
数据仓库缓慢变化维度SCD?你想知道的都在这里
点击上方蓝色字体,选择“设为星标”





大家知道平时我对SQL Boy & Girl 有很深的成见,原因在于数据仓库本身博大精深,但是很多开发人员在用数据分析师的角色要求自己的开发能力。就像王者荣耀你本身是个刺客,输出连个肉坦都比不过,怎么好讲自己是个刺客呢?
言归正传,今天我们要讲的是数据仓库中的缓慢变化维度(SCD)。
缓慢变化维度 SCD
Slowly Changing Dimensions are dimensions that have data that slowly changes. 意思就是说数据会发生缓慢变化的维度就叫”缓慢变化维”。
举个例子,假设我们有一张我们公司的销售员维度表如下,记录了每个销售员的一些基本信息,那么随着时间的变化销售员可能会在各省公司间调岗,如将周杰伦调入北京分公司,针对这种变化,业务系统会直接将业务数据库中周杰伦的地址直接update为北京,而不会考虑历史变化,不过在数据仓库中由于有时我们需要进行历史变化分析,或者防止销售数据记录错误,所以需要对这种变化进行相应的处理。
很显然在业务数据库中数据的变化是非常自然和正常的,比如顾客的联系方式,手机号码等信息可能随着顾客的所在地的更改发生变化,比如商品的价格在不同时期有上涨和下降的变化。那么在业务数据库中,很自然的就会修改并马上反映到实际业务当中去。但是在数据仓库中,其数据主要的特征一是静态历史数据,二是少改变不删除,三是定期增长,其作用主要用来数据分析。因此分析的过程中对历史数据就提出了要求,有一些数据是需要能够反映出在周期内的变化历史,有一些数据不需要,那么这些数据应该如何来控制。
处理缓慢变化维度是Kimball数仓体系中永恒的话题,因为数据仓库的本质,以及维度表在维度建模中的基础作用,我们几乎总是要跟踪维度的变更(change tracking),以保留历史,并提供准确的查询和分析结果。在《The Data Warehouse Toolkit, 3rd Edition》一书的第5章,Kimball提出了多种缓慢变化维度的类型和处理方法,其中前五种是原生的,后面的方法都是混合方法(hybrid techniques),因此下面来看看前五种,即Type 0~Type 4。
Type0 保留原始值
某一个属性值绝不会变化。事实表始终按照该原始值进行分组。比如在用户维度表中,用户注册时使用的原始用户名(original_user_name)。如果它发生变化,那么变化后的值是无效的,会被抛弃,始终按照用户第一次填写的数据为准。很明显这种方式是不推荐的。
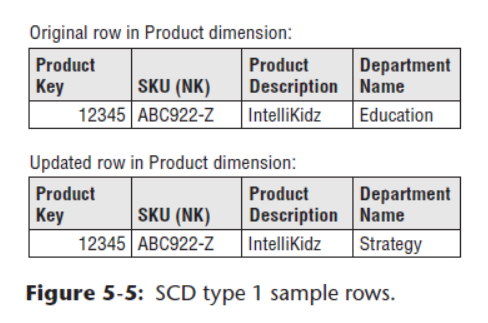
Type1 覆盖更新
与业务数据保持一致,同样为直接update。这样就难以记录历史变化,例如如果周杰伦于15年7月调入北京,那么我们想要知道北京销售员在15年的销售数据时,就会将周杰伦的业绩算入北京分公司下,实际上周杰伦7月份以前的销售数据均应算在台北,所以为了避免这样的问题就有了TYPE2的处理方式。
书中给出的例子:
Type2 增加新的列
数据仓库系统的目标之一是正确地表示历史记录。我们在生产环境中的基于Hive的数仓建设过程中,拉链表就是直接的体现。
这种类型在维度表中添加两个辅助列:该行的有效日期(effective date)和过期日期(expiration date),分别指示该行从哪个时间点开始生效,以及在哪个时间点过后会变为无效。每当一个或多个维度发生更改时,就创建一个新的行,新行包含有修改后的维度值,而旧行包含有修改前的维度值,且旧行的过期日期也会同步修改。书中的例子如下:
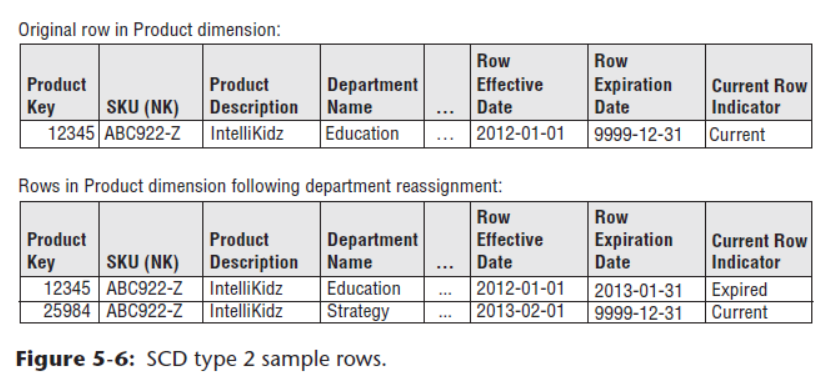
在上图中,当前有效列(current列)的过期日期会被记录为9999-12-31。当Department Name维度变化时,旧有的Product Key为12345的行的过期日期被更新为修改日期,并且新建了一个Key为25984的行,包含新的数据。
需要注意的是,这里的Product Key是所谓代理键(surrogate key),即不表示具体业务含义,而只是代表表内数据行的唯一ID。在处理SCD时,代理键可以直接用来区分同一自然键(natural key)的数据的新旧版本。上图中的SKU就是自然键。
这种类型的SCD处理方式能够非常有效且精确地保留历史与反映变更,但缺点是会造成数据的膨胀,因为即使只有一个维度变化,也要创建新行。
Type3 新增属性列
用不同的字段来保存不同的值,就是在表中增加一个字段,这个字段用来保存变化后的当前值,而原来的值则被称为变化前的值。我们举个很简单的例子,例如我们在用户表中的用户住址这一列会变化,那么我们可以通过新增一个列来表示曾经的地址:
原来的表:

现在我们新增一列pre_location来表示用户的上一个住址:

这么做虽然解决上面的数据膨胀的问题,但是如果很多个列都会变化,那么我们要新增很多系列,显然这是不合理的。另外,这种做法只能保留上一次的数据,那么更久远的变化就丢失了。
Type4 新增维度表
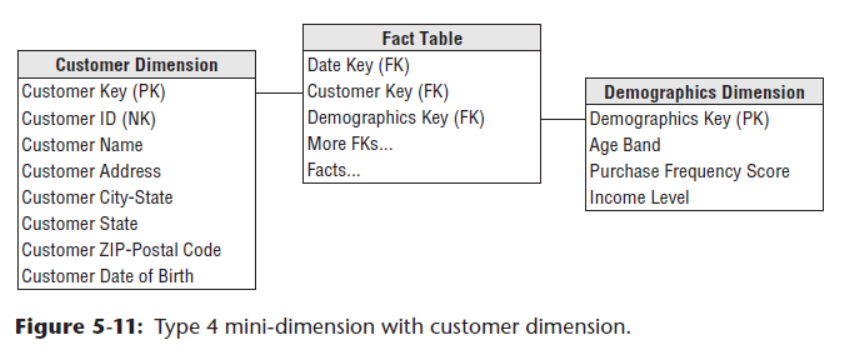
如果我们的表规模非常大,数据量千万以上,大量的列变化非常频繁,那么这时候就不能用上面的办法来支撑了,我们需要将那些快速变化的维度从原来的大维度表中拆分出来单独处理,是为微维度(mini-dimension)。
我们用书中的内容举例,如果顾客维度中有一部分人口统计学(demographic)维度是RCD,就将它们拆成单独的维度表:
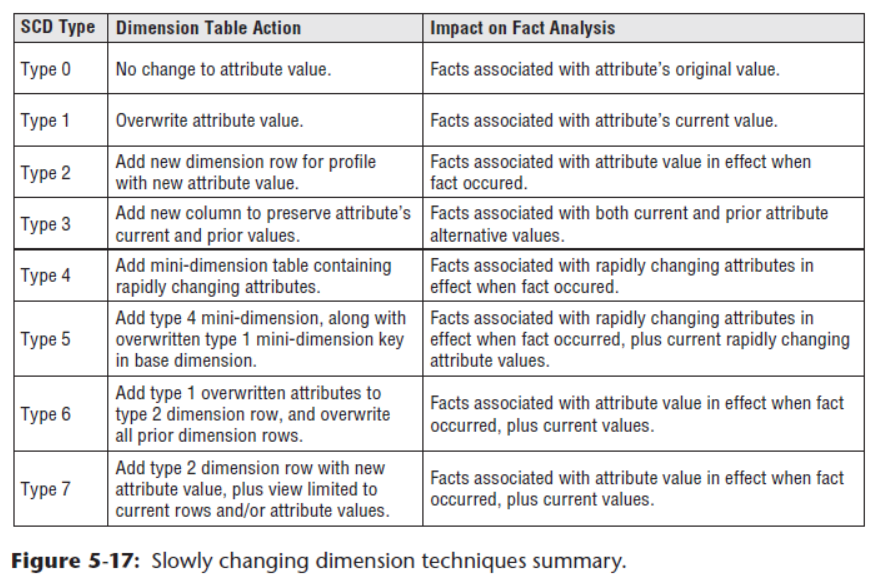
最后给出一张《The Data Warehouse Toolkit, 3rd Edition》中的这几种方式的比较图:


版权声明:
文章不错?点个【在看】吧! ?