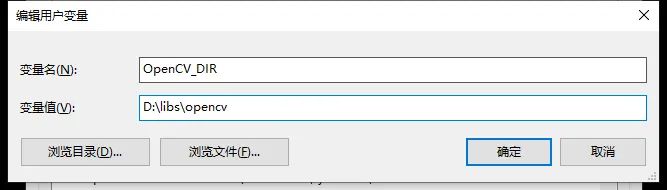
(9) 指定OpenCV_DIR环境变量,用于CMakeList能使用FindPackage找到OpenCV.
(10) 指定Path环境变量.在Path环境变量下添加Opencv的bin文件夹位置,如: D:\libs\opencv\x64\vc15\bin
3. 编译Msnhnet库
(1) 打开cmake-gui.exe。

(2) 点击config选择安装的visual studio版本,选择x64(此处以VS2017为例),点击Finish,等待配置完成.
(3) 勾选以下参数。
- CMAKE_INSTALL_PREFIX #指定安装位置,如: D:/libs/Msnhnet
- BUILD_EXAMPLE #构建示例
- BUILD_SHARED_LIBS #构建动态链接库
- BUILD_USE_CUDNN #使用CUDNN
- BUILD_USE_GPU #使用GPU
- BUILD_USE_OPENCV #使用OPENCV
- ENABLE_OMP #使用OMP
- OMP_MAX_THREAD #使用最大核心数
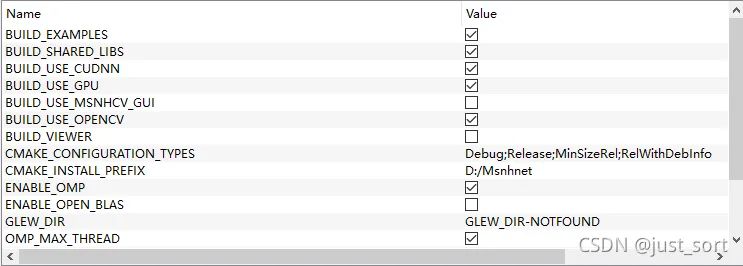
(4) 点击generate->Generating done.
(5) 点击Open Project.分别选择Debug右键生成。
(6) 右键安装。(会将编译好的可执行文件安装在指定安装位置,如:D:/libs/Msnhnet)
(7) 重复6-7步选择Release版本进行编译安装。
(8) 指定Msnhnet_DIR环境变量,用于CMakeList能使用FindPackage找到Msnhnet.
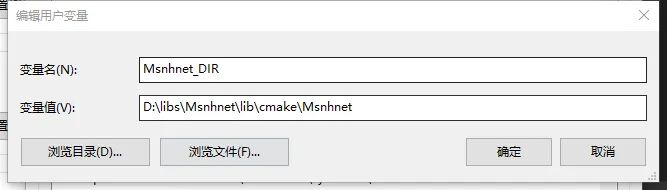
(9)指定Path环境变量.在Path环境变量下添加Msnhnet的bin文件夹位置,如: D:\libs\Msnhnet\bin
(10) 测试。
下载小编准备好的一系列Msnhnet测试模型。并解压到如D盘根目录 链接:https://pan.baidu.com/s/1mBaJvGx7tp2ZsLKzT5ifOg 提取码:x53z 在Msnhnet安装目录打开终端。执行:
yolov3_gpu D:/models
yolov3_gpu_fp16 D:/models #fp16推理
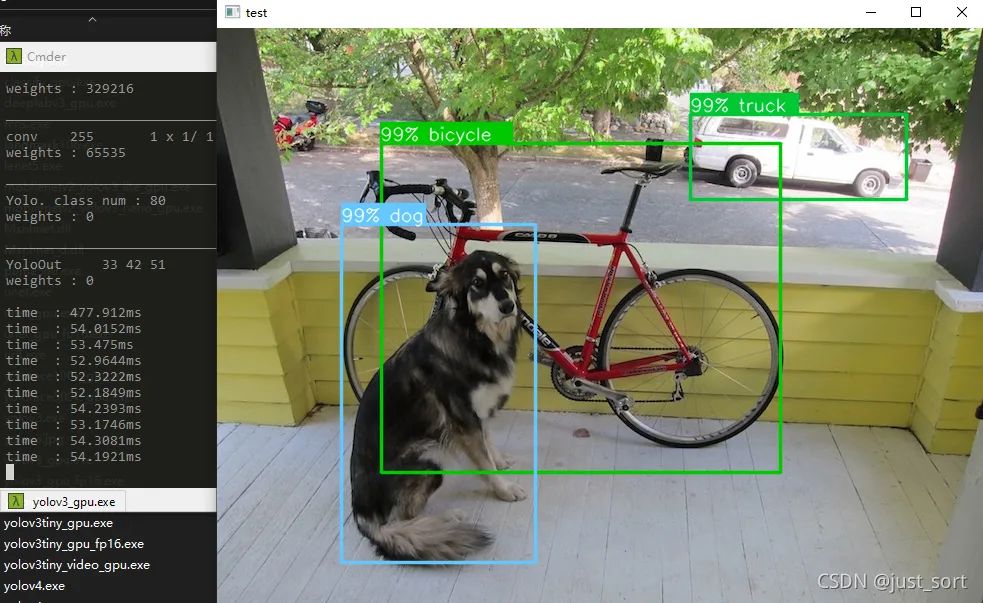
当然,你可以可以测试其它模型。
4. 使用C#部署Msnhnet
(1) clone MsnhnetSharp
git clone https://github.com/msnh2012/MsnhnetSharp
(2) 双击打开MsnhnetSharp.sln文件。
(3) 选择x64平台和Release模式,右键生成MsnhnetSharp,再生成MsnhnetForm.
(4) 点击启动按钮。
(5) 在参数配置栏,分别指定msnhnetPath和msnhbinPath为之前导出的yolov5m的参数。然后将上一节制作好的labels.txt文件,复制一份,重命名为labels.names.
(6) 点击初始化网络。等待初始化完成,init done.
(7) 点击读取图片, 选择那张bus.jpg.
(8) 点击yolo GPU(Yolo Detect GPU). 第一次推理时间较长。
(9) 点击重置图片。
(10) 再次点击yolo GPU(Yolo Detect GPU). 随后推理时间正常。
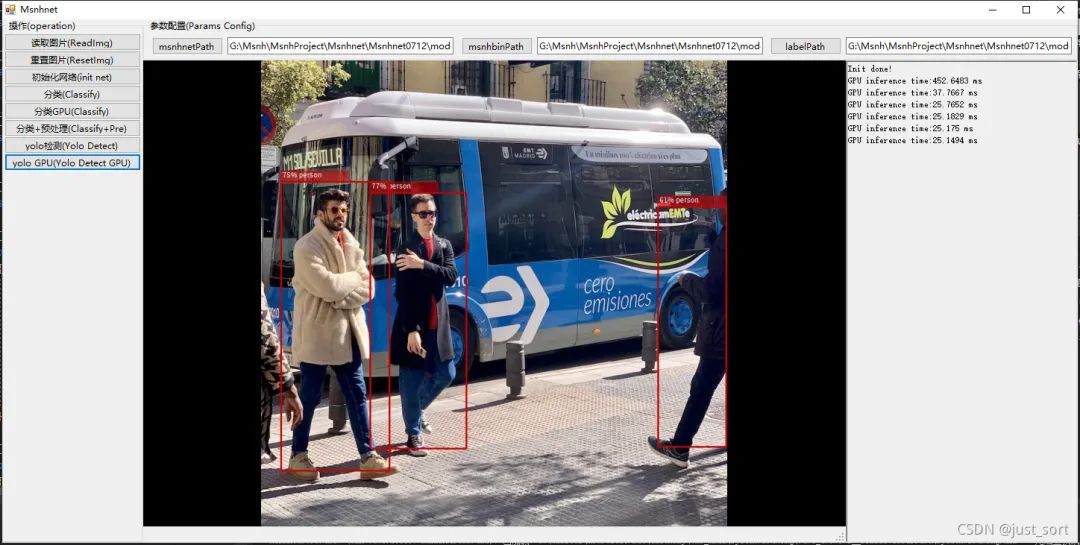
至此,使用C#部署Msnhnet完成,后续可以参考MsnhnetForm将MsnhnetSharp部署到你自己的工程中。
5. 使用CMake部署Msnhnet
工程文件源码:链接:https://pan.baidu.com/s/1lpyNNdYqdKj8R-RCQwwCWg 提取码:6agk
(1) 新建MsnhnetPrj文件夹
(2) 将yolov5m.msnhnet,yolov5m.msnhbin,labels.txt拷贝到MsnhnetPrj文件夹内
(3) 新建CMakeLists.txt文件
cmake_minimum_required(VERSION 3.15)
project(yolov5m_msnhnet
LANGUAGES CXX C CUDA
VERSION 1.0)
find_package(OpenCV REQUIRED)
find_package(Msnhnet REQUIRED)
find_package(OpenMP REQUIRED)
add_executable(yolov5m_msnhnet yolov5m_msnhnet.cpp)
target_include_directories(yolov5m_msnhnet PUBLIC ${Msnhnet_INCLUDE_DIR})
target_link_libraries(yolov5m_msnhnet PUBLIC ${OpenCV_LIBS} Msnhnet)
(4) 新建yolov5m_msnhnet.cpp文件
#include "Msnhnet/net/MsnhNetBuilder.h"
#include "Msnhnet/io/MsnhIO.h"
#include "Msnhnet/config/MsnhnetCfg.h"
#include "Msnhnet/utils/MsnhOpencvUtil.h"
void yolov5sGPUOpencv(const std::string& msnhnetPath, const std::string& msnhbinPath, const std::string& imgPath, const std::string& labelsPath)
{
try
{
Msnhnet::NetBuilder msnhNet;
Msnhnet::NetBuilder::setOnlyGpu(true);
//msnhNet.setUseFp16(true); //开启使用FP16推理
msnhNet.buildNetFromMsnhNet(msnhnetPath);
std::cout<<msnhNet.getLayerDetail();
msnhNet.loadWeightsFromMsnhBin(msnhbinPath);
std::vector<std::string> labels ;
Msnhnet::IO::readVectorStr(labels, labelsPath.data(), "\n");
Msnhnet::Point2I inSize = msnhNet.getInputSize();
std::vector<float> img;
std::vector<std::vector<Msnhnet::YoloBox>> result;
img = Msnhnet::OpencvUtil::getPaddingZeroF32C3(imgPath, cv::Size(inSize.x,inSize.y));
for (size_t i = 0; i < 10; i++)
{
auto st = Msnhnet::TimeUtil::startRecord();
result = msnhNet.runYoloGPU(img);
std::cout<<"time : " << Msnhnet::TimeUtil::getElapsedTime(st) <<"ms"<<std::endl<<std::flush;
}
cv::Mat org = cv::imread(imgPath);
Msnhnet::OpencvUtil::drawYoloBox(org,labels,result,inSize);
cv::imshow("test",org);
cv::waitKey();
}
catch (Msnhnet::Exception ex)
{
std::cout<<ex.what()<<" "<<ex.getErrFile() << " " <<ex.getErrLine()<< " "<<ex.getErrFun()<<std::endl;
}
}
int main(int argc, char** argv)
{
std::string msnhnetPath = "yolov5m.msnhnet";
std::string msnhbinPath = "yolov5m.msnhbin";
std::string labelsPath = "labels.txt";
std::string imgPath = "bus.jpg";
yolov5sGPUOpencv(msnhnetPath, msnhbinPath, imgPath,labelsPath);
getchar();
return 0;
}
(5) 配置CMake打开cmake-gui.exe,按以下配置。点击Config.Generate
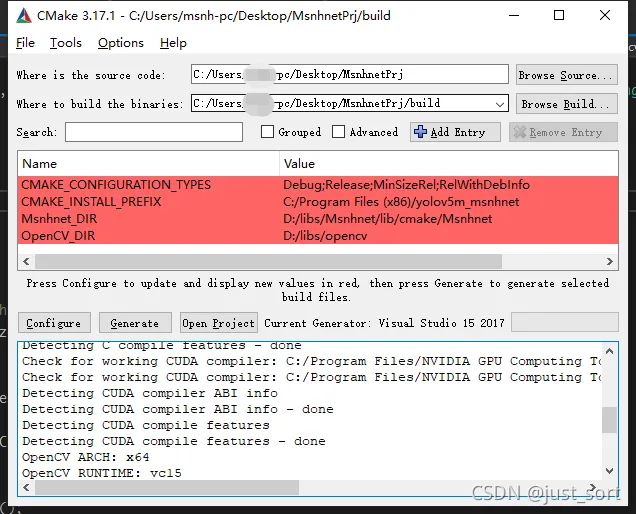
(6) 编译,点击Open Project,选择Release模式,参考之前编译Msnhnet直接生成。
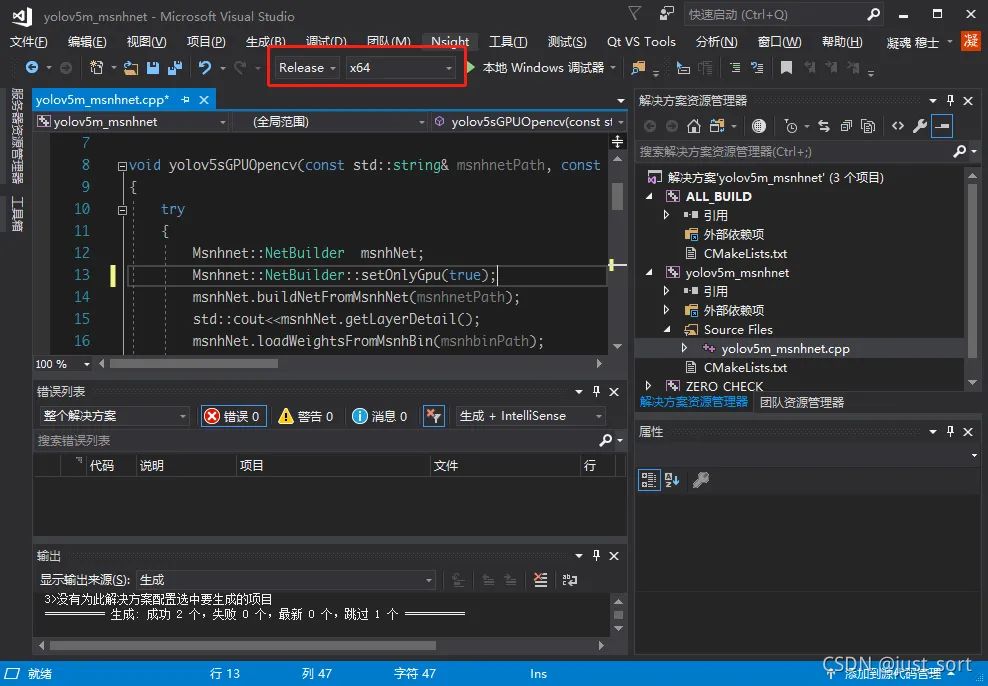
(7) 拷贝可执行文件。
从MsnhnetPrj/build/Release/yolov5m_msnhnet.exe拷贝到MsnhnetPrj目录。
(8) 部署结果双击yolov5m_msnhnet.exe查看部署结果。
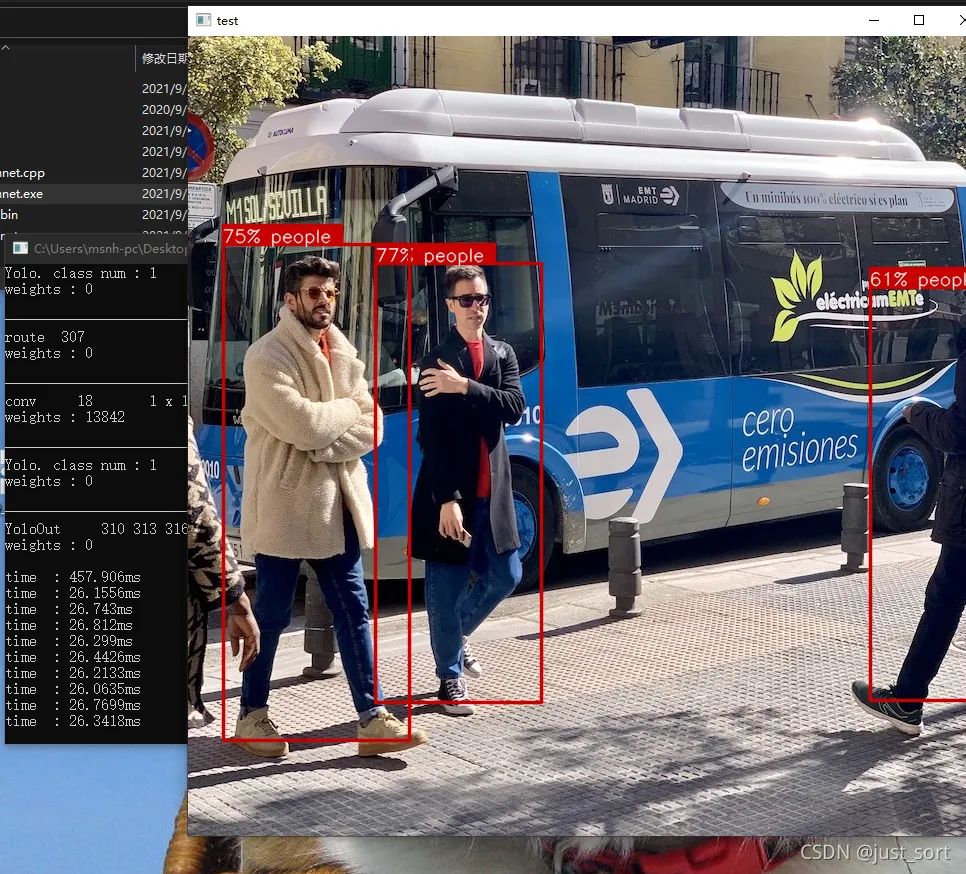
Linux(Jetson NX) 篇
1. 准备工作一般来说,Jetson都已经自带了cuda和cudnn,故不用专门安装。
安装构建工具
sudo apt-get install build-essential
安装opencv
sudo apt-get install libopencv
2. 编译Msnhnet库
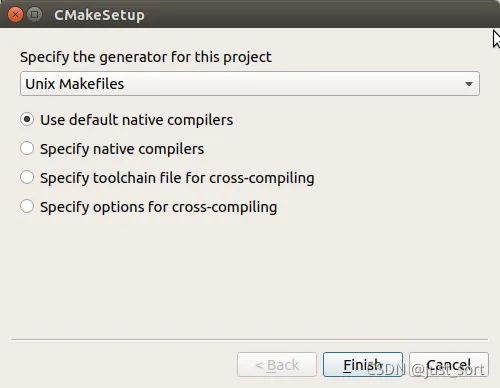
(1) 终端打开cmake-gui。

(2) 点击config选择cmake的编译链
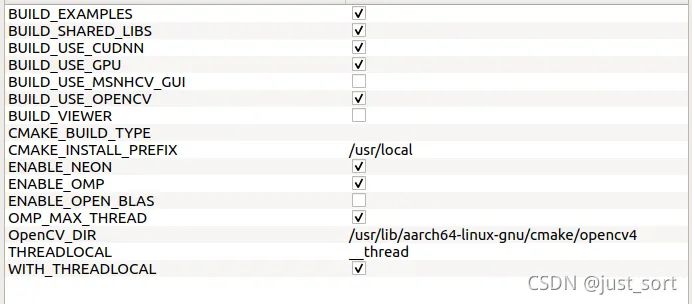
(3) 勾选以下参数。
- CMAKE_INSTALL_PREFIX #指定安装位置,如: D:/libs/Msnhnet
- BUILD_EXAMPLE #构建示例
- BUILD_SHARED_LIBS #构建动态链接库
- BUILD_USE_CUDNN #使用CUDNN
- BUILD_USE_GPU #使用GPU
- BUILD_USE_NEON #使用neon加速
- BUILD_USE_OPENCV #使用OPENCV
- ENABLE_OMP #使用OMP
- OMP_MAX_THREAD #使用最大核心数
(4) 点击generate->Generating done.
(5) 在Msnhnet/build文件夹中打开终端。
make -j
sudo make install
(6) 配置系统环境变量
sudo gedit /etc/ld.so.conf.d/usr.confg
# 添加: /usr/local/lib
sudo ldconfig
(7) 测试
下载小编准备好的一系列Msnhnet测试模型。并解压到如home根目录 链接:https://pan.baidu.com/s/1mBaJvGx7tp2ZsLKzT5ifOg 提取码:x53z
cd /usr/local/bin
yolov3_gpu /home/xxx/models
yolov3_gpu_fp16 /home/xxx/models #fp16推理

当然,你可以可以测试其它模型。
3. 使用CMake部署Msnhnet工程文件源码链接:https://pan.baidu.com/s/1lpyNNdYqdKj8R-RCQwwCWg 提取码:6agk
(1) 新建MsnhnetPrj文件夹
(2) 将yolov5m.msnhnet,yolov5m.msnhbin,labels.txt拷贝到MsnhnetPrj文件夹内
(3) 新建CMakeLists.txt文件
cmake_minimum_required(VERSION 3.15)
project(yolov5m_msnhnet
LANGUAGES CXX C CUDA
VERSION 1.0)
find_package(OpenCV REQUIRED)
find_package(Msnhnet REQUIRED)
find_package(OpenMP REQUIRED)
add_executable(yolov5m_msnhnet yolov5m_msnhnet.cpp)
target_include_directories(yolov5m_msnhnet PUBLIC ${Msnhnet_INCLUDE_DIR})
target_link_libraries(yolov5m_msnhnet PUBLIC ${OpenCV_LIBS} Msnhnet)
(4) 新建yolov5m_msnhnet.cpp文件
#include <iostream>
#include "Msnhnet/net/MsnhNetBuilder.h"
#include "Msnhnet/io/MsnhIO.h"
#include "Msnhnet/config/MsnhnetCfg.h"
#include "Msnhnet/utils/MsnhOpencvUtil.h"
void yolov5sGPUOpencv(const std::string& msnhnetPath, const std::string& msnhbinPath, const std::string& imgPath, const std::string& labelsPath)
{
try
{
Msnhnet::NetBuilder msnhNet;
Msnhnet::NetBuilder::setOnlyGpu(true);
//msnhNet.setUseFp16(true); //开启使用FP16推理
msnhNet.buildNetFromMsnhNet(msnhnetPath);
std::cout<<msnhNet.getLayerDetail();
msnhNet.loadWeightsFromMsnhBin(msnhbinPath);
std::vector<std::string> labels ;
Msnhnet::IO::readVectorStr(labels, labelsPath.data(), "\n");
Msnhnet::Point2I inSize = msnhNet.getInputSize();
std::vector<float> img;
std::vector<std::vector<Msnhnet::YoloBox>> result;
img = Msnhnet::OpencvUtil::getPaddingZeroF32C3(imgPath, cv::Size(inSize.x,inSize.y));
for (size_t i = 0; i < 10; i++)
{
auto st = Msnhnet::TimeUtil::startRecord();
result = msnhNet.runYoloGPU(img);
std::cout<<"time : " << Msnhnet::TimeUtil::getElapsedTime(st) <<"ms"<<std::endl<<std::flush;
}
cv::Mat org = cv::imread(imgPath);
Msnhnet::OpencvUtil::drawYoloBox(org,labels,result,inSize);
cv::imshow("test",org);
cv::waitKey();
}
catch (Msnhnet::Exception ex)
{
std::cout<<ex.what()<<" "<<ex.getErrFile() << " " <<ex.getErrLine()<< " "<<ex.getErrFun()<<std::endl;
}
}
int main(int argc, char** argv)
{
std::string msnhnetPath = "../yolov5m.msnhnet";
std::string msnhbinPath = "../yolov5m.msnhbin";
std::string labelsPath = "../labels.txt";
std::string imgPath = "../bus.jpg";
yolov5sGPUOpencv(msnhnetPath, msnhbinPath, imgPath,labelsPath);
getchar();
return 0;
}
(5) 编译,在MsnhnetPrj文件夹下打开终端
mkdir build
cd build
make
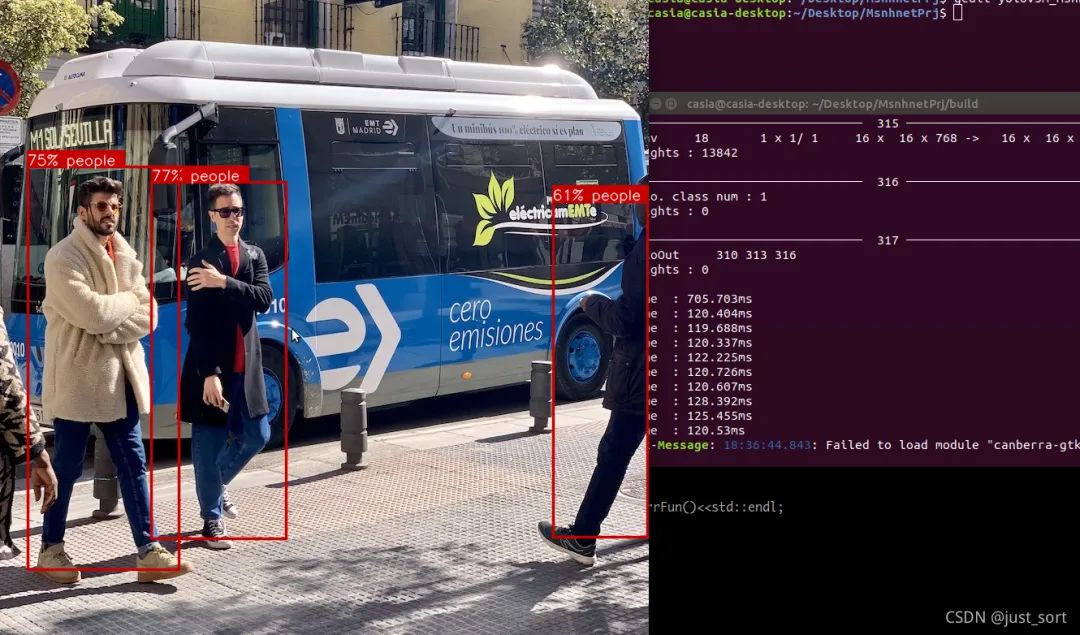
./yolov5m_msnhnet
(6) 部署结果
Linux(PC) 篇
和Jetson Nx部署类似, 主要区别是先要在Linux上配置好cuda和cudnn, 然后卸载CMake, 安装CMake 3.17版本. 其它的和Jestson NX一样.(ps. 在CMake参数配置里没有NEON项,此为ARM平台专有)到此,使用Msnhnet从0到部署Yolov5网络完成。
最后
欢迎关注我和BBuf及公众号的小伙伴们一块维护的一个深度学习框架 Msnhnet:https://github.com/msnh2012/Msnhnet
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
