
Hive SQL on Flink 构建流批一体引擎
摘要:
本文整理
自阿里巴巴开发工程师罗宇侠、阿里巴巴开发工程师方盛凯,在 Flink Forward Asia 2022 流批一体专场的分享。本篇内容主要分为五个部分:
1.
构建流批一体引擎的挑战
2.
Hive SQL on Flink
3.
流批一体引擎的收益
4.
Demo
5.
未来展望
Tips:
点击
「阅读原文」
查看原文视频&
演讲 ppt
01
构建流批一体引擎的挑战
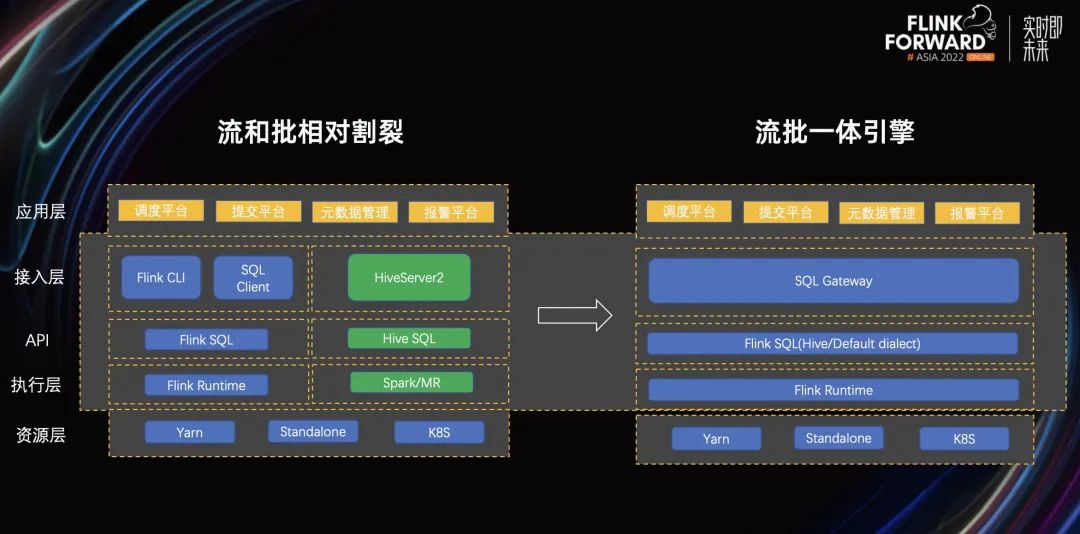
目前,流和批仍然是相对割裂的。虽然我们在应用层统一了,但从接入层开始,不同的引擎依旧有不同的接入层、API 层、执行层。我们认为,统一的流批一体引擎应该是从接入层开始使用 SQL Gateway 作为接入层。在 API 层使用 Flink SQL 作为编写作业的主要语言,在执行层替换成统一的 Runtime。
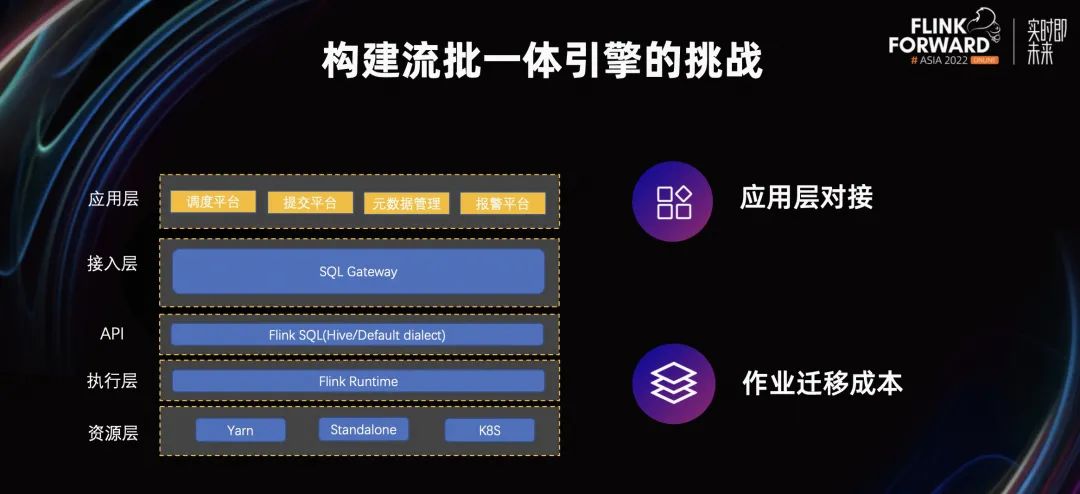
为了达成统一的流体引擎,我们认为有以下两个难点:
应用层的对接。在流批割裂的环境下,应用层仍然是有不同的提交平台,如何保证原来的应用层能无损且直接地对接到新的 SQL Gateway 上,是一个巨大的难点。
用户作业迁移的成本。用户原来的 Batch 作业是用 Hive SQL 进行撰写的,现在则需要替换成 Flink SQL。为了保证用户的作业能无损迁上来,我们需要解决语言上的兼容和用户所用的 UDF 的兼容。

为此我们围绕以下两点在 Flink 1.16 上做了大量改进,保证了 Hive SQL on Flink 构建流批一体引擎是可行的。
Flink 对 Hive SQL 的兼容,我们在 1.16 中大大提升了对 Hive SQL 本身的兼容性。
我们在 Flink 社区引入了 SQL Gateway,从而兼容 Hive 的生态。
02
Hive SQL on Flink
接下来我来讲一下 Flink 社区具体做的一些工作来使得基于 Hive SQL on Flink 构建流批一体引擎成为可能。
在这一方面,Flink 社区经过多个版本的打磨,做了大量的工作使得基于 Hive SQL on Flink 构建流批一体引擎能够在生产中可用。
2.1 Hive SQL on Flink 的具体工作

第一,集成 Hive MetaStore。众所周知,在大数据领域,Hive MetaStore 已经是事实的元数据管理标准了,所以 Flink 在很早的版本就已经开始集成 Hive MetaStore。主要分为以下三方面的支持:
支持 Hive MetaStore 作为 Flink 的 Catalog,Hive 已有的表可自动注册进 Flink 中,用户无需再定义各种 DDL 来映射底层的 Hive 表。
支持 Hive MetaStore 存储 Flink 定义的 Hive 表/ 非 Hive 表。
支持从 Hive MetaStore 获得表的统计信息,从而优化查询的执行计划,提升端到端 SQL 的性能。
第二,集成 Hive 的 UDF。主要支持以下两方面:
Hive 提供了非常丰富的 UDF,在 Flink 中我们可以直接调用 Hive 中内置的 UDF。换句话说,用户使用 Flink 就能享受到 Hive 那套内置 UDF 所带来的方便及易用性。
支持调用自定义的 Hive UDF。对于熟悉 Hive 的人,他们会基于 Hive UDF 的接口去定义自己的 UDF。但如果他们想用 Flink,又不想废弃那些 UDF,更不想重写。要怎么办呢?其实 Flink 支持调用用户自定义的 Hive UDF,所以用户不需要对 UDF 做任何重写的工作,这极大的方便了用户的操作。

第三,Hive 表的读写。主要支持以下几方面:
支持流读/批读/流写/批写 Hive 表。
批读 Hive 表支持静态分区裁剪和动态分区裁剪。可以大幅削减读取数据的规模,从而提升读的性能和效率。
批读 Hive 表支持并发推断。在批场景下,并发设置是一个比较难的问题,但如果在批读 Hive 场景下,我们可以通过 Hive 表的文件信息推断出合理的并发,从而提升端到端链路的性能。
批写/流写 Hive 支持自定义分区提交策略。在批调度链路里,我们可能会把先提交分区,然后触发一些其他下游的操作或调度,这时我们无需引入其他额外的组件,直接在 Flink 里自定义这些分区提交的策略即可。比如指定分区提交后,触发定时任务或者在消息队列插一条数据等等。
流写 Hive 表支持小文件自动合并。在流的场景下,会生成很多小文件,但在流写 Hive 表时,我们支持小文件的自动合并,通过将小文件合并成更大的文件,减少了小文件的数量,从而缓解 HDFS 集群的压力。
批写 Hive 表支持自动收集统计信息,这一部分完全兼容了 Hive 的行为。在使用 Hive 写 Hive 表的时候,它会收集统计信息并提交到 MetaStore。我们用 Flink 写 Hive 表的时候,也能支持将统计信息提交到 MetaStore,包括文件的大小、数据的条数等等。
2.2 Flink 兼容 Hive SQL 的架构
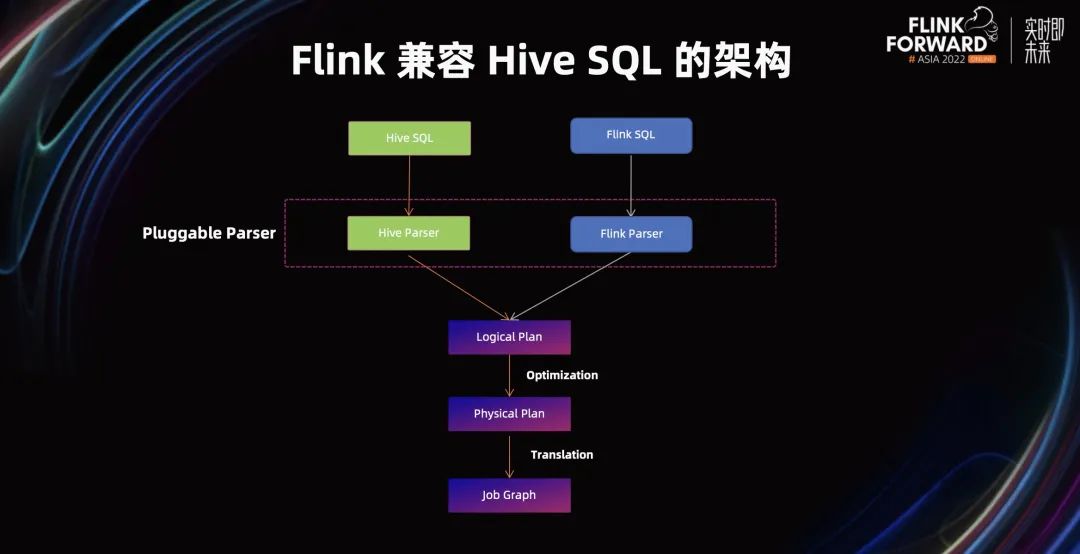
用户的 Hive SQL 如何在 Flink 中顺滑地运行?上图是 Flink 兼容 Hive SQL 的架构,可以看到,它被分成了两个不同的分支,Flink SQL 和 Hive SQL。然后它们会由不同的 Parser 去做解析,Flink SQL 通过 Flink Parser 做解析,Hive SQL 通过 Hive Parser 做解析,Hive Parser 的行为和 Hive 的行为保持一致。
接下来它们都会生成 Flink 里的 Logical Plan,Logical Plan 进行优化,生成 Physical Plan,Physical Plan 再进行翻译,生成具体的 Job Graph,最后交由 Flink Runtime 执行。
基于这套架构,我们可以很方便地扩展 Flink 来提供对其他语法的支持。另外通过这套架构,我们理论上还能达到对 Hive 语法的百分之百兼容。
2.3 Flink 对 Hive SQL 的兼容

接下来讲一下我们最后达到了怎样的效果。
第一,支持生产上常用的 Hive 语法。即生产上的作业能够很好地迁移到我们的 Flink 中执行。主要支持以下语法:
支持 distribute by/sort by/ cluster by。
支持 multi insert。一个 scan 可以插入到多个不同数据的 sink 端,极大的提高了数据 ETL 链路的效率。
支持 insert directory。
支持 load data。
支持 create function using jar。
……
那么我们到底对 Hive SQL 的兼容度能达到多少呢?答案是 94%了。这个数字又是怎么得出来的呢?
基于 Hive 2.3 的 qtest 测试集,12000 条 DQL/DML 都扔到 Flink 去执行,这些 SQL 都能够被正常执行。
12000 条 DQL/DML 也包含了很多对 ACID 表的查询。Hive 的 ACID 表在生产中用的较少,如果我们除去针对 ACID 表的 DQL/DML,兼容度可达 97%。
2.4 Flink 对 Hive 生态的兼容
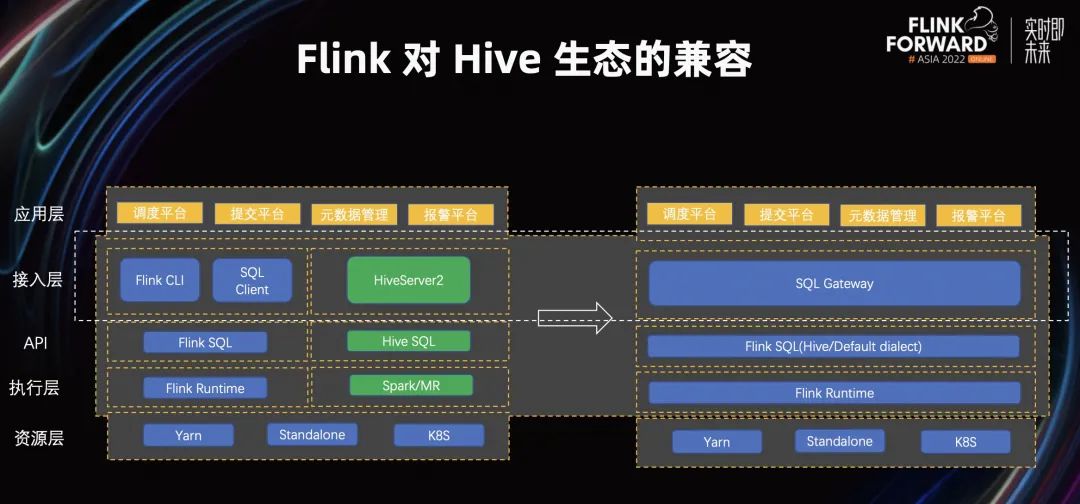
如上图所示,之前的内容讲的是 API 层、执行层已经统一了。那么我们如何在接入层也把它统一掉呢?就引出我们接下来要分享的 Flink SQL Gateway 了。
2.5 引入 Flink SQL Gateway 的原因
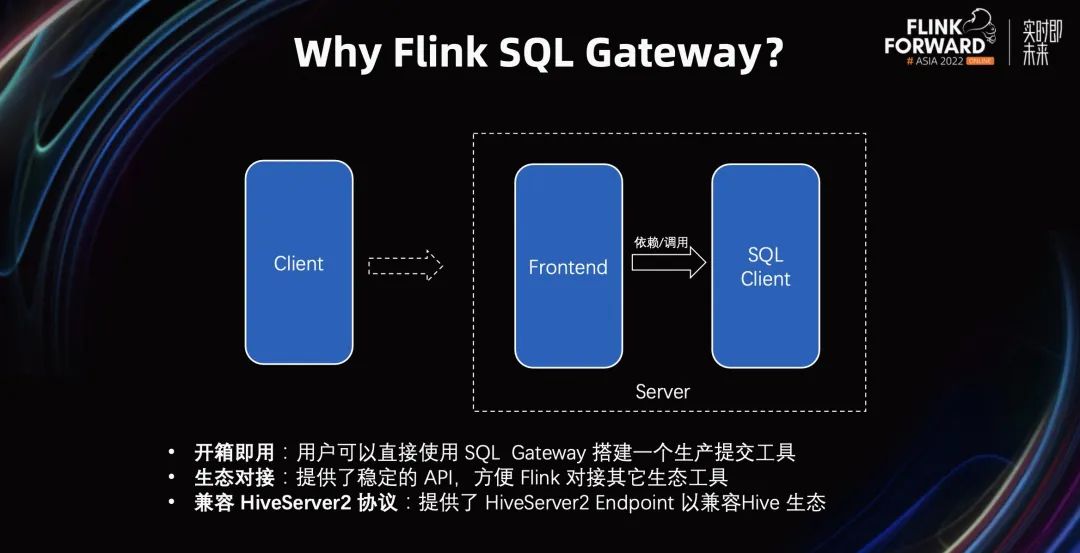
我们为什么引入 Flink SQL Gateway 呢?原因有以下三个:
目前 Flink 社区官方提供了 SQL Client 供用户提交 SQL 作业。但由于 SQL Client 本身没有服务化,用户往往需要基于 SQL Client 做一层封装,添加一个服务化的前端。通过该服务化的前端,用户的 SQL 作业最终会被提交给 SQL Client 去执行。以上的过程比较繁琐而且开发成本较大,因此,我们在社区提供了一个默认的服务化的实现,降低用户的使用成本。
以上的方案是基于 SQL Client 来做的作业提交,但这套 API 并不稳定。而引入的 SQL Gateway 则提供了稳定的 API。
相比于 SQL Client, SQL Gateway 是 C/S 架构,更容易对接诸多生态 ,e.g. HiveServer2。
基于以上的考量,Flink 社区引入了 Flink SQL Gateway。它有以下特点:
开箱即用,用户可以直接使用 SQL Gateway 搭建一个生产可用的提交工具。
生态对接,提供了稳定的 API,方便 Flink 对接其它生态工具。
兼容 HiveServer2 协议,提供了 HiveServer2 Endpoint 以兼容 Hive 生态。
2.6 Flink SQL Gateway 架构
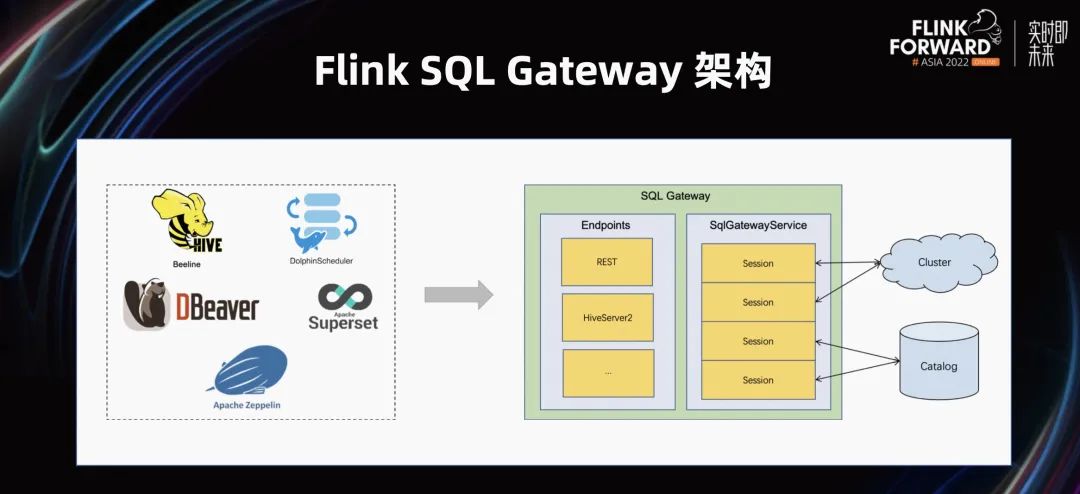
上图是 Flink SQL Gateway 的架构图,可以分成前端和后端。
后端提供了多租户能力,可以对接不同的集群,包括 Flink Standalone,Flink On Yarn 等。另外,它支持用户自定义的 Catalog,可以用默认的 Catalog,也可以用 MySQL Catalog、Hive Catalog。
SQL Gateway 目前提供了两个 Endpoint,分别是 RES
T Endpoint 和 HiveSer
ver2 Endpoint。
REST
Endpoint
:用
户可以通过 REST 工具提交作业。
HiveServer2 Endpoint:通过它我们就能提供对接 Hive 主流生态的能力。
从上图左侧可以看到目前一些 Hive 的生态工具,包括 Beeline、DBeaver、DolphinScheduler、Superset、Apache Zeppelin 等,都能很好的对接到 Flink SQL Gateway 上。
2.7 HiveServer2 Endpoint
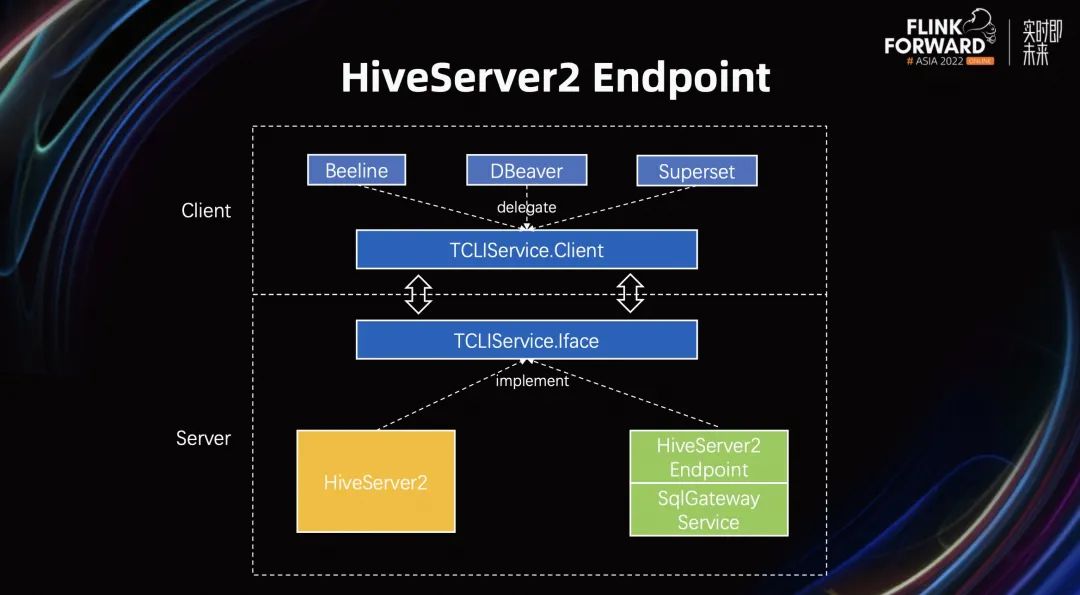
上面提到 HiveServer2 Endpoint 在兼容 Hive 生态的重要性,接下来让我们一起来看一下它的具体架构。从上图可以看到主要分为两层,Client 端和 Server 端。HiveServer2 实际上是定义了 Client 端和 Server 端的一套通信协议,如果要兼容 HiveServer2,我们只要实现 HiveServer2 定义的这套协议即可。通过兼容 HiveServer2 协议,我们可以在不修改 Client 的情况下,将请求调用都转发到 Flink SQL Gateway,并在 Flink 集群执行。
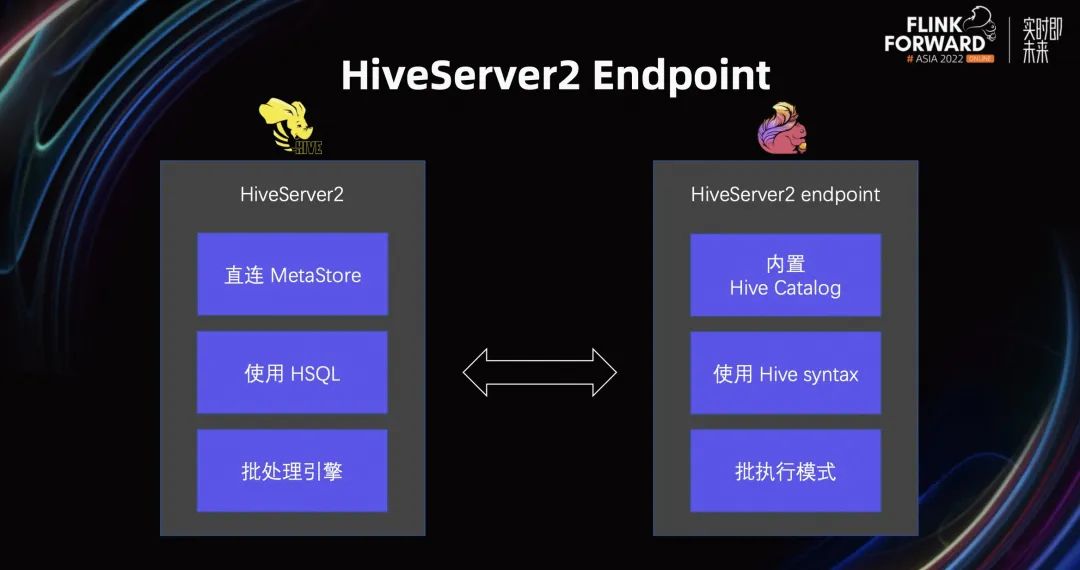
上图呈现的是 HiveServer2 和 HiveServer2 Endpoint 的对应关系。
HiveServer2 提供了直连 MetaStore 的能力,可以使用 Hive SQL,底层是批处理引擎,包括 MapReduce 或者 Spark 等。
HiveServer2 Endpoint 内置了 Hive Catalog,其实就是 Hive MetaStore。同时它也使用 Hive 语法,底层也是批处理引擎,即 Flink Batch 引擎。
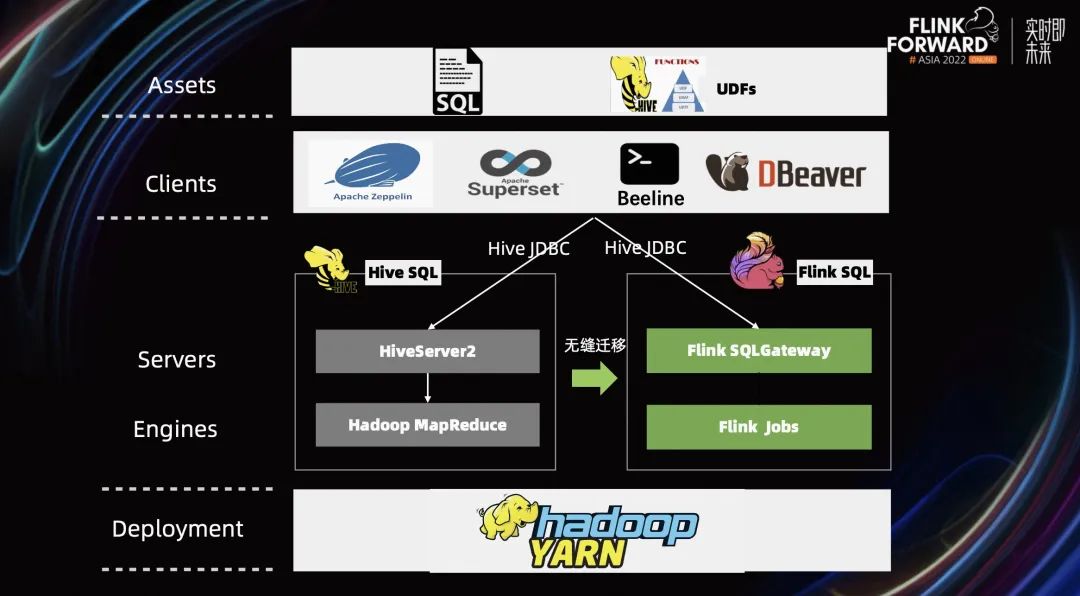
讲了这么多关于 Hive 兼容的内容,最后我们能达到什么样的效果呢?
上面的图我们从上往下看。通常,用户的 SQL 脚本通过 Apache Zeppelin、Beeline 等客户端提交作业,然后通过 Hive 的 JDBC 提交到 HiveServer2 中,再交由底下具体的引擎来执行。
基于上述介绍的 Flink 对兼容 Hive 所做的工作,我们只需要将引擎层改成 Flink 将可以作业直接迁移到 Flink 上,从而达到了一个非常平滑且无缝迁移的过程。
03
流批一体引擎的收益
3.1 Hive SQL on Flink 构建流批一体引擎

基于 Hive SQL on Flink 构建了流批一体引擎,我们获得了以下收益:
第一,统一流批引擎。降低维护成本,提升研发的效率。因为我们现在就一套引擎了,所以维护成本会非常低。
第二,流批一体数仓。我们通过流批一体引擎构建出了流批一体 SQL 层。借此,我们可以把流批一体的存储考虑进来,构建完整的流批一体数仓架构。
第三,Hive SQL 实时化。目前 Hive SQL 主要还是跑在批引擎上,每天做一次调度,产生结果。如果把 Hive SQL 迁移到 Flink 中,我们就可以很方便的将它实时化改造。只要把引擎模式设置成流模式,就可以将其实时化,数仓实时化改造的成本非常低。
第四,OLAP & 联邦查询。我们可以基于 Flink + Hive SQL 搭建 OLAP 系统。借助 Flink 对各种数据源的支持,以及对 Hive SQL 稍微进行扩展就可以实现联邦查询。
3.2 基于 Hive 语法进行联邦查询
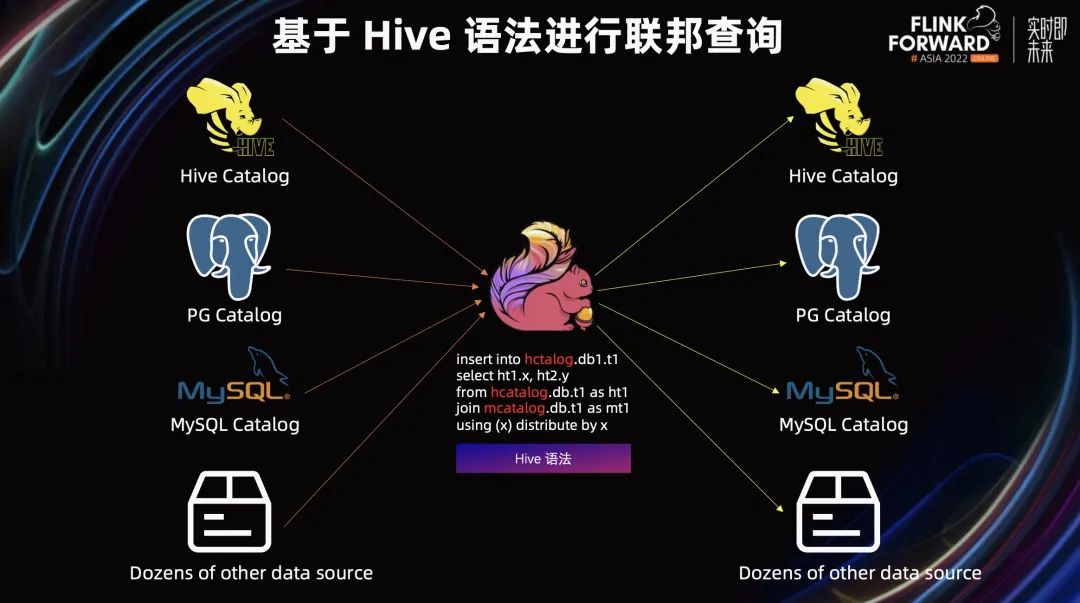
联邦查询是指,查不同数据源的数据,再写到不同的数据存储中。Hive 本身虽然通过 storage handler 提供了查询不同数据源的数据,比如 MySQL、Hbase 等,但相对来说还是比较复杂和不太完善。所以 Flink 就对 Hive 语法进行了扩展,使其它可以很方便的进行联邦查询。
首先我们看一下上图中间这条非常典型的 Hive SQL,它将几个表 join 一下,distribute by 再写到下游。注意看一下红色字,就是需要我们额外改造的内容,改造的成本非常低,只要在 Table 前面加上 Catalog 的那么就能读到不同 Catalog 的数据。比如说我们注册一个 PG Catalog,直接把 PG Catalog 的名字加到这个表的前面,我们就能读到 PG Catalog 的数据。
基于这样一层改造和扩展,我们就能使用 Hive 语法查到不同数据源的数据,再写到不同的数据存储。
04
Demo
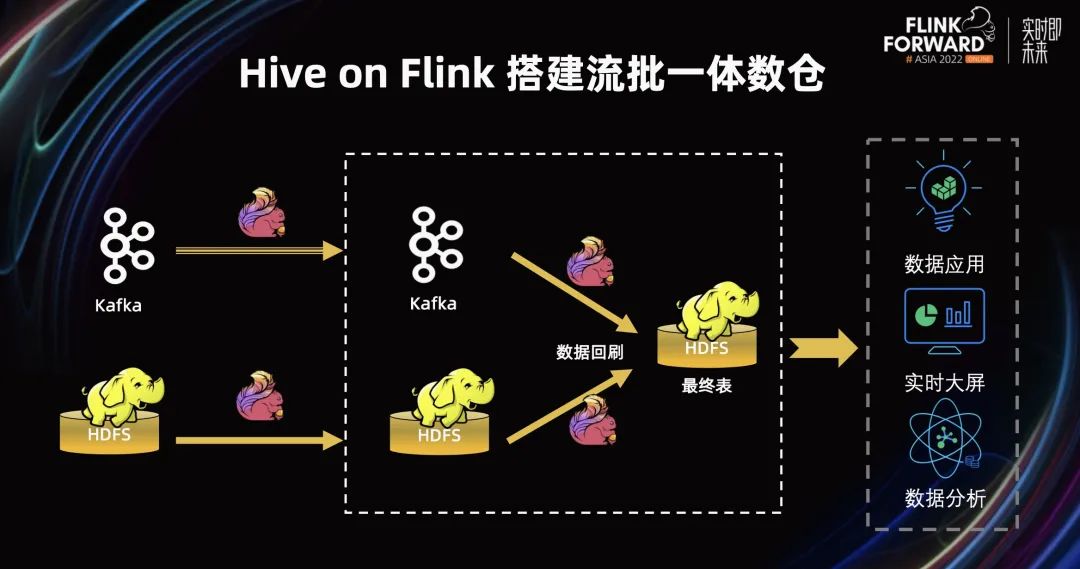
在传统的 Lambda 架构中,我们往往会有两条不同的 pipeline:
实时的 pipeline,我们往往通过 Flink 将 Kafka 的数据进行打宽聚合写入下游,并通过 Flink 写入 HDFS 的最终表。
离线的 pipeline,我们则可以通过周期性地调度 Flink 作业将数据写入到 HDFS 中。为了保持数据的正确性,在 Lambda 架构之中往往通过将批的结果回刷到 HDFS 中,保证数据的正确性。
当批作业回刷结束后,用户可以通过应用层分析最终表的结果,进行实时大屏地展示,做相关的数据应用以及分析数据之中潜在的趋势。
今天,我们则聚焦在数据回刷这一层,演示如何通过 Hive on Flink 构建流批一体引擎。
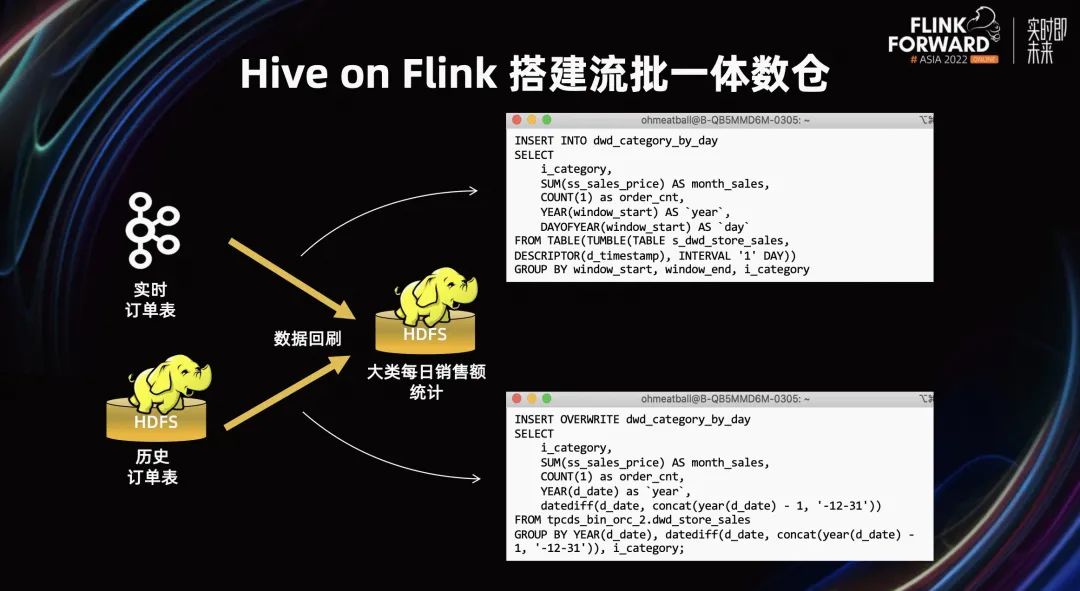
我们在 Kafka 中提前灌注了一些实时订单表,在 HDFS 中灌注了之前已经有的一些历史订单表。
实时链路中,我们通过 Window 语义,按天级别将统计信息直接灌入 HDFS 中,实时地获取当前的销售量。而离线链路中,我们则通过 agg 语法可以在第二天凌晨汇总当天的订单信息。通过数据回刷,我们就可以得到统一的每日销售额统计。
下面用 Zeppelin 演示 Hive SQL on Flink 构建流批一体数仓的 Demo。
demo 演示:
05
未来展望

以下是我们未来的一些规划:
在流批一体方面,虽然我们在这个版本已经做了极大的努力,但存储层仍然是不统一。比如在流上我们依旧使用 Kafka 作为中间结果的存放,在批上我们更倾向于使用 HDFS,因此存储层统一也是至关重要的。另外,Batch 的用户现在更倾向使用 Hive SQL 写作业,但我们更希望他们能将 Batch 作业全部迁移至 Flink Batch SQL 中来。所以,未来我们将不断提升 Batch SQL 的功能性。
在 Hive 的集成方面,主要分为以下 3 点:
优化读各种格式的文件,包括对读 Parquet 文件的嵌套列 PushDown、FilterPushDown 的优化等,从而提升性能。
提升写 Hive 端到端的生产可用性。比如,批模式下解决小文件多的问题。
根据用户的反馈不断加强 Hive 的语法支持。
在 Flink SQL Gateway 方面,它依旧处于起步的状态。我们将从以下三个方面来完善它:
SQL Client 支持向 SQL Gateway 提交 SQL,保证功能完整性。
补全认证功能,保证 SQL Gateway 基本生产可用。
基于 SQL Gateway 对接更多生态工具,增强 SQL Gateway 的应用范围。