
漫谈数据仓库之维度建模

- 前言 -
- 概述 -
以Hadoop、Spark、Hive等组建为中心的数据架构体系。 各种数据建模方法,如维度建模。 调度系统、元数据系统、ETL系统、可视化系统这类辅助系统。
- 目录 -
先介绍比较经典和常用的数据仓库模型,并分析其优缺点。 详细介绍维度建模的基本概念以及相关理论。 为了能更真切地理解什么是维度建模,我将模拟一个大家都十分熟悉的电商场景,运用前面讲到的理论进行建模。 理论和现实的工作场景毕竟会有所差距,这一块,我会分享一下企业在实际的应用中所做出的取舍。
- 经典数据仓库模型 -
一、实体关系(ER)模型
需要全面了解企业业务和数据; 实施周期非常长; 对建模人员的能力要求也非常高。
二、维度模型
三、DataVault
四、Anchor模型
- 维度建模 -
二、维度建模的基本要素
发生在现实世界中的操作型事件,其所产生的可度量数值,存储在事实表中。从最低的粒度级别来看,事实表行对应一个度量事件,反之亦然。

每个维度表都包含单一的主键列。维度表的主键可以作为与之关联的任何事实表的外键,当然,维度表行的描述环境应与事实表行完全对应。维度表通常比较宽,是扁平型非规范表,包含大量的低粒度的文本属性。
- 实践 -
一、业务场景
电商网站中最典型的场景就是用户的购买行为。 一次购买行为的发起需要有这几个个体的参与:购买者、商家、商品、购买时间、订单金额。 一个用户可以发起很多次购买的动作。
- 模型设计 -
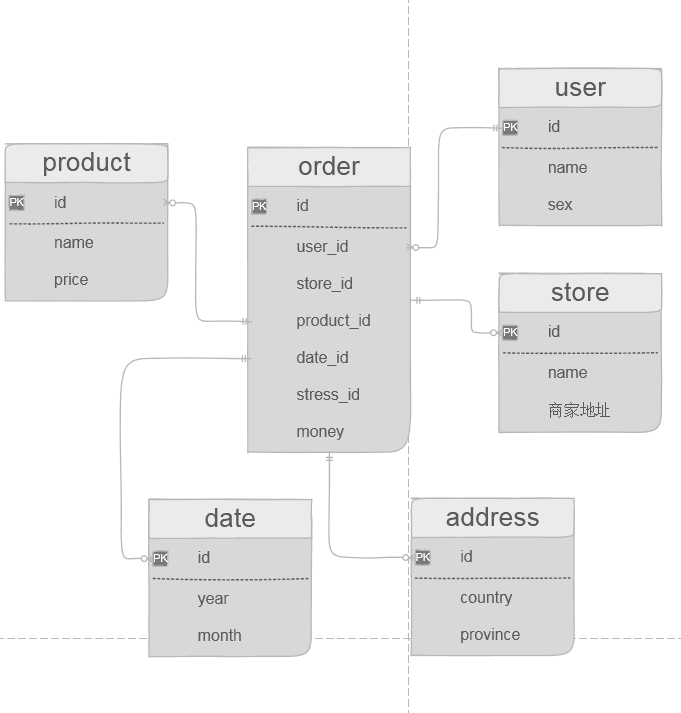

数据冗余小(因为很多具体的信息都存在相应的维度表中了,比如用户信息就只有一份); 结构清晰(表结构一目了然); 便于做OLAP分析(数据分析用起来会很开心); 增加使用成本,比如查询时要关联多张表; 数据不一致,比如用户发起购买行为的时候的数据,和我们维度表里面存放的数据不一致。
业务直观,在做业务的时候,这种表特别方便,直接能对到业务中; 使用方便,写sql的时候很方便; 数据冗余巨大,真的很大,在几亿的用户规模下,他的订单行为会很恐怖; 粒度僵硬,什么都写死了,这张表的可复用性太低。
- 使用示例 -
SELECT
SUM(order.money)
FROM
order,
product,
date,
address,
user,
WHERE
date.year = '2016'
AND user.sex = 'male'
AND address.province = '帝都'
AND product.name = 'LV'
- 总结 -
作者:dantezhao
来源:https://segmentfault.com/a/1190000009025573

评论