
数据仓库: 你知道这6种类型维度吗
正常维度(Normal Dimension)
- 该维度表属性跟实体相关,具有唯一标识,可根据外键访问其他依赖属性
正常维度是当所有属性都相关时(它们全部涉及一个实体,例如:商品),它具有业务唯一标识(自然主键),并且所有属性都依赖于代理主键,例如:
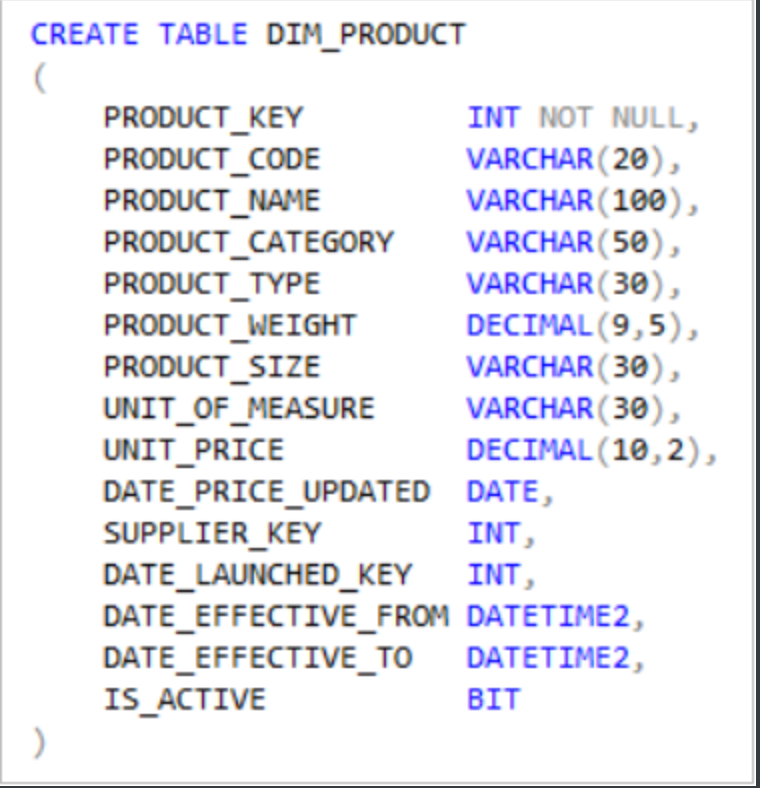
上面的DIM_PRODUCT,产品的组件为PRODUCT_CODE。有时,在表中可以找到一个创建日期的日期属性(在上面的示例中为DATE_PRICE_UPDATED,有时是一个替代键(在上面的示例中为DATE_LAUNCHED_KEY)。另一个雪花型维度建模示例是SUPPLIER_KEY,通过该外键能够访问存储在DIM_SUPPLIER中的所有供应商属性。
垃圾维度
在垃圾维度中,属性互不相关。假设事务/源系统中的源表有4到8列,每列有2到6个值(有些是Yes / No列)。这些列彼此不相关,也不是很大的属性。这些列中的大多数解释了事实表本身。例如,电商网站中有一个支付表。支付表有订单ID列、 客户ID列、实际付款日期、付款金额、付款方式等。但是该表还有以下列:是否使用积分、是否使用优惠券和是否为秒杀订单。这些列均为「是/否」列。
这样我们就可以创建一个垃圾维度:
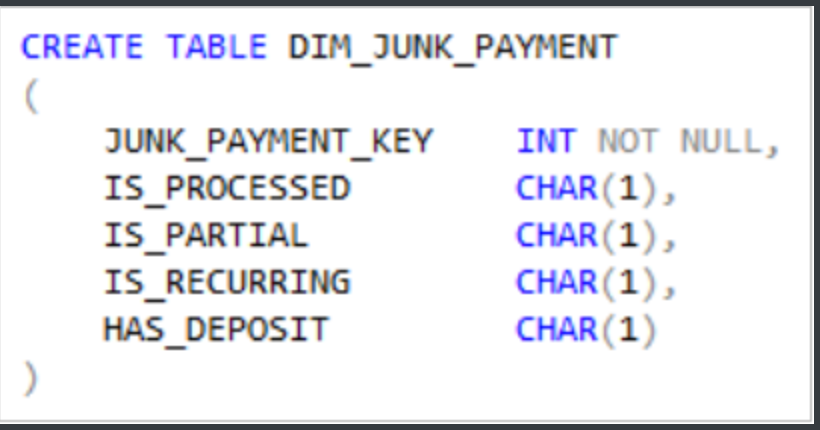
注意:
- 垃圾维度始终是静态,就是维度表的数量是固定的。
- JUNK直接跟在DIM_后面。对于Y / N列,使用“ IS_…”或“…_FLAG”进行命名。
- 数据类型是一致的,即对于Y / N列,它可以是bit或CHAR(1),但不能是INT或VARCHAR(N)
- 优先选择CHAR(1)
- 垃圾维度是没有业务主键的
- 扩展垃圾维度:
- 如果我们向垃圾维度添加一列,会发生以下情况。上面的垃圾维度有9行,即4个Y / N列的组合为8行(4 * 2),外加未知行。注意理解:每一个列Y/N,不与其他列组合。
- 如果再添加1个Y / N列(例如IS_REFUNDABLE),则行数变为17,即对于现有的8行(不是未知行),将IS_REFUNDABLE设置为N。然后将现有的8行复制到第10 -17行,IS_REFUNDABLE为Y。注意理解:需要保证之前的维度数据依然有效,只是行政的这一列不起作用。可以想象下如果用该维度表关联事实表,如果关联出来的新列是Y,显然数据是错误的。
- 在事实表中,有JUNK_PAYMENT_KEY列,包含值0到17。
- 垃圾维度的列值也是可以被扩展的,例如:IS_PROCESSED列是Y / N列,但现在它还有第三个值U(未知)。
“
垃圾维度中的属性是属于事务(源表)级别(或事实表涉及的内容),并不是维度级别。
”
分割维度
当一个维度预计会很大时,例如:有5000万行,出于性能原因,我们可以将维度分为两个或三个。
拆分始终是垂直的,即某些列放入到维表1,有些列放入到维表2。例如,将客户详细信息放入dim_customer_contact,将与订单处理相关的客户属性放入dim_customer_order,将相关客户属性营销,促销和忠诚度计划已纳入dim_customer_marketing。
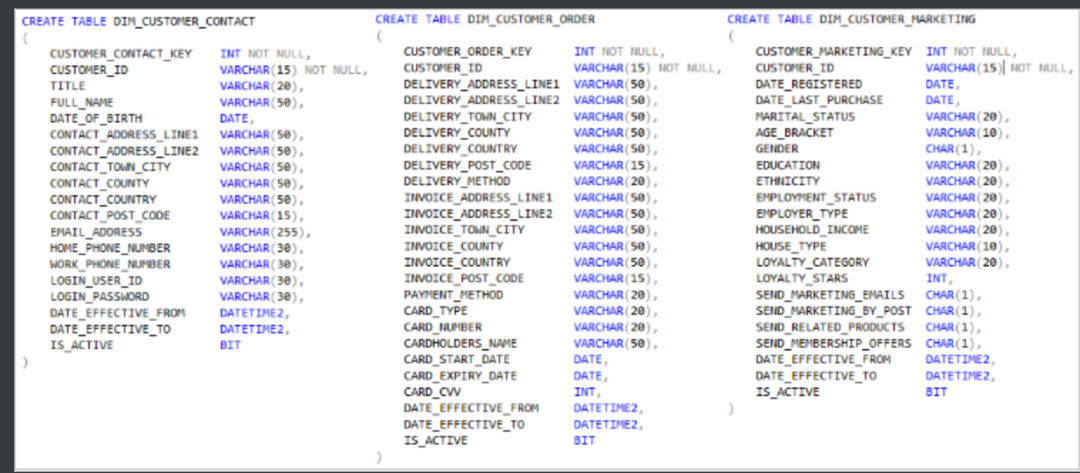
每个维度中的相关行具有相同的业务主键(自然主键),这种情况肯定是不能使用代理主键的。
文本维度
文本维度没有业务主键的。如果源事务表的文本列较窄(例如10至20个字符),并且该列不在维级别上,而是在事实表级别上,则将其保留在事实表中。例如:订单ID,交易ID,付款ID。但如果源事务表具有宽文本列,例如varchar(255)或varchar(800),有两种设计选择。
-
将此varchar列放在一个维度(称为“文本维度”)中。
-
将其保留在事实表中。
例如:一些注释列,交易描述列或订单描述列
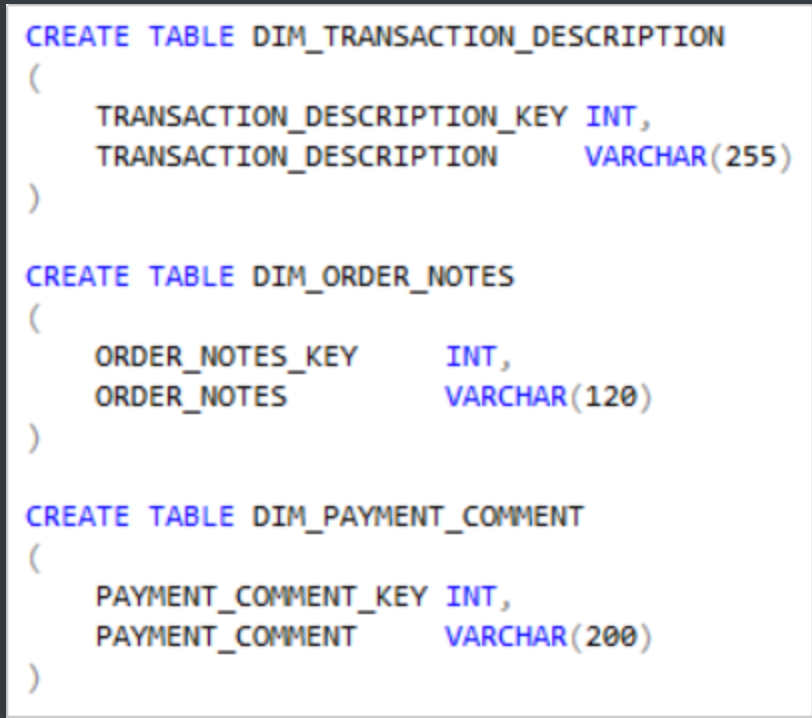
- 选择哪种设计方式有几个注意事项:
-
文本列的长度和值重复度。文本越长,将其单独放在一个维度中是明智的,尤其是在事实表很大的情况下。
-
如果此varchar列中的值具有很高的可重复性,可以单独放在维度表中,节省空间。性能也一样,因为大多数访问事实表的查询都与text列无关。
-
如果文本列的长度为20-70个字符,并且可重复性非常低(例如1.2的倍数),则可以将该文本列保留在事实表中是合理的。
-
如果在源表中有两个注释/注释列,则最好创建两个文本维度,而不是将它们合并为一个文本维度
(1). 功能清晰–事实表中的不同替代键描述它们是什么
(2). 查询性能–维度表的行数较少,合并时避免了笛卡尔积性能低下
堆叠维度
堆叠维度是将两个或多个维度合并为一个维度的维度,如下所示:

-
堆叠的维度仅具有一个或两个属性,而且始终是不更新的。
-
不建议使用堆叠尺寸。但在实际开发中,堆叠维度确实存在。通常因为它与源系统中的类似,所以很多人只是将其复制到数据仓库中。我们经常会遇到一些类型和状态列:客户状态、产品类型、商铺类型、安全性类型、安全性类别、经纪人类型等。所有这些列均应具有各自的维度,因为它们确实是该属性尺寸。
-
但是有类型和状态列是事实表的属性,例如:事务类型或事务状态。要将交易类型和交易状态合并为一个维度,可以使用垃圾维度。尽量避免使用像这样的堆叠尺寸。
不同属性维度
最后一种类型是独特的属性维,其中所有属性都是事实表本身的属性。例如,考虑一个基金管理中的持有表,其中每个基金,证券和日期的颗粒都是一行。每个证券都具有许多属性,例如部门,等级,国家,货币,资产类别等。证券的示例包括债券,股票,CDS,IRS,期权,期货。从理论上讲,这些属性在各个基金中是一致的。但是事实并非如此,因为可能会被更新。
在正常情况下,部门,等级,国家,货币和资产类别都是安全维度的属性。它们实际上是持有事实表的属性。为了正确存储它们,应该创建一个独特的属性维,如下所示:
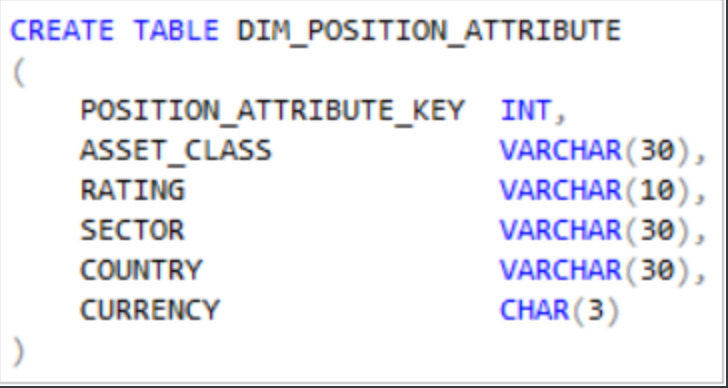
上面的示例比较简单,实际上,这种维度中的属性有可能会是几十个。顾名思义,以上维度包含一个独特的属性列表。并非所有可能的值,而是仅事实表中实际存在的值。这种维表没有业务ID。所有属性都是事实表的属性,而不是特定维度的属性。
一个不同属性维度可以在物理上分为两个或三个。这是一个垂直拆分,类似于之前的拆分维度,基于属性的逻辑分组。拆分它的目的是减少行数,从而提高查询性能。从某种意义上说,这就像一个垃圾维度,但是覆盖了更广泛的属性范围,即50-60列而不是3-5列。