
基于 Flink SQL 构建流批一体的 ETL 数据集成
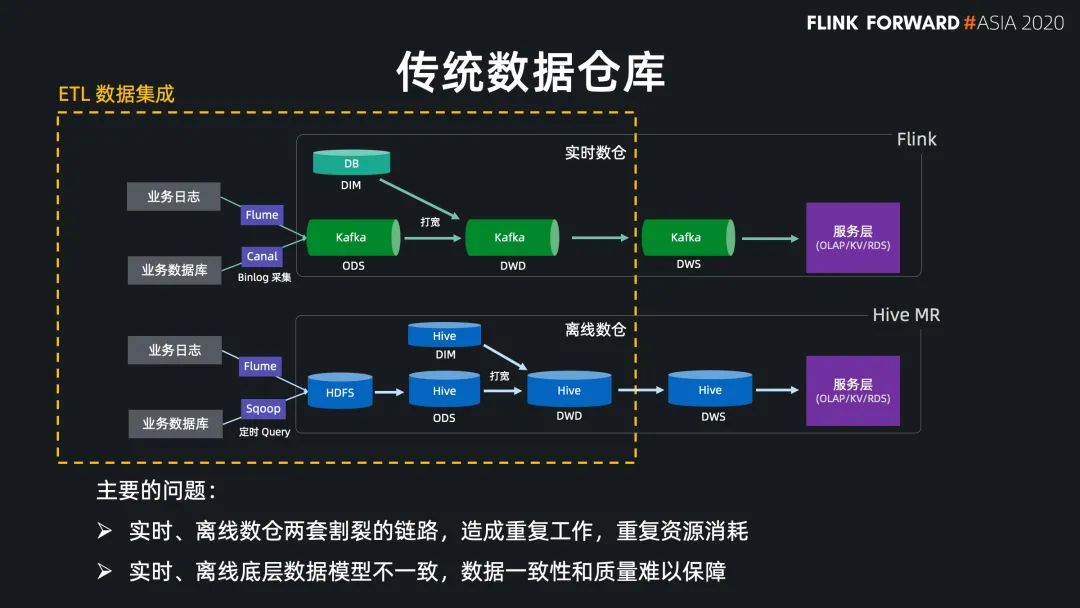
数据仓库与数据集成
数据接入(E)
数据入仓/湖(L)
数据打宽(T)
数据仓库与数据集成


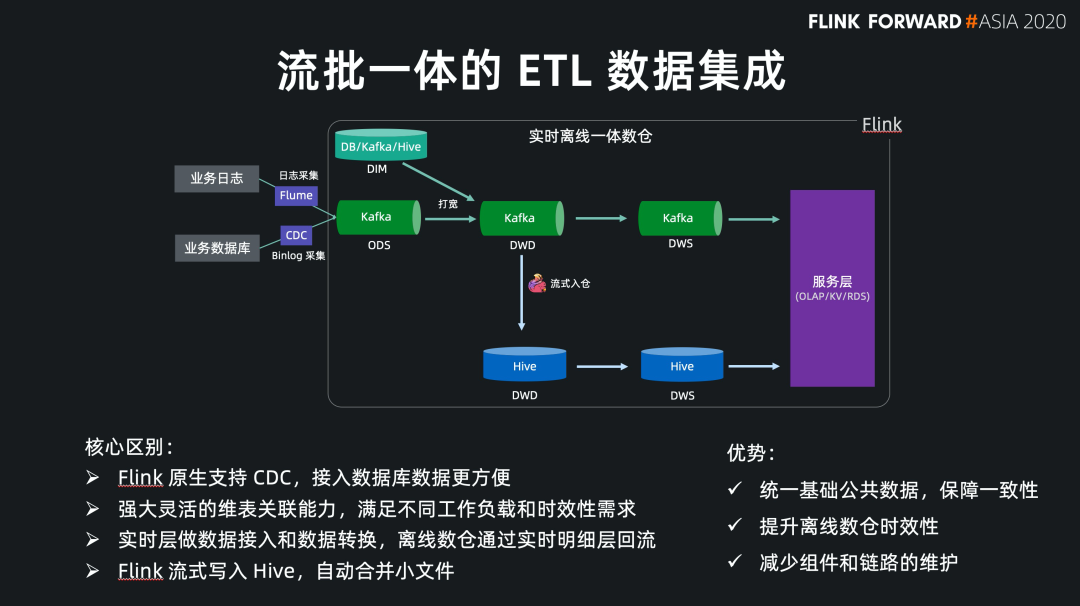
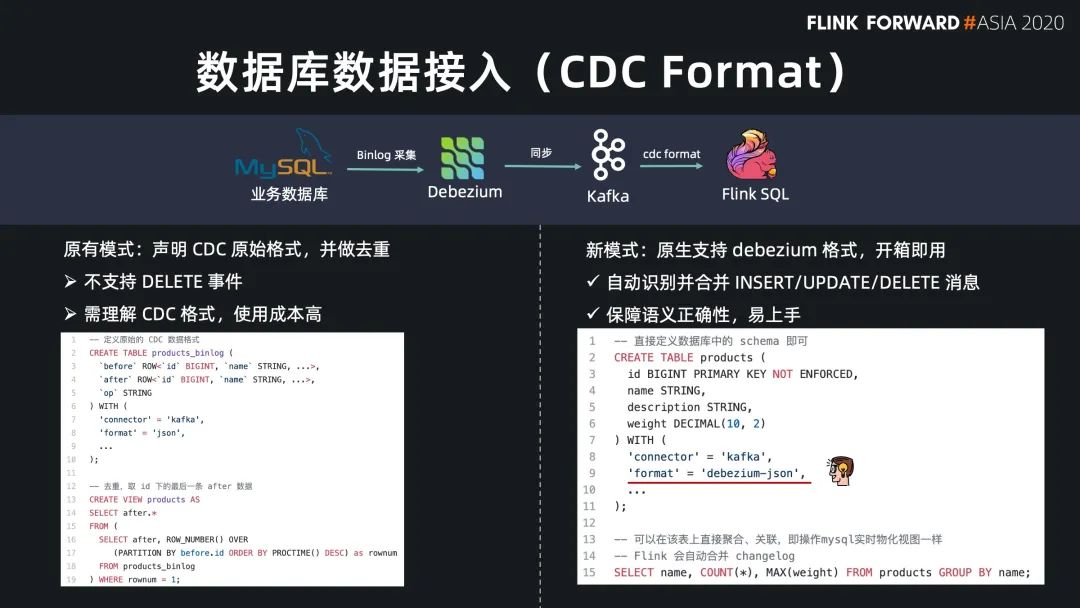
Flink SQL 原生支持了 CDC 所以现在可以方便地同步数据库数据,不管是直连数据库,还是对接常见的 CDC工具。
Flink SQL 在最近的版本中持续强化了维表 join 的能力,不仅可以实时关联数据库中的维表数据,现在还能关联 Hive 和 Kafka 中的维表数据,能灵活满足不同工作负载和时效性的需求。
基于 Flink 强大的流式 ETL 的能力,我们可以统一在实时层做数据接入和数据转换,然后将明细层的数据回流到离线数仓中。
现在 Flink 流式写入 Hive,已经支持了自动合并小文件的功能,解决了小文件的痛苦。
统一了基础公共数据 保障了流批结果的一致性 提升了离线数仓的时效性 减少了组件和链路的维护成本
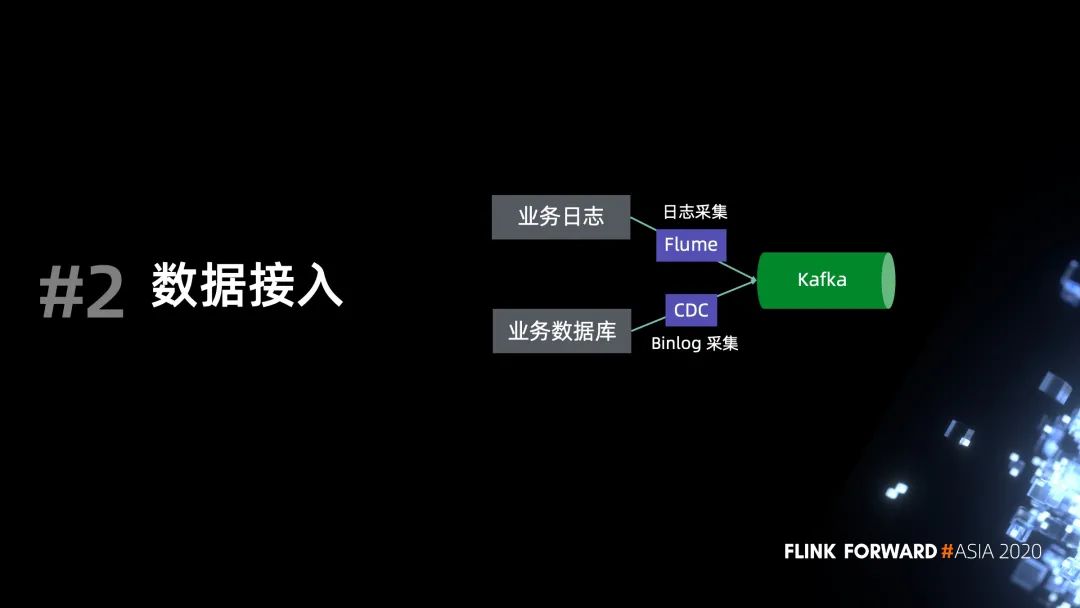
数据接入
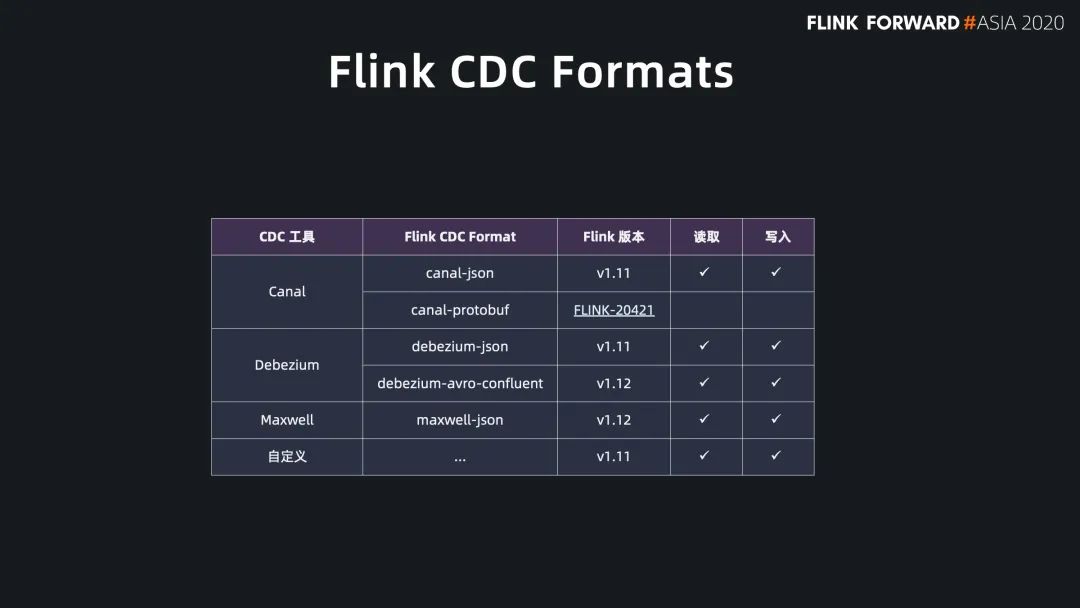
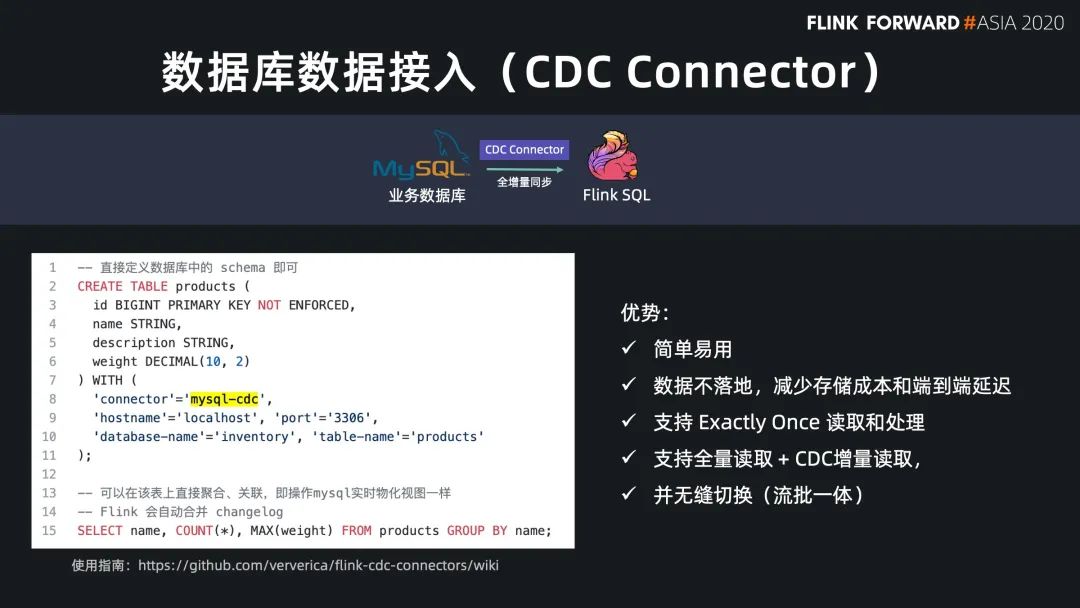


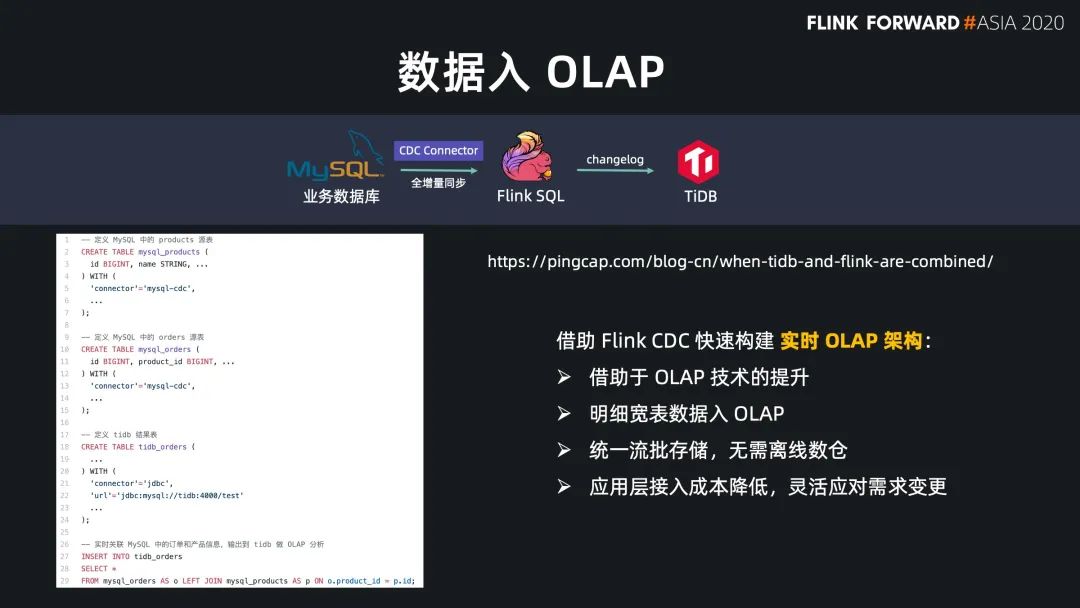
数据入仓湖
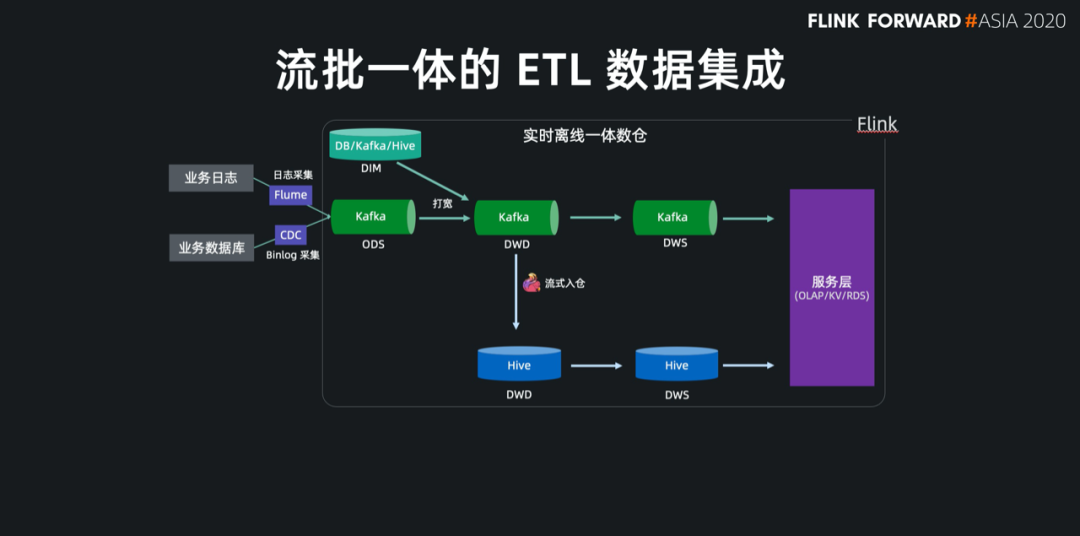
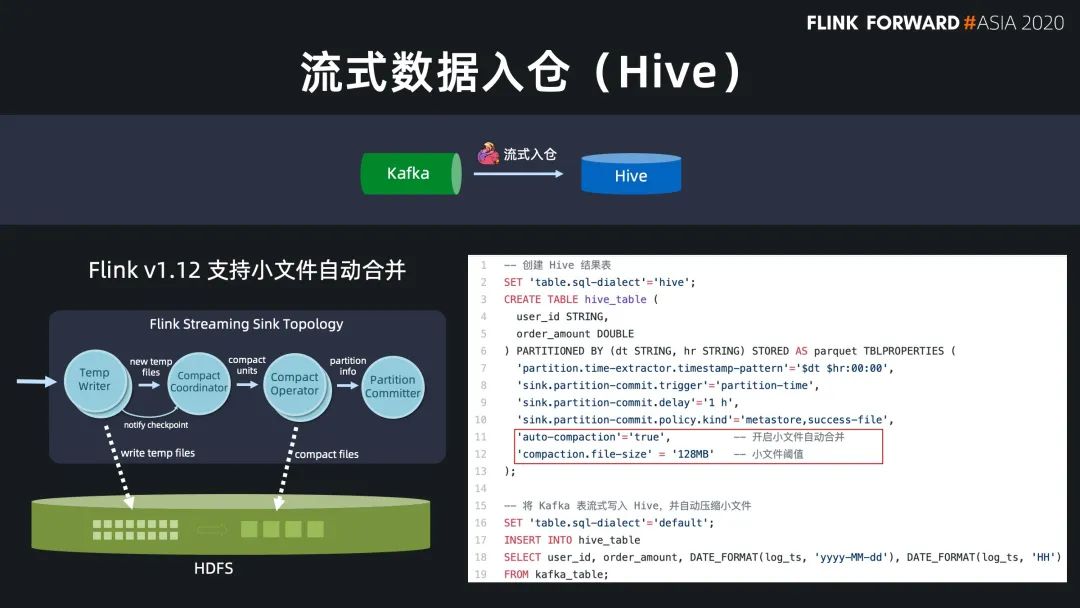


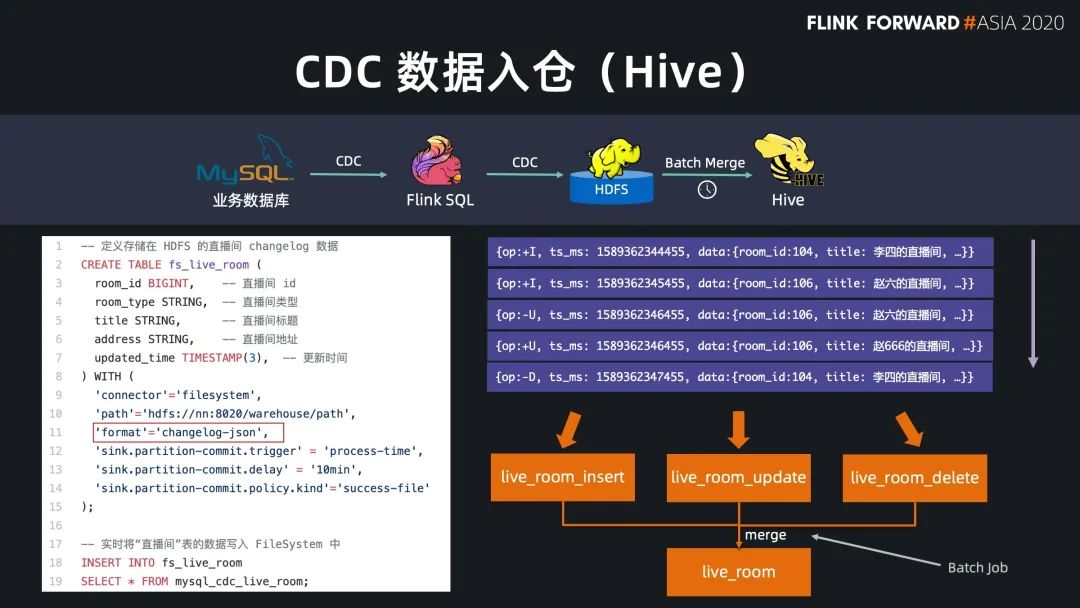
数据打宽


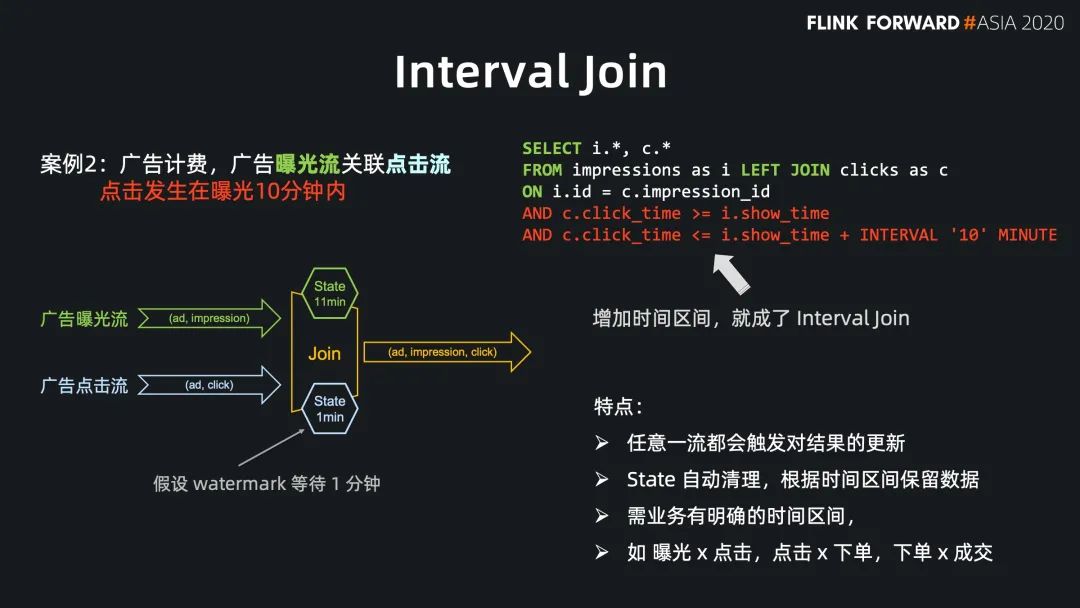


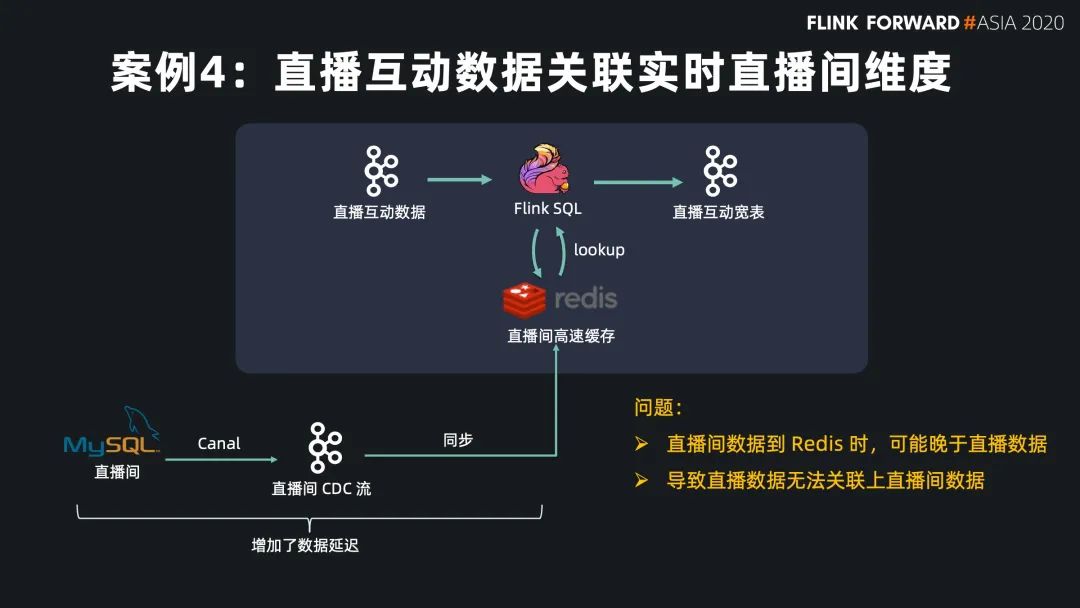

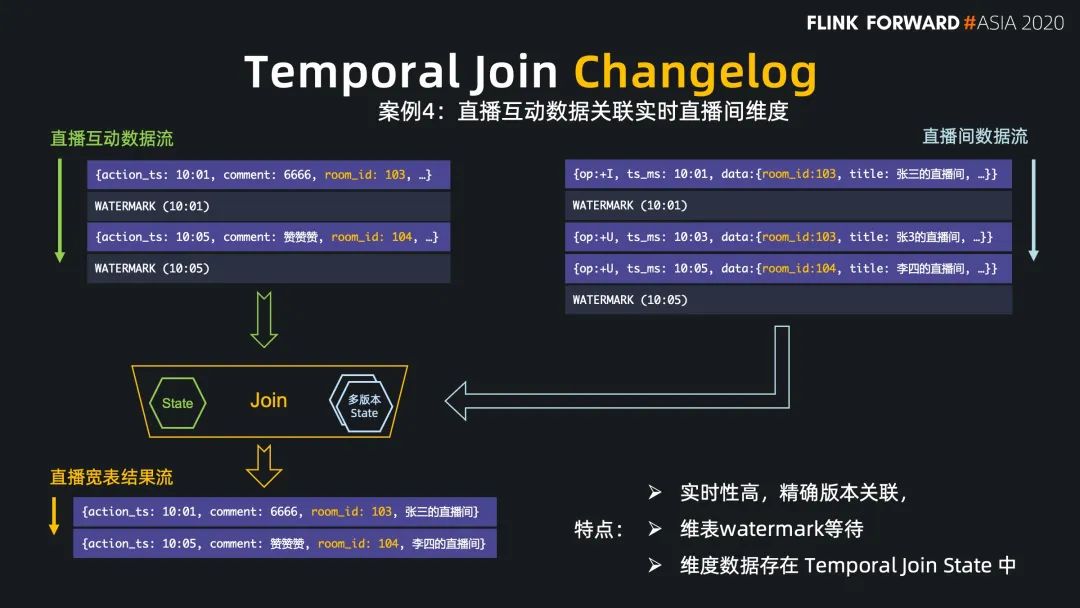
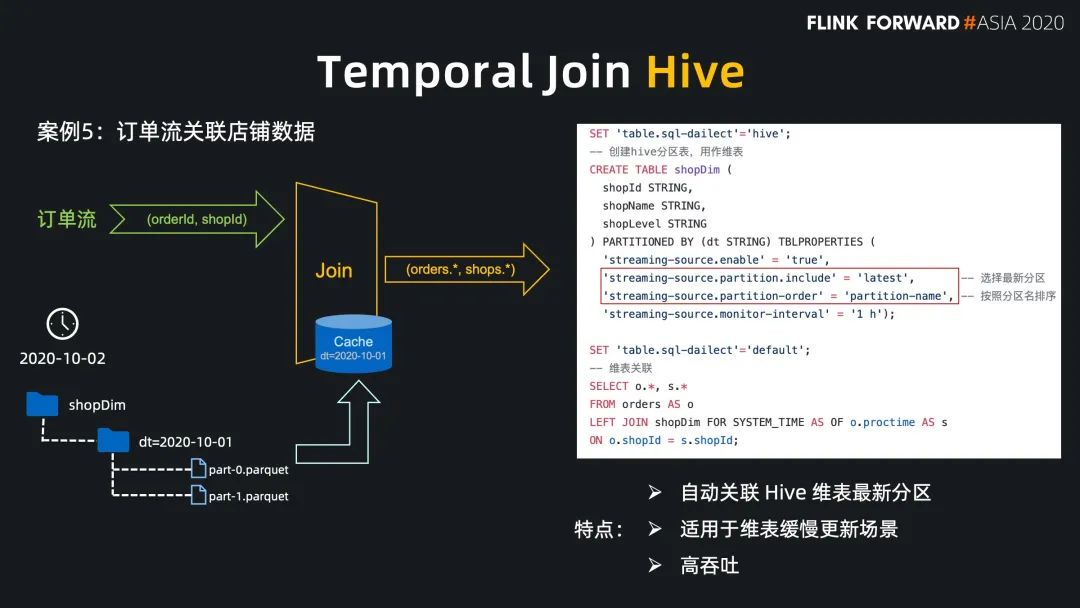
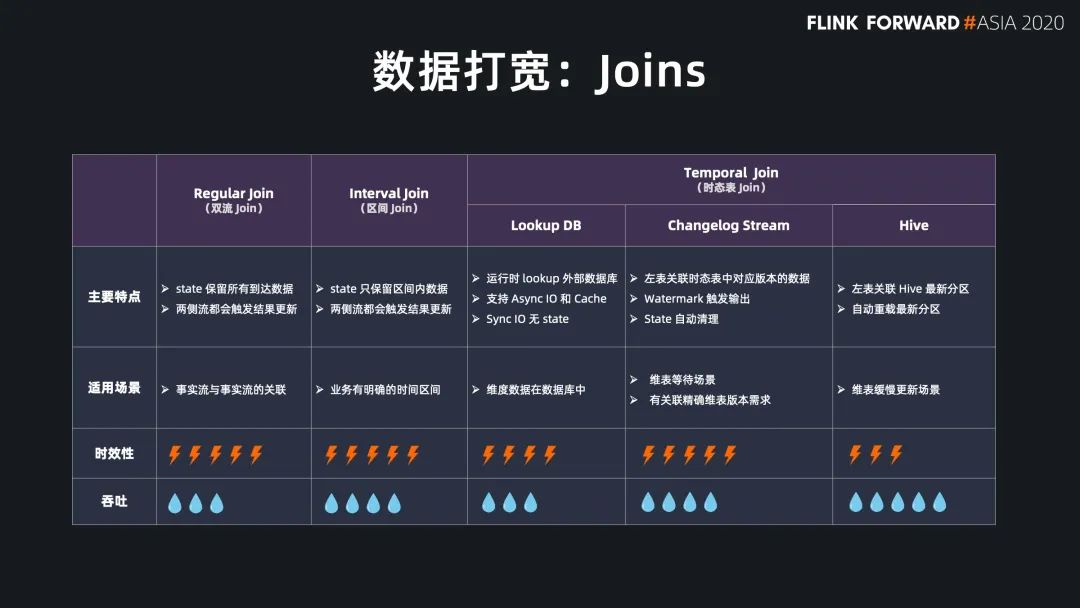
Regular Join 的实效性非常高,吞吐一般,因为 state 会保留所有到达的数据,适用于双流关联场景; Interval Jon 的时效性非常好,吞吐较好,因为 state 只保留时间区间内的数据,适用于有业务时间区间的双流关联场景; Temporal Join Lookup DB 的时效性比较好,吞吐较差,因为每条数据都需要查询外部系统,会有 IO 开销,适用于维表在数据库中的场景; Temporal Join Changelog 的时效性很好,吞吐也比较好,因为它没有 IO 开销,适用于需要维表等待,或者关联准确版本的场景; Temporal Join Hive 的时效性一般,但吞吐非常好,因为维表的数据存放在cache 中,适用于维表缓慢更新的场景,高吞吐的场景。
总结
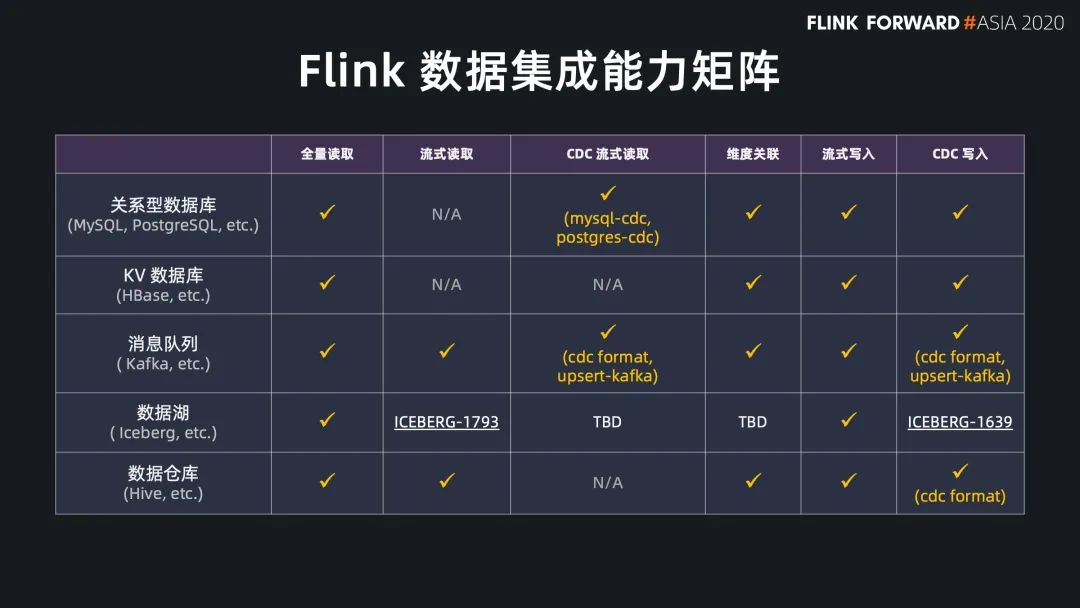
全量读取 流式读取 CDC 流式读取
维度关联;
流式写入 CDC 写入
评论