
AS-MLP:上海科技&腾讯优图开源首个检测与分割领域MLP架构
点击下方卡片,关注“AIWalker”公众号CV干货,第一时间送达

标题&作者团队
本文是上海科技大学在MLP架构方面的探索,它设计了一种轴向移位操作以便于进行空间信息交互。在架构方面,AS-MLP采用了类似PVT的分层架构,因为可以轻易的迁移到下游任务。所提方法在ImageNet数据集上取得了优于其他MLP架构的性能,在COC检测与ADE20K分割任务上取得了与Swin相当的性能。值得一提的是,AS-MLP是首个迁移到下游任务的MLP架构。注:CycleMLP与AS-MLP属于同一时期的工作,发到arxiv的时间也只差两天,说两者都是首个其实也可以。
paper: https://arxiv.org/abs/2107.08391
Code: https://github.com/svip-lab/AS-MLP
Abstract
本文提出了一种轴向移动架构AS-MLP(Axial Shifted MLP)用于不同的视觉任务(包含图像分类、检测以及分割)。不同于MLP-Mixer通过矩阵转置+词混叠MLP进行全局空域特征编码,我们在局部特征通信方向投入了更多的关注。
通过轴向移动特征信息,AS-MLP可以得到不同方向的信息流,这有助于捕获局部相关性。该操作使得我们采用纯MLP架构即可取得与CNN相同的感受野。我们还可以类似卷积核设置AS-MLP模块的感受野尺寸以及扩张因子。如此简单而有效的架构取得了优于其他MLP架构的性能,同时具有与Transformer架构(比如Swin Transformer)相当的性能,甚至具有稍少的FLOPs。比如,AS-MLP在ImageNet数据集上凭借88M参数量+15.2GFLOPs取得了83.3%top1精度,且无需额外训练数据。
此外,所提AS-MLP也是首个用于下游任务(如目标检测、语义分割)的MLP架构。AS-MLP在COC验证集上取得了51.5mAP指标,在ADE20K数据集上取得了49.5mIoU指标,具有与Transformer架构相当的性能。
Method

上图给出了本文所提AS-MLP-Tiny架构示意图,它以RGB图像
作为输入,然后将其拆分为非重叠
块,此时得到尺寸为
的词。由于AS-MLP具有四个阶段,每个阶段具有不同数量的AS-MLP模块。前述所得的所有词将被送入送入到这四个阶段,最终的输出特征将被用于分类。
阶段1包含一个线性嵌入层与多个AS-MLP模块,输出词的维度为
;阶段2先进行块合并将近邻
块进行合并得到尺寸为
的词,然后通过线性层映射为
并后接多个AS-MLP模块。阶段3与阶段4具有与阶段2相似的结构。
AS-MLP Block
下图给出了本文的核心模块的架构示意图,它主要包含Norm、Axial Shift操作、MLP以及残差连接。在Axial Shift操作中,我们采用通道投影、垂直移动、水平移动提取特征。
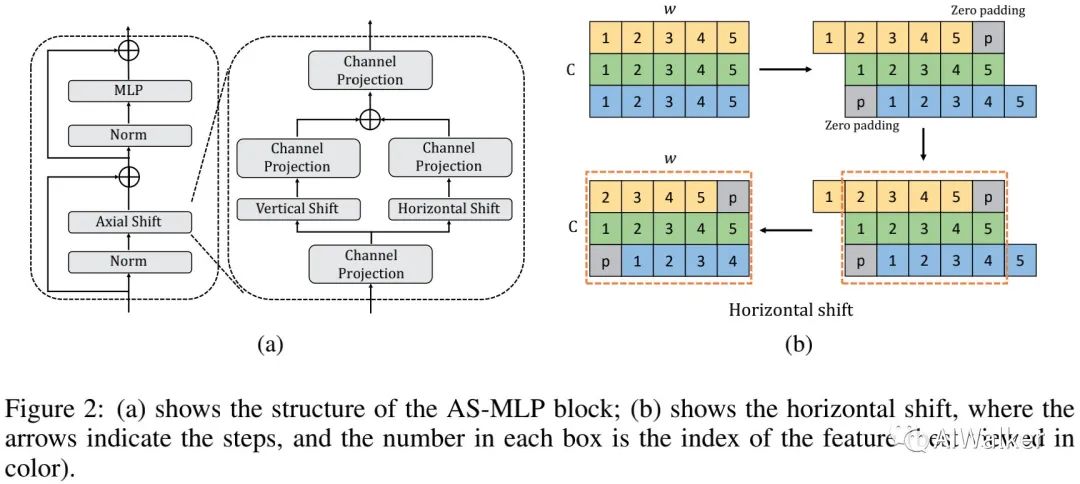
如上图b所示,我们以水平移动进行说明。假设输入尺寸为
,为方便起见,我们忽略了h并假设
。当移动尺寸为3时,输入特征被分为三部分,每部分分别沿水平方向移动
步长。注:此时我们采用了“zero-padding”。垂直移动操作与水平移动非常类似。
通过水平移动与垂直移动,特征可以进行了单一空间方向上的汇聚。在接下来的通道投影操作,两个方向的信息将进行汇聚。下图给出了本文所提AS-MLP实现code。

Comparisons between AS-MLP, Convolution, Transformer and MLP-Mixer
在这里,我们将AS-MLP、卷积、Swin以及MLP-Mixer进行对比分析。尽管这些模型是从不同角度出发设计得到,但它们均基于给定输出位置点,其值依赖于局部特征的加权。这些采样位置包含局部依赖与长距离依赖。

从上述对比图可以看到:
卷积是一种局部感受野的操作,更适合于提取具有局部依赖关系的特征;
Swin同样是一种局部感受野操作,Swin为自注意力机制引入了局部性提升了Transformer架构的性能,同时也降低了计算复杂度;
MLP-Mixer是一种全局感受野操作,它仅仅由矩阵转置与MLP操作构成;
AS-MLP是一种局部“十”字感受野操作,它可以更好的提取局部依赖关系。
Variants of AS-MLP Architecture
前面的Figure仅仅给出了Tiny版本的AS-MLP架构,参考DeiT与Swin,我们通过调整模块数与通道数构建了不同大小的模型。
AS-MLP-T:C=96,模块数:
;
AS-MLP-S:C=96,模块数:
;
AS-MLP-B:C=128,模块数:
;
Experiments
ImageNet Classification
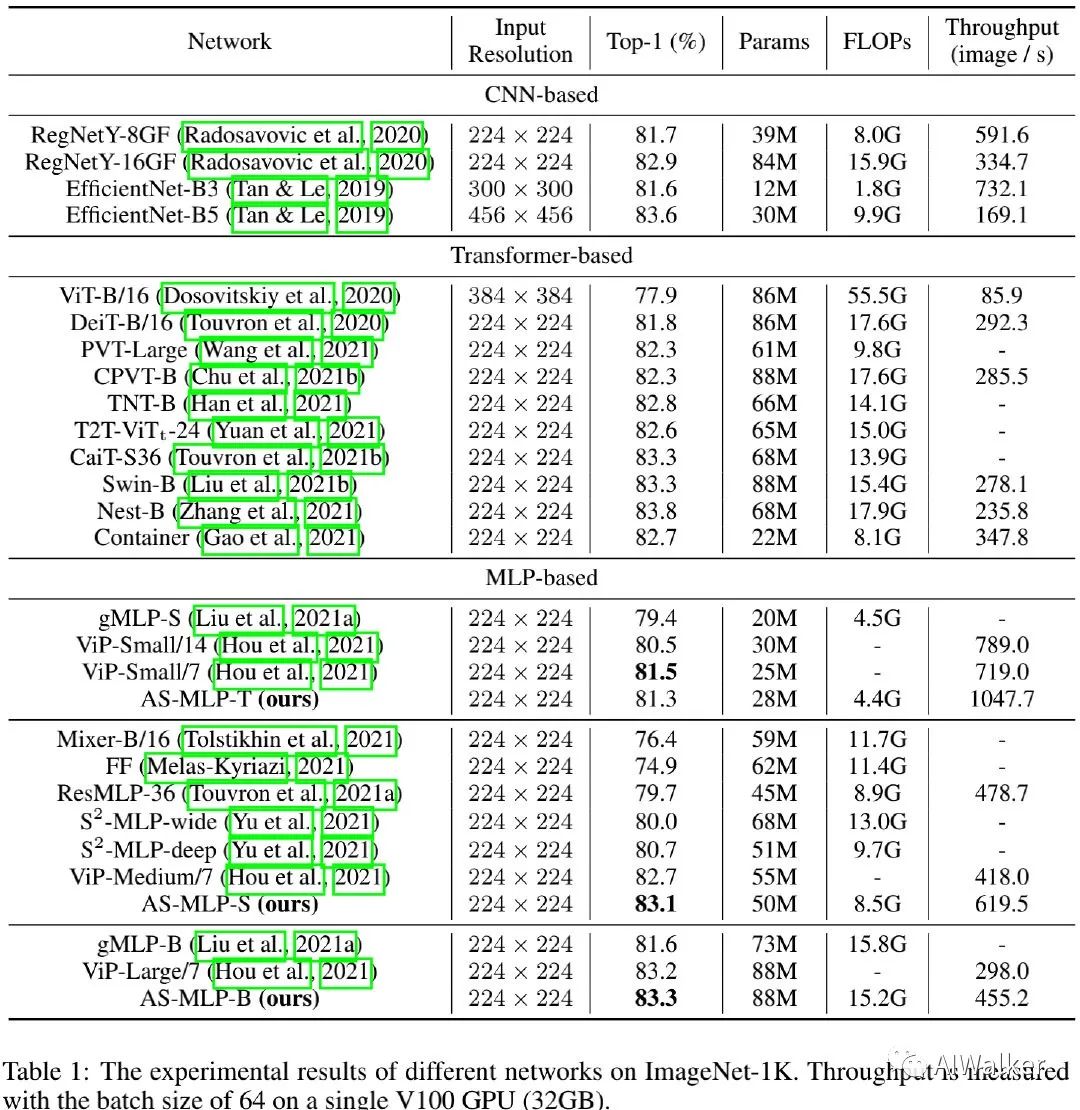
上表给出了所提方法在ImageNet数据上的性能对比,从中可以看到:
所提AS-MLP取得了比其他MLP架构更优的性能,同时具有相似的参数量与FLOPs;
AS-MLP-S取得了83.1%的top1精度同时具有比Mixer-B/16、ViP-Medium/7更少的参数量;
此外,AS-MLP-B取得了与Swin相当的性能:83.3%。

此外,我们还对比了端侧配置版本的AS-MLP,结果见上表。可以看到:在端侧配置下,所提方法大幅超越了Swin Transformer。
COCO Detection
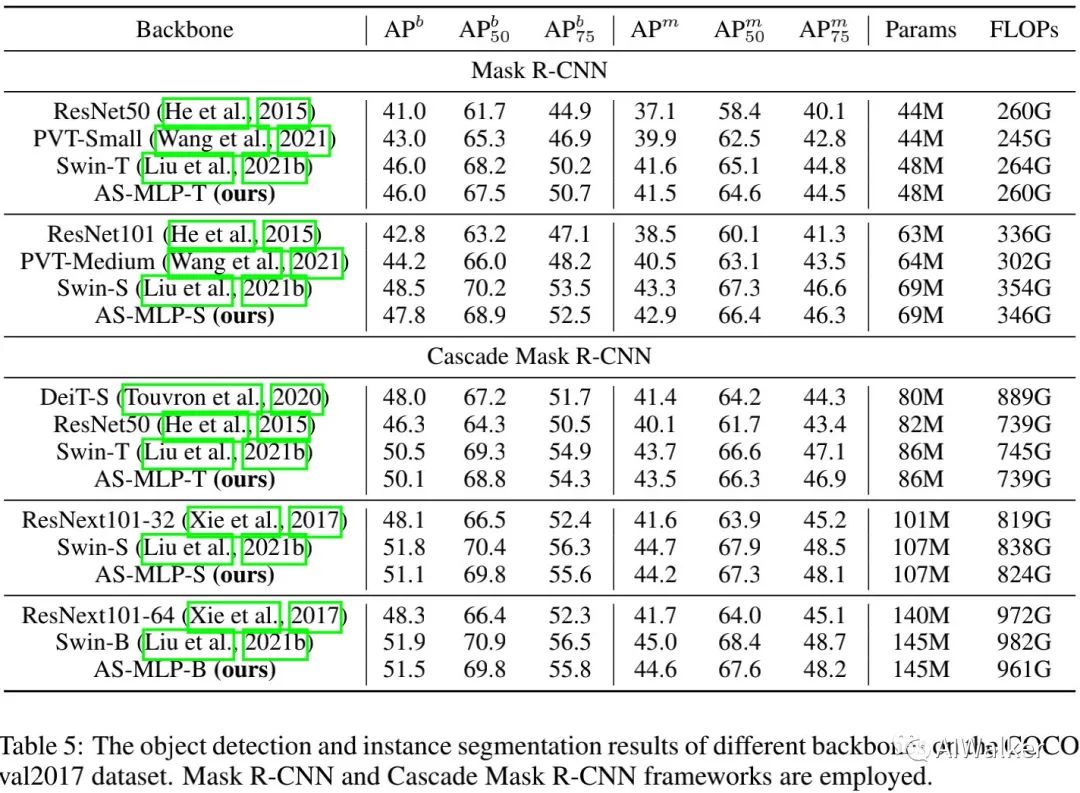
上表对比了COCO检测任务上的性能对比,可以看到:
所提AS-MLP是首个用于下游任务的MLP架构;
所提AS-MLP取得了与Swin相当的性能。具体来说,在Cascade Mask R-CNN+Swin-B取得了51.9AP指标,参数量为145M;而AS-MLP-B取得了51。5AP指标,参数量为145M。
ADE20K Segmentation
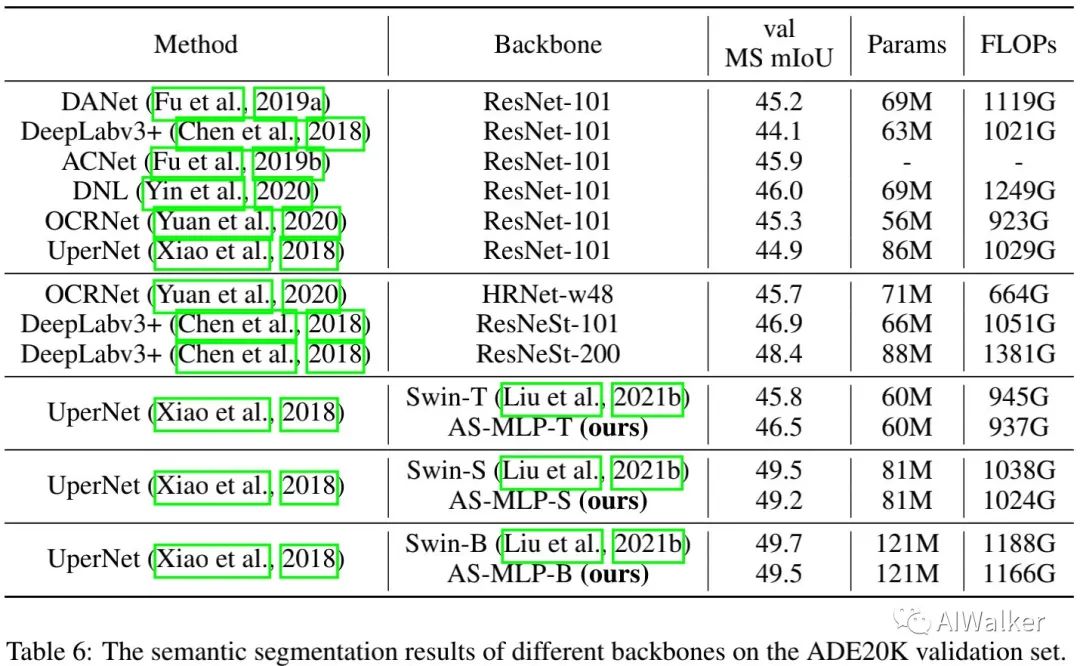
上表给出了ADE20K分割任务上的性能对比,从中可以看到:
所提AS-MLP同样是首个用于分割任务的MLP架构;
AS-MLP-T取得了比Swin-T等有的性能,同时具有稍少FLOPs;
UperNet+Swin-B取得了49.7mIoU,参数量为121M,计算量为1188GFLOPs;而UperNet+AS-MLP-B取得了49.5mIoU,参数量121M,计算量为1166GFLOPs。
Ablation Study
AS-MLP的核心是轴向移动,接下来我们将对其不同成分进行消融分析,所有试验均基于AS-MLP-T实现。
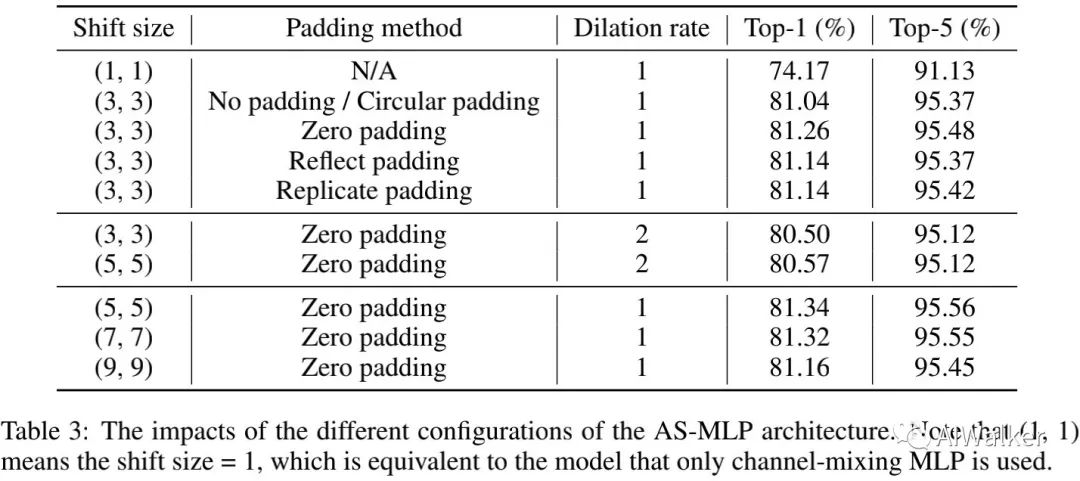
上表对比了不同padding方式、不同移动尺寸以及不同扩展比例的性能对比,从中可以看到:
zero-padding更适合于AS-MLP设计;
提升扩张因子会轻微降低模型性能;
提升移动尺寸,模型精度会先上升后下降。
基于上述分析,我们采用shift=5,zero-padding,dilation=1。
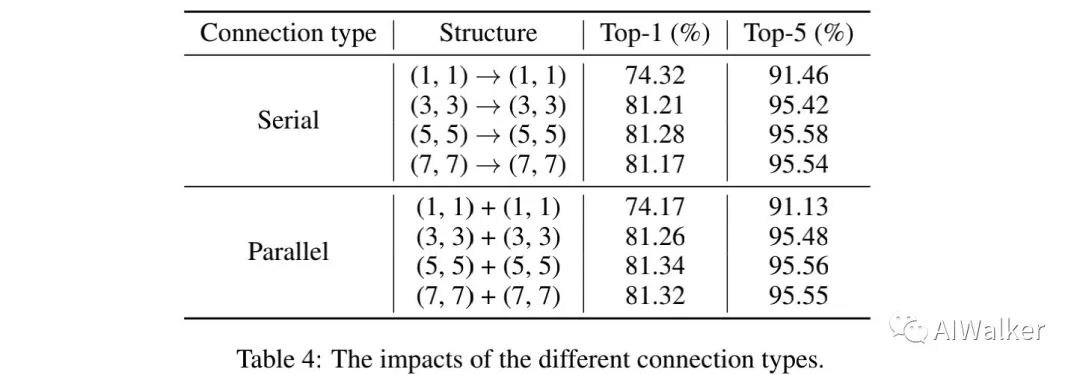
我们同时还比较了AS-MLP模块的不同链接类型,结果见上表,从中可以看到:在不同移动尺寸下,并行连接总是具有比串行连接更佳性能。
Comparsion with S2MLP
在初看到该文时,第一感觉这个与百度的那篇S2MLP(见下图核心模块)真的非常相似,都是采用了垂直、水平移位方式进行空间信息交互,而且还都是上下左右四个方向。可惜AS-MLP并未与S2MLP进行对比,反而比较晚(指的是见刊arxiv)的ViP进行的对比。

既然提到了,我们还是对S2MLP与ASMLP进行一下对比吧。
在整体架构方面,AS-MLP采用了类似PVT的分层架构,而S2MLP一文则是采用了类似ViT的柱状架构;
在应用方面,AS-MLP即可应用于图像分类,还可以迁移到下游任务中;而S2MLP则仅适用于图像分类,并不适用下游任务;
在核心模型方面,AS-MLP采用并行垂直、水平移动,分别进行特征汇聚后再进行特征相加汇聚;而S2MLP则采用分组方式,不同组进行不同方向的移动,然后再进行空间信息汇聚;
在模型性能方面,AS-MLP取得了与Swin相当的性能,比ViP更优的性能;而S2MLP的性能则弱于Swin与ViP;
最后一点,AS-MLP开源了,但S2MLP并未开源。
推荐阅读

其实书童是一个集算法、实践、论文以及Transformer于一身的公号(往期索引大全)

详细解读PVT-v2 | 教你如何提升金字塔Transformer的性能?(附论文下载)

简单有效 | 详细解读Interflow用注意力机制将特征更好的融合(文末获取论文)
长按扫描下方二维码添加小助手并加入交流群,群里博士大佬云集,每日讨论话题有目标检测、语义分割、超分辨率、模型部署、数学基础知识、算法面试题分享的等等内容,当然也少不了搬砖人的扯犊子
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
